 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReviving ConvNeXt for Efficient Convolutional Diffusion Models
Mar 10, 2026Recent diffusion models increasingly favor Transformer backbones, motivated by the remarkable scalability of fully attentional architectures. Yet the locality bias, parameter efficiency, and hardware friendliness--the attributes that established ConvNets as the efficient vision backbone--have seen limited exploration in modern generative modeling. Here we introduce the fully convolutional diffusion model (FCDM), a model having a backbone similar to ConvNeXt, but designed for conditional diffusion modeling. We find that using only 50% of the FLOPs of DiT-XL/2, FCDM-XL achieves competitive performance with 7$\times$ and 7.5$\times$ fewer training steps at 256$\times$256 and 512$\times$512 resolutions, respectively. Remarkably, FCDM-XL can be trained on a 4-GPU system, highlighting the exceptional training efficiency of our architecture. Our results demonstrate that modern convolutional designs provide a competitive and highly efficient alternative for scaling diffusion models, reviving ConvNeXt as a simple yet powerful building block for efficient generative modeling.
ViSketch-GPT: Collaborative Multi-Scale Feature Extraction for Sketch Recognition and Generation
Mar 28, 2025Understanding the nature of human sketches is challenging because of the wide variation in how they are created. Recognizing complex structural patterns improves both the accuracy in recognizing sketches and the fidelity of the generated sketches. In this work, we introduce ViSketch-GPT, a novel algorithm designed to address these challenges through a multi-scale context extraction approach. The model captures intricate details at multiple scales and combines them using an ensemble-like mechanism, where the extracted features work collaboratively to enhance the recognition and generation of key details crucial for classification and generation tasks. The effectiveness of ViSketch-GPT is validated through extensive experiments on the QuickDraw dataset. Our model establishes a new benchmark, significantly outperforming existing methods in both classification and generation tasks, with substantial improvements in accuracy and the fidelity of generated sketches. The proposed algorithm offers a robust framework for understanding complex structures by extracting features that collaborate to recognize intricate details, enhancing the understanding of structures like sketches and making it a versatile tool for various applications in computer vision and machine learning.
Maybe you are looking for CroQS: Cross-modal Query Suggestion for Text-to-Image Retrieval
Dec 18, 2024
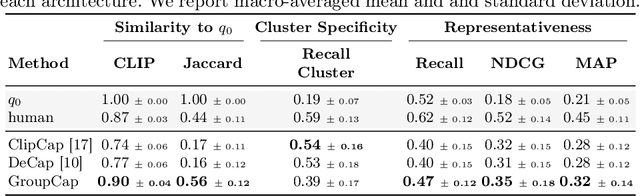

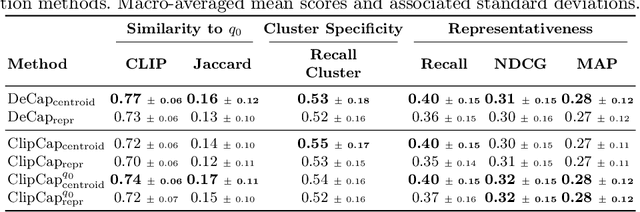
Query suggestion, a technique widely adopted in information retrieval, enhances system interactivity and the browsing experience of document collections. In cross-modal retrieval, many works have focused on retrieving relevant items from natural language queries, while few have explored query suggestion solutions. In this work, we address query suggestion in cross-modal retrieval, introducing a novel task that focuses on suggesting minimal textual modifications needed to explore visually consistent subsets of the collection, following the premise of ''Maybe you are looking for''. To facilitate the evaluation and development of methods, we present a tailored benchmark named CroQS. This dataset comprises initial queries, grouped result sets, and human-defined suggested queries for each group. We establish dedicated metrics to rigorously evaluate the performance of various methods on this task, measuring representativeness, cluster specificity, and similarity of the suggested queries to the original ones. Baseline methods from related fields, such as image captioning and content summarization, are adapted for this task to provide reference performance scores. Although relatively far from human performance, our experiments reveal that both LLM-based and captioning-based methods achieve competitive results on CroQS, improving the recall on cluster specificity by more than 115% and representativeness mAP by more than 52% with respect to the initial query. The dataset, the implementation of the baseline methods and the notebooks containing our experiments are available here: https://paciosoft.com/CroQS-benchmark/
Talking to DINO: Bridging Self-Supervised Vision Backbones with Language for Open-Vocabulary Segmentation
Nov 28, 2024



Open-Vocabulary Segmentation (OVS) aims at segmenting images from free-form textual concepts without predefined training classes. While existing vision-language models such as CLIP can generate segmentation masks by leveraging coarse spatial information from Vision Transformers, they face challenges in spatial localization due to their global alignment of image and text features. Conversely, self-supervised visual models like DINO excel in fine-grained visual encoding but lack integration with language. To bridge this gap, we present Talk2DINO, a novel hybrid approach that combines the spatial accuracy of DINOv2 with the language understanding of CLIP. Our approach aligns the textual embeddings of CLIP to the patch-level features of DINOv2 through a learned mapping function without the need to fine-tune the underlying backbones. At training time, we exploit the attention maps of DINOv2 to selectively align local visual patches with textual embeddings. We show that the powerful semantic and localization abilities of Talk2DINO can enhance the segmentation process, resulting in more natural and less noisy segmentations, and that our approach can also effectively distinguish foreground objects from the background. Experimental results demonstrate that Talk2DINO achieves state-of-the-art performance across several unsupervised OVS benchmarks. Source code and models are publicly available at: https://lorebianchi98.github.io/Talk2DINO/.
Is CLIP the main roadblock for fine-grained open-world perception?
Apr 04, 2024



Modern applications increasingly demand flexible computer vision models that adapt to novel concepts not encountered during training. This necessity is pivotal in emerging domains like extended reality, robotics, and autonomous driving, which require the ability to respond to open-world stimuli. A key ingredient is the ability to identify objects based on free-form textual queries defined at inference time - a task known as open-vocabulary object detection. Multimodal backbones like CLIP are the main enabling technology for current open-world perception solutions. Despite performing well on generic queries, recent studies highlighted limitations on the fine-grained recognition capabilities in open-vocabulary settings - i.e., for distinguishing subtle object features like color, shape, and material. In this paper, we perform a detailed examination of these open-vocabulary object recognition limitations to find the root cause. We evaluate the performance of CLIP, the most commonly used vision-language backbone, against a fine-grained object-matching benchmark, revealing interesting analogies between the limitations of open-vocabulary object detectors and their backbones. Experiments suggest that the lack of fine-grained understanding is caused by the poor separability of object characteristics in the CLIP latent space. Therefore, we try to understand whether fine-grained knowledge is present in CLIP embeddings but not exploited at inference time due, for example, to the unsuitability of the cosine similarity matching function, which may discard important object characteristics. Our preliminary experiments show that simple CLIP latent-space re-projections help separate fine-grained concepts, paving the way towards the development of backbones inherently able to process fine-grained details. The code for reproducing these experiments is available at https://github.com/lorebianchi98/FG-CLIP.
The devil is in the fine-grained details: Evaluating open-vocabulary object detectors for fine-grained understanding
Nov 29, 2023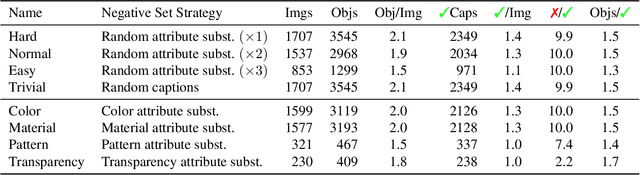


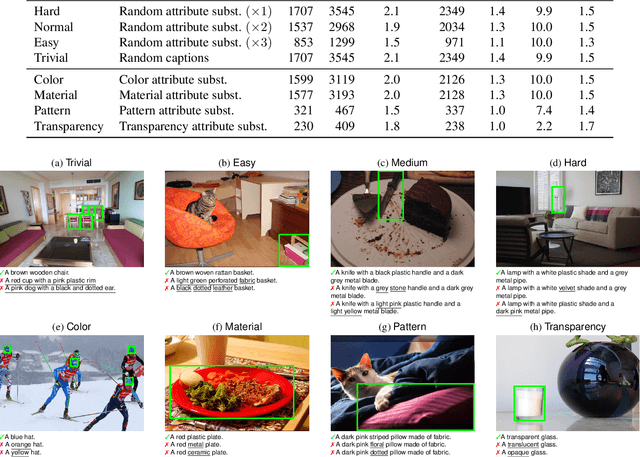
Recent advancements in large vision-language models enabled visual object detection in open-vocabulary scenarios, where object classes are defined in free-text formats during inference. In this paper, we aim to probe the state-of-the-art methods for open-vocabulary object detection to determine to what extent they understand fine-grained properties of objects and their parts. To this end, we introduce an evaluation protocol based on dynamic vocabulary generation to test whether models detect, discern, and assign the correct fine-grained description to objects in the presence of hard-negative classes. We contribute with a benchmark suite of increasing difficulty and probing different properties like color, pattern, and material. We further enhance our investigation by evaluating several state-of-the-art open-vocabulary object detectors using the proposed protocol and find that most existing solutions, which shine in standard open-vocabulary benchmarks, struggle to accurately capture and distinguish finer object details. We conclude the paper by highlighting the limitations of current methodologies and exploring promising research directions to overcome the discovered drawbacks. Data and code are available at https://github.com/lorebianchi98/FG-OVD.
The Emotions of the Crowd: Learning Image Sentiment from Tweets via Cross-modal Distillation
Apr 28, 2023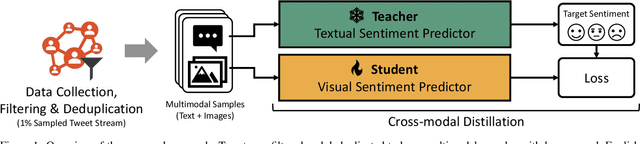



Trends and opinion mining in social media increasingly focus on novel interactions involving visual media, like images and short videos, in addition to text. In this work, we tackle the problem of visual sentiment analysis of social media images -- specifically, the prediction of image sentiment polarity. While previous work relied on manually labeled training sets, we propose an automated approach for building sentiment polarity classifiers based on a cross-modal distillation paradigm; starting from scraped multimodal (text + images) data, we train a student model on the visual modality based on the outputs of a textual teacher model that analyses the sentiment of the corresponding textual modality. We applied our method to randomly collected images crawled from Twitter over three months and produced, after automatic cleaning, a weakly-labeled dataset of $\sim$1.5 million images. Despite exploiting noisy labeled samples, our training pipeline produces classifiers showing strong generalization capabilities and outperforming the current state of the art on five manually labeled benchmarks for image sentiment polarity prediction.
Deep learning for structural health monitoring: An application to heritage structures
Nov 04, 2022

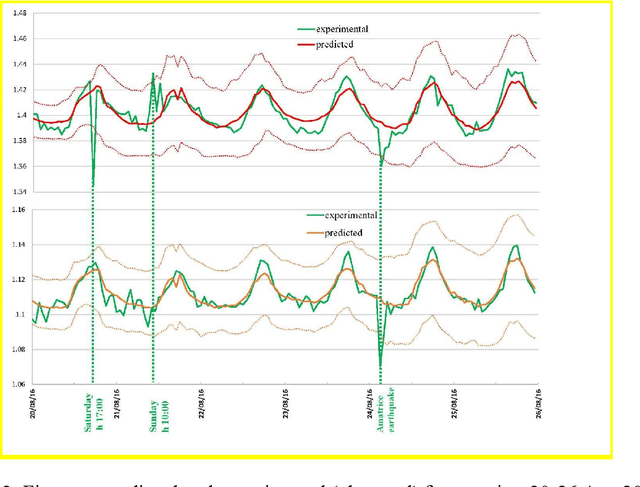
Thanks to recent advancements in numerical methods, computer power, and monitoring technology, seismic ambient noise provides precious information about the structural behavior of old buildings. The measurement of the vibrations produced by anthropic and environmental sources and their use for dynamic identification and structural health monitoring of buildings initiated an emerging, cross-disciplinary field engaging seismologists, engineers, mathematicians, and computer scientists. In this work, we employ recent deep learning techniques for time-series forecasting to inspect and detect anomalies in the large dataset recorded during a long-term monitoring campaign conducted on the San Frediano bell tower in Lucca. We frame the problem as an unsupervised anomaly detection task and train a Temporal Fusion Transformer to learn the normal dynamics of the structure. We then detect the anomalies by looking at the differences between the predicted and observed frequencies.
Recurrent Vision Transformer for Solving Visual Reasoning Problems
Nov 29, 2021
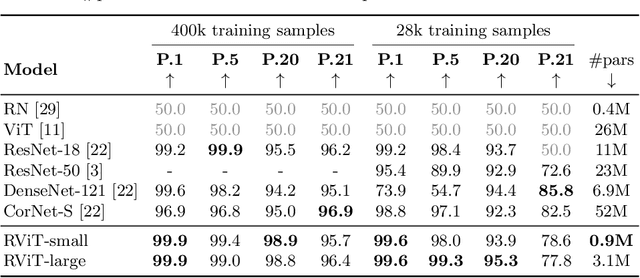
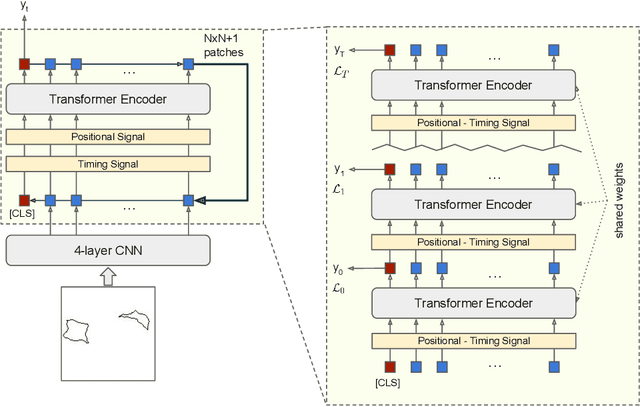
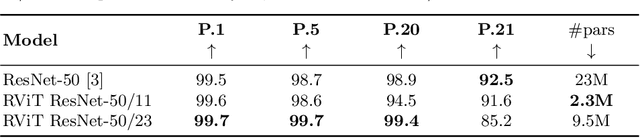
Although convolutional neural networks (CNNs) showed remarkable results in many vision tasks, they are still strained by simple yet challenging visual reasoning problems. Inspired by the recent success of the Transformer network in computer vision, in this paper, we introduce the Recurrent Vision Transformer (RViT) model. Thanks to the impact of recurrent connections and spatial attention in reasoning tasks, this network achieves competitive results on the same-different visual reasoning problems from the SVRT dataset. The weight-sharing both in spatial and depth dimensions regularizes the model, allowing it to learn using far fewer free parameters, using only 28k training samples. A comprehensive ablation study confirms the importance of a hybrid CNN + Transformer architecture and the role of the feedback connections, which iteratively refine the internal representation until a stable prediction is obtained. In the end, this study can lay the basis for a deeper understanding of the role of attention and recurrent connections for solving visual abstract reasoning tasks.
Multi-Camera Vehicle Counting Using Edge-AI
Jun 05, 2021



This paper presents a novel solution to automatically count vehicles in a parking lot using images captured by smart cameras. Unlike most of the literature on this task, which focuses on the analysis of single images, this paper proposes the use of multiple visual sources to monitor a wider parking area from different perspectives. The proposed multi-camera system is capable of automatically estimate the number of cars present in the entire parking lot directly on board the edge devices. It comprises an on-device deep learning-based detector that locates and counts the vehicles from the captured images and a decentralized geometric-based approach that can analyze the inter-camera shared areas and merge the data acquired by all the devices. We conduct the experimental evaluation on an extended version of the CNRPark-EXT dataset, a collection of images taken from the parking lot on the campus of the National Research Council (CNR) in Pisa, Italy. We show that our system is robust and takes advantage of the redundant information deriving from the different cameras, improving the overall performance without requiring any extra geometrical information of the monitored scene.