 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Coordinated Online Behavior: Trade-offs and Strategies
Jul 16, 2025Coordinated online behavior, which spans from beneficial collective actions to harmful manipulation such as disinformation campaigns, has become a key focus in digital ecosystem analysis. Traditional methods often rely on monomodal approaches, focusing on single types of interactions like co-retweets or co-hashtags, or consider multiple modalities independently of each other. However, these approaches may overlook the complex dynamics inherent in multimodal coordination. This study compares different ways of operationalizing the detection of multimodal coordinated behavior. It examines the trade-off between weakly and strongly integrated multimodal models, highlighting the balance between capturing broader coordination patterns and identifying tightly coordinated behavior. By comparing monomodal and multimodal approaches, we assess the unique contributions of different data modalities and explore how varying implementations of multimodality impact detection outcomes. Our findings reveal that not all the modalities provide distinct insights, but that with a multimodal approach we can get a more comprehensive understanding of coordination dynamics. This work enhances the ability to detect and analyze coordinated online behavior, offering new perspectives for safeguarding the integrity of digital platforms.
Mapping the Italian Telegram Ecosystem
Apr 28, 2025Telegram has become a major space for political discourse and alternative media. However, its lack of moderation allows misinformation, extremism, and toxicity to spread. While prior research focused on these particular phenomena or topics, these have mostly been examined separately, and a broader understanding of the Telegram ecosystem is still missing. In this work, we fill this gap by conducting a large-scale analysis of the Italian Telegram sphere, leveraging a dataset of 186 million messages from 13,151 chats collected in 2023. Using network analysis, Large Language Models, and toxicity detection tools, we examine how different thematic communities form, align ideologically, and engage in harmful discourse within the Italian cultural context. Results show strong thematic and ideological homophily. We also identify mixed ideological communities where far-left and far-right rhetoric coexist on particular geopolitical issues. Beyond political analysis, we find that toxicity, rather than being isolated in a few extreme chats, appears widely normalized within highly toxic communities. Moreover, we find that Italian discourse primarily targets Black people, Jews, and gay individuals independently of the topic. Finally, we uncover common trend of intra-national hostility, where Italians often attack other Italians, reflecting regional and intra-regional cultural conflicts that can be traced back to old historical divisions. This study provides the first large-scale mapping of the Italian Telegram ecosystem, offering insights into ideological interactions, toxicity, and identity-targets of hate and contributing to research on online toxicity across different cultural and linguistic contexts on Telegram.
Geo-Semantic-Parsing: AI-powered geoparsing by traversing semantic knowledge graphs
Mar 03, 2025Online social networks convey rich information about geospatial facets of reality. However in most cases, geographic information is not explicit and structured, thus preventing its exploitation in real-time applications. We address this limitation by introducing a novel geoparsing and geotagging technique called Geo-Semantic-Parsing (GSP). GSP identifies location references in free text and extracts the corresponding geographic coordinates. To reach this goal, we employ a semantic annotator to identify relevant portions of the input text and to link them to the corresponding entity in a knowledge graph. Then, we devise and experiment with several efficient strategies for traversing the knowledge graph, thus expanding the available set of information for the geoparsing task. Finally, we exploit all available information for learning a regression model that selects the best entity with which to geotag the input text. We evaluate GSP on a well-known reference dataset including almost 10k event-related tweets, achieving $F1=0.66$. We extensively compare our results with those of 2 baselines and 3 state-of-the-art geoparsing techniques, achieving the best performance. On the same dataset, competitors obtain $F1 \leq 0.55$. We conclude by providing in-depth analyses of our results, showing that the overall superior performance of GSP is mainly due to a large improvement in recall, with respect to existing techniques.
* Postprint of the article published in the Decision Support Systems journal. Please, cite accordingly
Detection and Characterization of Coordinated Online Behavior: A Survey
Aug 02, 2024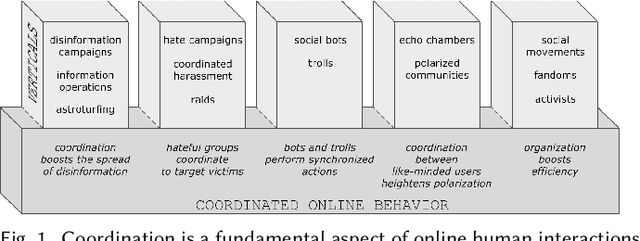

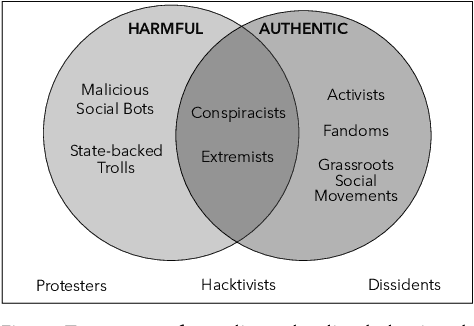
Coordination is a fundamental aspect of life. The advent of social media has made it integral also to online human interactions, such as those that characterize thriving online communities and social movements. At the same time, coordination is also core to effective disinformation, manipulation, and hate campaigns. This survey collects, categorizes, and critically discusses the body of work produced as a result of the growing interest on coordinated online behavior. We reconcile industry and academic definitions, propose a comprehensive framework to study coordinated online behavior, and review and critically discuss the existing detection and characterization methods. Our analysis identifies open challenges and promising directions of research, serving as a guide for scholars, practitioners, and policymakers in understanding and addressing the complexities inherent to online coordination.
The Anatomy of Conspirators: Unveiling Traits using a Comprehensive Twitter Dataset
Aug 29, 2023
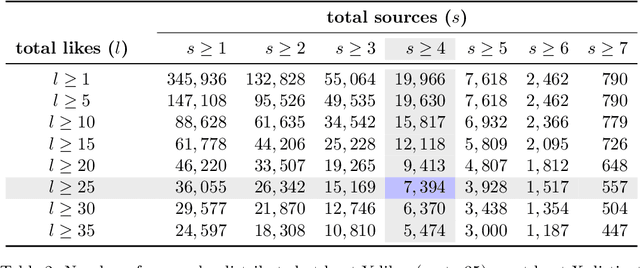

The discourse around conspiracy theories is currently thriving amidst the rampant misinformation prevalent in online environments. Research in this field has been focused on detecting conspiracy theories on social media, often relying on limited datasets. In this study, we present a novel methodology for constructing a Twitter dataset that encompasses accounts engaged in conspiracy-related activities throughout the year 2022. Our approach centers on data collection that is independent of specific conspiracy theories and information operations. Additionally, our dataset includes a control group comprising randomly selected users who can be fairly compared to the individuals involved in conspiracy activities. This comprehensive collection effort yielded a total of 15K accounts and 37M tweets extracted from their timelines. We conduct a comparative analysis of the two groups across three dimensions: topics, profiles, and behavioral characteristics. The results indicate that conspiracy and control users exhibit similarity in terms of their profile metadata characteristics. However, they diverge significantly in terms of behavior and activity, particularly regarding the discussed topics, the terminology used, and their stance on trending subjects. Interestingly, there is no significant disparity in the presence of bot users between the two groups, suggesting that conspiracy and automation are orthogonal concepts. Finally, we develop a classifier to identify conspiracy users using 93 features, some of which are commonly employed in literature for troll identification. The results demonstrate a high accuracy level (with an average F1 score of 0.98%), enabling us to uncover the most discriminative features associated with conspiracy-related accounts.
The Emotions of the Crowd: Learning Image Sentiment from Tweets via Cross-modal Distillation
Apr 28, 2023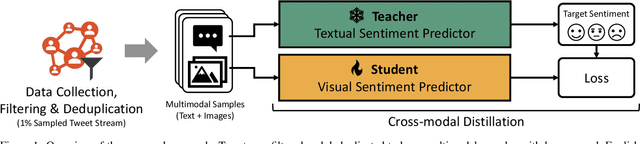



Trends and opinion mining in social media increasingly focus on novel interactions involving visual media, like images and short videos, in addition to text. In this work, we tackle the problem of visual sentiment analysis of social media images -- specifically, the prediction of image sentiment polarity. While previous work relied on manually labeled training sets, we propose an automated approach for building sentiment polarity classifiers based on a cross-modal distillation paradigm; starting from scraped multimodal (text + images) data, we train a student model on the visual modality based on the outputs of a textual teacher model that analyses the sentiment of the corresponding textual modality. We applied our method to randomly collected images crawled from Twitter over three months and produced, after automatic cleaning, a weakly-labeled dataset of $\sim$1.5 million images. Despite exploiting noisy labeled samples, our training pipeline produces classifiers showing strong generalization capabilities and outperforming the current state of the art on five manually labeled benchmarks for image sentiment polarity prediction.
Demystifying Misconceptions in Social Bots Research
Mar 30, 2023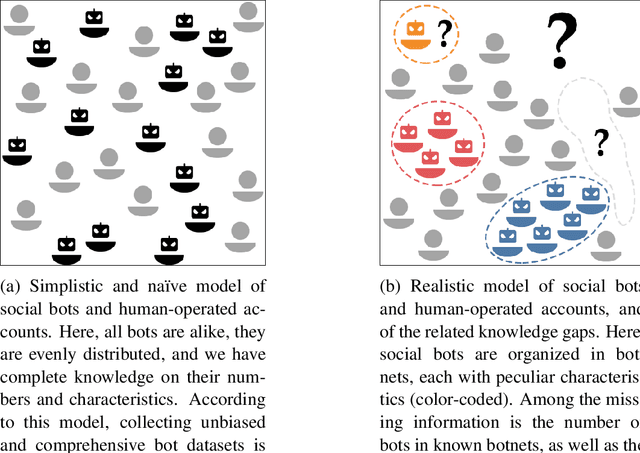
The science of social bots seeks knowledge and solutions to one of the most debated forms of online misinformation. Yet, social bots research is plagued by widespread biases, hyped results, and misconceptions that set the stage for ambiguities, unrealistic expectations, and seemingly irreconcilable findings. Overcoming such issues is instrumental towards ensuring reliable solutions and reaffirming the validity of the scientific method. In this contribution we revise some recent results in social bots research, highlighting and correcting factual errors as well as methodological and conceptual issues. More importantly, we demystify common misconceptions, addressing fundamental points on how social bots research is discussed. Our analysis surfaces the need to discuss misinformation research in a rigorous, unbiased, and responsible way. This article bolsters such effort by identifying and refuting common fallacious arguments used by both proponents and opponents of social bots research as well as providing indications on the correct methodologies and sound directions for future research in the field.
Modularity-based approach for tracking communities in dynamic social networks
Feb 24, 2023Community detection is a fundamental task in social network analysis. Online social networks have dramatically increased the volume and speed of interactions among users, enabling advanced analysis of these dynamics. Despite a growing interest in tracking the evolution of groups of users in real-world social networks, most community detection efforts focus on communities within static networks. Here, we describe a framework for tracking communities over time in a dynamic network, where a series of significant events is identified for each community. To this end, a modularity-based strategy is proposed to effectively detect and track dynamic communities. The potential of our framework is shown by conducting extensive experiments on synthetic networks containing embedded events. Results indicate that our framework outperforms other state-of-the-art methods. In addition, we briefly explore how the proposed approach can identify dynamic communities in a Twitter network composed of more than 60,000 users, which posted over 5 million tweets throughout 2020. The proposed framework can be applied to different social network and provides a valuable tool to understand the evolution of communities in dynamic social networks.
Temporal Dynamics of Coordinated Online Behavior: Stability, Archetypes, and Influence
Jan 17, 2023
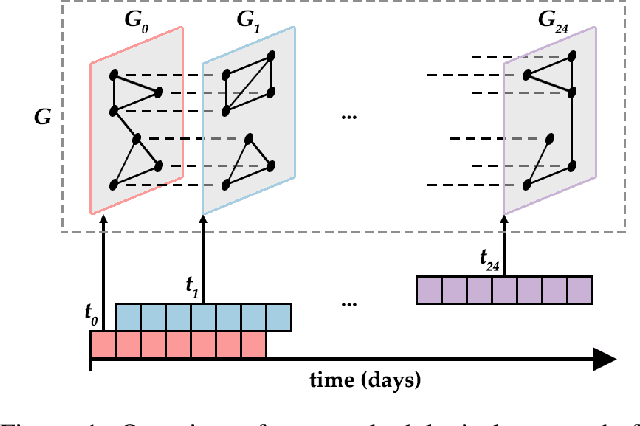


Large-scale online campaigns, malicious or otherwise, require a significant degree of coordination among participants, which sparked interest in the study of coordinated online behavior. State-of-the-art methods for detecting coordinated behavior perform static analyses, disregarding the temporal dynamics of coordination. Here, we carry out the first dynamic analysis of coordinated behavior. To reach our goal we build a multiplex temporal network and we perform dynamic community detection to identify groups of users that exhibited coordinated behaviors in time. Thanks to our novel approach we find that: (i) coordinated communities feature variable degrees of temporal instability; (ii) dynamic analyses are needed to account for such instability, and results of static analyses can be unreliable and scarcely representative of unstable communities; (iii) some users exhibit distinct archetypal behaviors that have important practical implications; (iv) content and network characteristics contribute to explaining why users leave and join coordinated communities. Our results demonstrate the advantages of dynamic analyses and open up new directions of research on the unfolding of online debates, on the strategies of coordinated communities, and on the patterns of online influence.
MulBot: Unsupervised Bot Detection Based on Multivariate Time Series
Sep 21, 2022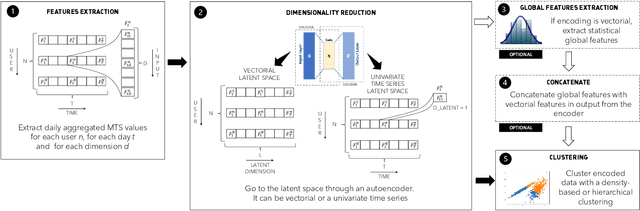

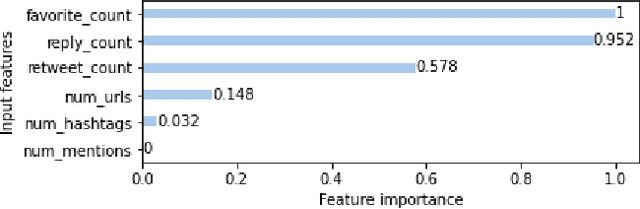

Online social networks are actively involved in the removal of malicious social bots due to their role in the spread of low quality information. However, most of the existing bot detectors are supervised classifiers incapable of capturing the evolving behavior of sophisticated bots. Here we propose MulBot, an unsupervised bot detector based on multivariate time series (MTS). For the first time, we exploit multidimensional temporal features extracted from user timelines. We manage the multidimensionality with an LSTM autoencoder, which projects the MTS in a suitable latent space. Then, we perform a clustering step on this encoded representation to identify dense groups of very similar users -- a known sign of automation. Finally, we perform a binary classification task achieving f1-score $= 0.99$, outperforming state-of-the-art methods (f1-score $\le 0.97$). Not only does MulBot achieve excellent results in the binary classification task, but we also demonstrate its strengths in a novel and practically-relevant task: detecting and separating different botnets. In this multi-class classification task we achieve f1-score $= 0.96$. We conclude by estimating the importance of the different features used in our model and by evaluating MulBot's capability to generalize to new unseen bots, thus proposing a solution to the generalization deficiencies of supervised bot detectors.