 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Anatomy of Conspirators: Unveiling Traits using a Comprehensive Twitter Dataset
Aug 29, 2023
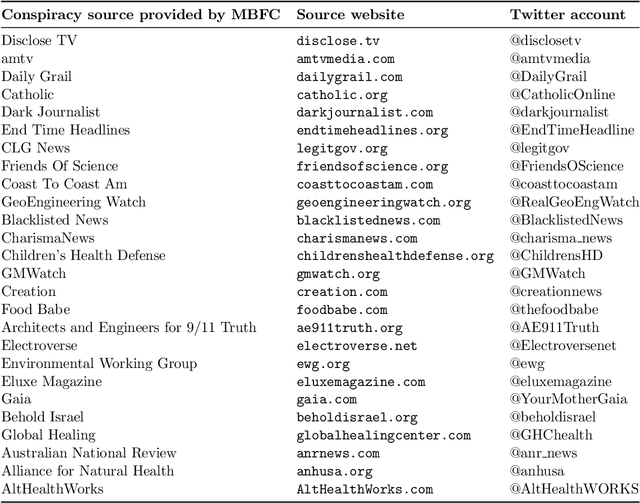
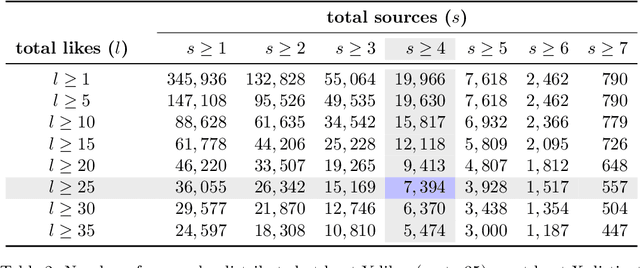

The discourse around conspiracy theories is currently thriving amidst the rampant misinformation prevalent in online environments. Research in this field has been focused on detecting conspiracy theories on social media, often relying on limited datasets. In this study, we present a novel methodology for constructing a Twitter dataset that encompasses accounts engaged in conspiracy-related activities throughout the year 2022. Our approach centers on data collection that is independent of specific conspiracy theories and information operations. Additionally, our dataset includes a control group comprising randomly selected users who can be fairly compared to the individuals involved in conspiracy activities. This comprehensive collection effort yielded a total of 15K accounts and 37M tweets extracted from their timelines. We conduct a comparative analysis of the two groups across three dimensions: topics, profiles, and behavioral characteristics. The results indicate that conspiracy and control users exhibit similarity in terms of their profile metadata characteristics. However, they diverge significantly in terms of behavior and activity, particularly regarding the discussed topics, the terminology used, and their stance on trending subjects. Interestingly, there is no significant disparity in the presence of bot users between the two groups, suggesting that conspiracy and automation are orthogonal concepts. Finally, we develop a classifier to identify conspiracy users using 93 features, some of which are commonly employed in literature for troll identification. The results demonstrate a high accuracy level (with an average F1 score of 0.98%), enabling us to uncover the most discriminative features associated with conspiracy-related accounts.
Tweets2Stance: Users stance detection exploiting Zero-Shot Learning Algorithms on Tweets
Apr 22, 2022


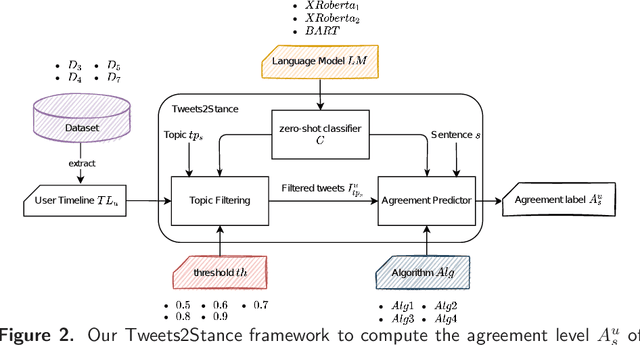
In the last years there has been a growing attention towards predicting the political orientation of active social media users, being this of great help to study political forecasts, opinion dynamics modeling and users polarization. Existing approaches, mainly targeting Twitter users, rely on content-based analysis or are based on a mixture of content, network and communication analysis. The recent research perspective exploits the fact that a user's political affinity mainly depends on his/her positions on major political and social issues, thus shifting the focus on detecting the stance of users through user-generated content shared on social networks. The work herein described focuses on a completely unsupervised stance detection framework that predicts the user's stance about specific social-political statements by exploiting content-based analysis of its Twitter timeline. The ground-truth user's stance may come from Voting Advice Applications, online tools that help citizens to identify their political leanings by comparing their political preferences with party political stances. Starting from the knowledge of the agreement level of six parties on 20 different statements, the objective of the study is to predict the stance of a Party p in regard to each statement s exploiting what the Twitter Party account wrote on Twitter. To this end we propose Tweets2Stance (T2S), a novel and totally unsupervised stance detector framework which relies on the zero-shot learning technique to quickly and accurately operate on non-labeled data. Interestingly, T2S can be applied to any social media user for any context of interest, not limited to the political one. Results obtained from multiple experiments show that, although the general maximum F1 value is 0.4, T2S can correctly predict the stance with a general minimum MAE of 1.13, which is a great achievement considering the task complexity.
TweepFake: about Detecting Deepfake Tweets
Jul 31, 2020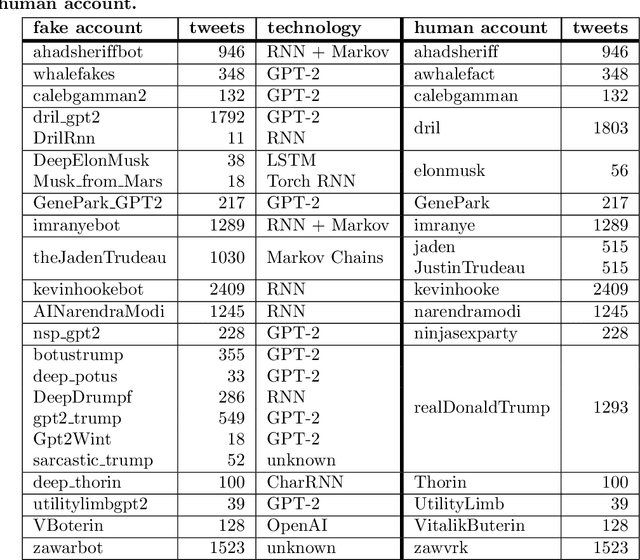
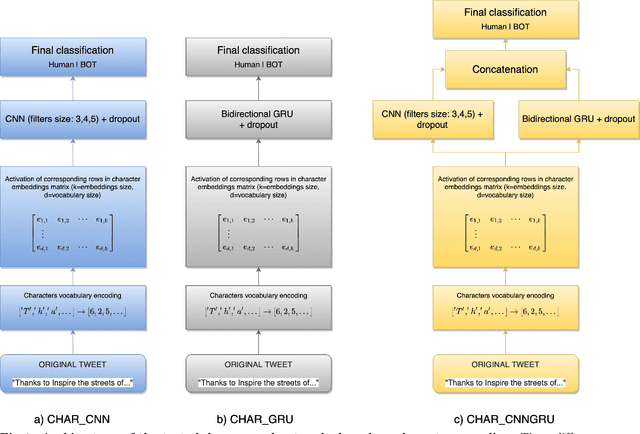

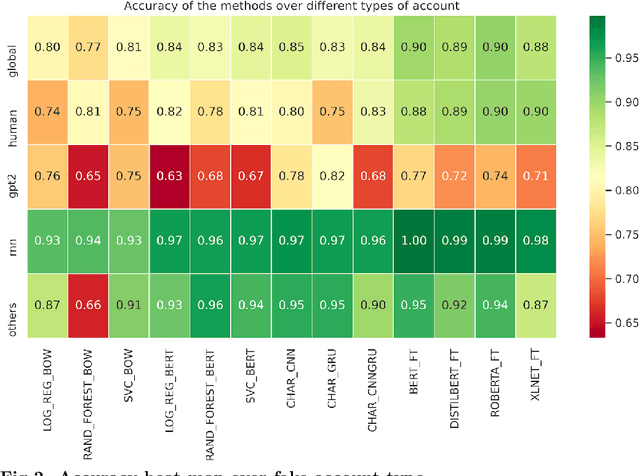
The threat of deepfakes, synthetic, or manipulated media, is becoming increasingly alarming, especially for social media platforms that have already been accused of manipulating public opinion. Even the cheapest text generation techniques (e.g. the search-and-replace method) can deceive humans, as the Net Neutrality scandal proved in 2017. Meanwhile, more powerful generative models have been released, from RNN-based methods to the GPT-2 language model. State-of-the-art language models, transformer-based in particular, can generate synthetic text in response to the model being primed with arbitrary input. Thus, Therefore, it is crucial to develop tools that help to detect media authenticity. To help the research in this field, we collected a dataset of real Deepfake tweets. It is real in the sense that each deepfake tweet was actually posted on Twitter. We collected tweets from a total of 23 bots, imitating 17 human accounts. The bots are based on various generation techniques, i.e., Markov Chains, RNN, RNN+Markov, LSTM, GPT-2. We also randomly selected tweets from the humans imitated by the bots to have an overall balanced dataset of 25,836 tweets (half human and half bots generated). The dataset is publicly available on Kaggle. In order to create a solid baseline for detection techniques on the proposed dataset we tested 13 detection methods based on various state-of-the-art approaches. The detection results reported as a baseline using 13 detection methods, confirm that the newest and more sophisticated generative methods based on transformer architecture (e.g., GPT-2) can produce high-quality short texts, difficult to detect.