 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Inspired Visual Pattern Recognition via Biological Reservoir Computing
Feb 05, 2026In this paper, we present a neuro-inspired approach to reservoir computing (RC) in which a network of in vitro cultured cortical neurons serves as the physical reservoir. Rather than relying on artificial recurrent models to approximate neural dynamics, our biological reservoir computing (BRC) system leverages the spontaneous and stimulus-evoked activity of living neural circuits as its computational substrate. A high-density multi-electrode array (HD-MEA) provides simultaneous stimulation and readout across hundreds of channels: input patterns are delivered through selected electrodes, while the remaining ones capture the resulting high-dimensional neural responses, yielding a biologically grounded feature representation. A linear readout layer (single-layer perceptron) is then trained to classify these reservoir states, enabling the living neural network to perform static visual pattern-recognition tasks within a computer-vision framework. We evaluate the system across a sequence of tasks of increasing difficulty, ranging from pointwise stimuli to oriented bars, clock-digit-like shapes, and handwritten digits from the MNIST dataset. Despite the inherent variability of biological neural responses-arising from noise, spontaneous activity, and inter-session differences-the system consistently generates high-dimensional representations that support accurate classification. These results demonstrate that in vitro cortical networks can function as effective reservoirs for static visual pattern recognition, opening new avenues for integrating living neural substrates into neuromorphic computing frameworks. More broadly, this work contributes to the effort to incorporate biological principles into machine learning and supports the goals of neuro-inspired vision by illustrating how living neural systems can inform the design of efficient and biologically grounded computational models.
From Neurons to Computation: Biological Reservoir Computing for Pattern Recognition
May 06, 2025In this paper, we introduce a novel paradigm for reservoir computing (RC) that leverages a pool of cultured biological neurons as the reservoir substrate, creating a biological reservoir computing (BRC). This system operates similarly to an echo state network (ESN), with the key distinction that the neural activity is generated by a network of cultured neurons, rather than being modeled by traditional artificial computational units. The neuronal activity is recorded using a multi-electrode array (MEA), which enables high-throughput recording of neural signals. In our approach, inputs are introduced into the network through a subset of the MEA electrodes, while the remaining electrodes capture the resulting neural activity. This generates a nonlinear mapping of the input data to a high-dimensional biological feature space, where distinguishing between data becomes more efficient and straightforward, allowing a simple linear classifier to perform pattern recognition tasks effectively. To evaluate the performance of our proposed system, we present an experimental study that includes various input patterns, such as positional codes, bars with different orientations, and a digit recognition task. The results demonstrate the feasibility of using biological neural networks to perform tasks traditionally handled by artificial neural networks, paving the way for further exploration of biologically-inspired computing systems, with potential applications in neuromorphic engineering and bio-hybrid computing.
Comparison of Different Deep Neural Network Models in the Cultural Heritage Domain
Apr 30, 2025The integration of computer vision and deep learning is an essential part of documenting and preserving cultural heritage, as well as improving visitor experiences. In recent years, two deep learning paradigms have been established in the field of computer vision: convolutional neural networks and transformer architectures. The present study aims to make a comparative analysis of some representatives of these two techniques of their ability to transfer knowledge from generic dataset, such as ImageNet, to cultural heritage specific tasks. The results of testing examples of the architectures VGG, ResNet, DenseNet, Visual Transformer, Swin Transformer, and PoolFormer, showed that DenseNet is the best in terms of efficiency-computability ratio.
CountingDINO: A Training-free Pipeline for Class-Agnostic Counting using Unsupervised Backbones
Apr 23, 2025Class-agnostic counting (CAC) aims to estimate the number of objects in images without being restricted to predefined categories. However, while current exemplar-based CAC methods offer flexibility at inference time, they still rely heavily on labeled data for training, which limits scalability and generalization to many downstream use cases. In this paper, we introduce CountingDINO, the first training-free exemplar-based CAC framework that exploits a fully unsupervised feature extractor. Specifically, our approach employs self-supervised vision-only backbones to extract object-aware features, and it eliminates the need for annotated data throughout the entire proposed pipeline. At inference time, we extract latent object prototypes via ROI-Align from DINO features and use them as convolutional kernels to generate similarity maps. These are then transformed into density maps through a simple yet effective normalization scheme. We evaluate our approach on the FSC-147 benchmark, where we outperform a baseline under the same label-free setting. Our method also achieves competitive -- and in some cases superior -- results compared to training-free approaches relying on supervised backbones, as well as several fully supervised state-of-the-art methods. This demonstrates that training-free CAC can be both scalable and competitive. Website: https://lorebianchi98.github.io/CountingDINO/
Semi-Supervised Biomedical Image Segmentation via Diffusion Models and Teacher-Student Co-Training
Apr 02, 2025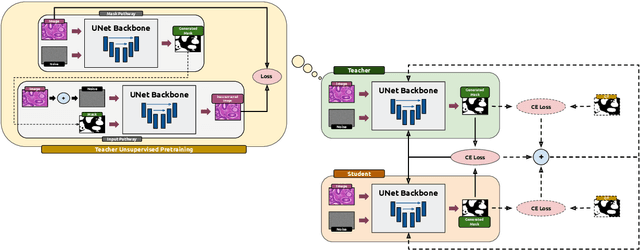
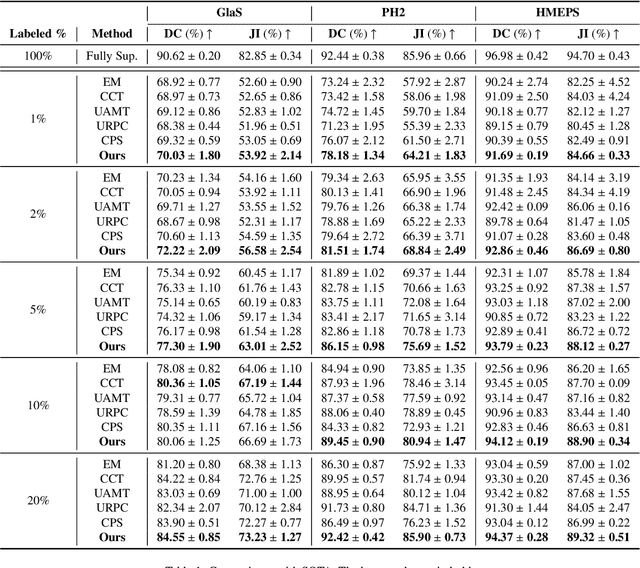
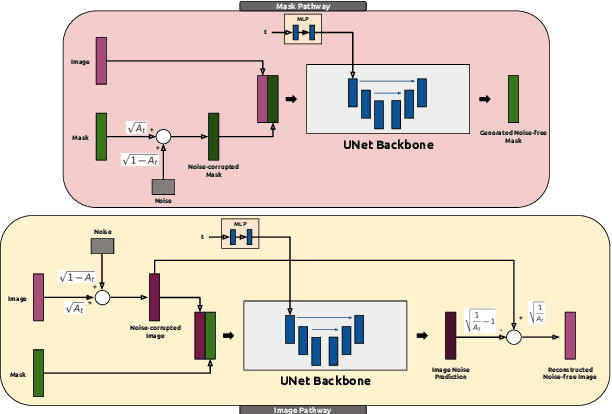
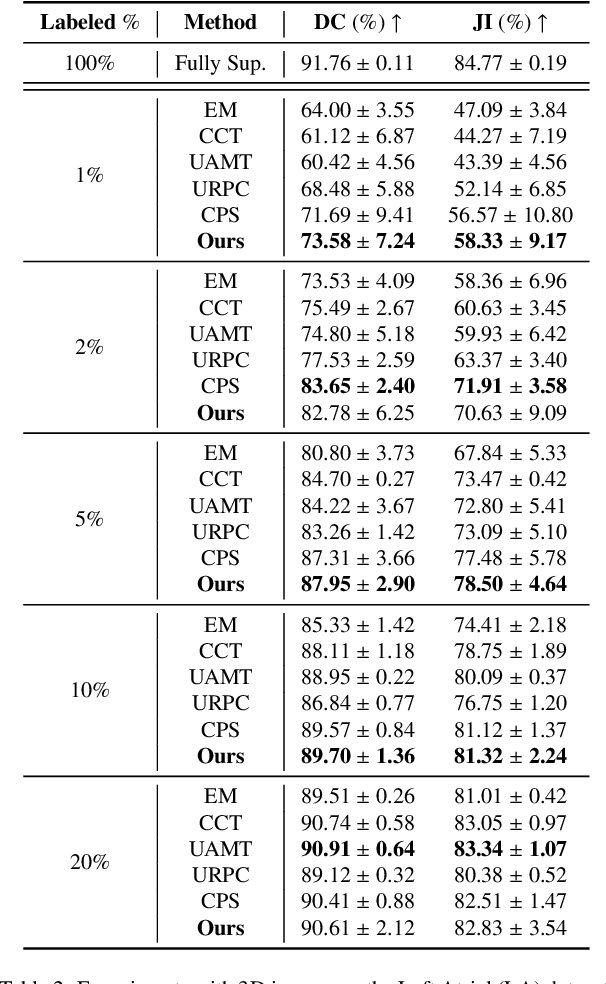
Supervised deep learning for semantic segmentation has achieved excellent results in accurately identifying anatomical and pathological structures in medical images. However, it often requires large annotated training datasets, which limits its scalability in clinical settings. To address this challenge, semi-supervised learning is a well-established approach that leverages both labeled and unlabeled data. In this paper, we introduce a novel semi-supervised teacher-student framework for biomedical image segmentation, inspired by the recent success of generative models. Our approach leverages denoising diffusion probabilistic models (DDPMs) to generate segmentation masks by progressively refining noisy inputs conditioned on the corresponding images. The teacher model is first trained in an unsupervised manner using a cycle-consistency constraint based on noise-corrupted image reconstruction, enabling it to generate informative semantic masks. Subsequently, the teacher is integrated into a co-training process with a twin-student network. The student learns from ground-truth labels when available and from teacher-generated pseudo-labels otherwise, while the teacher continuously improves its pseudo-labeling capabilities. Finally, to further enhance performance, we introduce a multi-round pseudo-label generation strategy that iteratively improves the pseudo-labeling process. We evaluate our approach on multiple biomedical imaging benchmarks, spanning multiple imaging modalities and segmentation tasks. Experimental results show that our method consistently outperforms state-of-the-art semi-supervised techniques, highlighting its effectiveness in scenarios with limited annotated data. The code to replicate our experiments can be found at https://github.com/ciampluca/diffusion_semi_supervised_biomedical_image_segmentation
A Survey on Class-Agnostic Counting: Advancements from Reference-Based to Open-World Text-Guided Approaches
Jan 31, 2025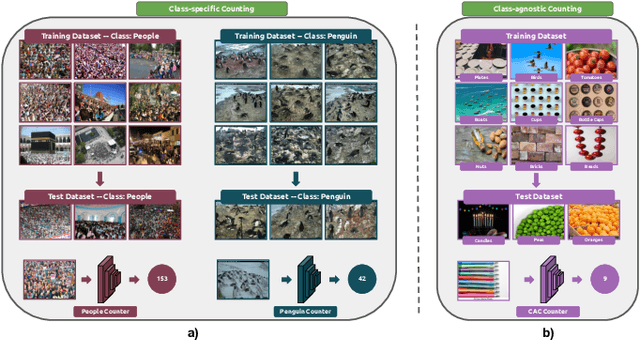

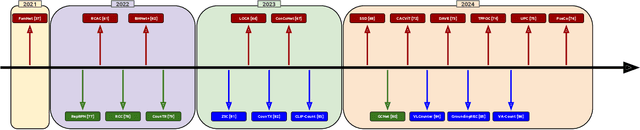

Object counting has recently shifted towards class-agnostic counting (CAC), which addresses the challenge of counting objects across arbitrary categories, tackling a critical need in versatile counting systems. While humans effortlessly identify and count objects from diverse categories without prior knowledge, most counting methods remain restricted to enumerating instances of known classes, requiring extensive labeled datasets for training, and struggling under open-vocabulary settings. Conversely, CAC aims to count objects belonging to classes never seen during training, typically operating in a few-shot setting. In this paper, for the first time, we review advancements in CAC methodologies, categorizing them into three paradigms based on how target object classes can be specified: reference-based, reference-less, and open-world text-guided. Reference-based approaches have set performance benchmarks using exemplar-guided mechanisms. Reference-less methods eliminate exemplar dependency by leveraging inherent image patterns. Finally, open-world text-guided methods utilize vision-language models, enabling object class descriptions through textual prompts, representing a flexible and appealing solution. We analyze state-of-the-art techniques and we report their results on existing gold standard benchmarks, comparing their performance and identifying and discussing their strengths and limitations. Persistent challenges -- such as annotation dependency, scalability, and generalization -- are discussed, alongside future directions. We believe this survey serves as a valuable resource for researchers to understand the progressive developments and contributions over time and the current state-of-the-art of CAC, suggesting insights for future directions and challenges to be addressed.
Biologically-inspired Semi-supervised Semantic Segmentation for Biomedical Imaging
Dec 04, 2024



We propose a novel two-stage semi-supervised learning approach for training downsampling-upsampling semantic segmentation architectures. The first stage does not use backpropagation. Rather, it exploits the bio-inspired Hebbian principle "fire together, wire together" as a local learning rule for updating the weights of both convolutional and transpose-convolutional layers, allowing unsupervised discovery of data features. In the second stage, the model is fine-tuned with standard backpropagation on a small subset of labeled data. We evaluate our methodology through experiments conducted on several widely used biomedical datasets, deeming that this domain is paramount in computer vision and is notably impacted by data scarcity. Results show that our proposed method outperforms SOTA approaches across different levels of label availability. Furthermore, we show that using our unsupervised stage to initialize the SOTA approaches leads to performance improvements. The code to replicate our experiments can be found at: https://github.com/ciampluca/hebbian-medical-image-segmentation
Mind the Prompt: A Novel Benchmark for Prompt-based Class-Agnostic Counting
Sep 24, 2024Class-agnostic counting (CAC) is a recent task in computer vision that aims to estimate the number of instances of arbitrary object classes never seen during model training. With the recent advancement of robust vision-and-language foundation models, there is a growing interest in prompt-based CAC, where object categories to be counted can be specified using natural language. However, we identify significant limitations in current benchmarks for evaluating this task, which hinder both accurate assessment and the development of more effective solutions. Specifically, we argue that the current evaluation protocols do not measure the ability of the model to understand which object has to be counted. This is due to two main factors: (i) the shortcomings of CAC datasets, which primarily consist of images containing objects from a single class, and (ii) the limitations of current counting performance evaluators, which are based on traditional class-specific counting and focus solely on counting errors. To fill this gap, we introduce the Prompt-Aware Counting (PrACo) benchmark, which comprises two targeted tests, each accompanied by appropriate evaluation metrics. We evaluate state-of-the-art methods and demonstrate that, although some achieve impressive results on standard class-specific counting metrics, they exhibit a significant deficiency in understanding the input prompt, indicating the need for more careful training procedures or revised designs. The code for reproducing our results is available at https://github.com/ciampluca/PrACo.
Development of a Realistic Crowd Simulation Environment for Fine-grained Validation of People Tracking Methods
Apr 26, 2023



Generally, crowd datasets can be collected or generated from real or synthetic sources. Real data is generated by using infrastructure-based sensors (such as static cameras or other sensors). The use of simulation tools can significantly reduce the time required to generate scenario-specific crowd datasets, facilitate data-driven research, and next build functional machine learning models. The main goal of this work was to develop an extension of crowd simulation (named CrowdSim2) and prove its usability in the application of people-tracking algorithms. The simulator is developed using the very popular Unity 3D engine with particular emphasis on the aspects of realism in the environment, weather conditions, traffic, and the movement and models of individual agents. Finally, three methods of tracking were used to validate generated dataset: IOU-Tracker, Deep-Sort, and Deep-TAMA.
CrowdSim2: an Open Synthetic Benchmark for Object Detectors
Apr 11, 2023Data scarcity has become one of the main obstacles to developing supervised models based on Artificial Intelligence in Computer Vision. Indeed, Deep Learning-based models systematically struggle when applied in new scenarios never seen during training and may not be adequately tested in non-ordinary yet crucial real-world situations. This paper presents and publicly releases CrowdSim2, a new synthetic collection of images suitable for people and vehicle detection gathered from a simulator based on the Unity graphical engine. It consists of thousands of images gathered from various synthetic scenarios resembling the real world, where we varied some factors of interest, such as the weather conditions and the number of objects in the scenes. The labels are automatically collected and consist of bounding boxes that precisely localize objects belonging to the two object classes, leaving out humans from the annotation pipeline. We exploited this new benchmark as a testing ground for some state-of-the-art detectors, showing that our simulated scenarios can be a valuable tool for measuring their performances in a controlled environment.