 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBotVerse: Real-Time Event-Driven Simulation of Social Agents
Mar 31, 2026BotVerse is a scalable, event-driven framework for high-fidelity social simulation using LLM-based agents. It addresses the ethical risks of studying autonomous agents on live networks by isolating interactions within a controlled environment while grounding them in real-time content streams from the Bluesky ecosystem. The system features an asynchronous orchestration API and a simulation engine that emulates human-like temporal patterns and cognitive memory. Through the Synthetic Social Observatory, researchers can deploy customizable personas and observe multimodal interactions at scale. We demonstrate BotVersevia a coordinated disinformation scenario, providing a safe, experimental framework for red-teaming and computational social scientists. A video demonstration of the framework is available at https://youtu.be/eZSzO5Jarqk.
On the efficacy of old features for the detection of new bots
Jun 24, 2025
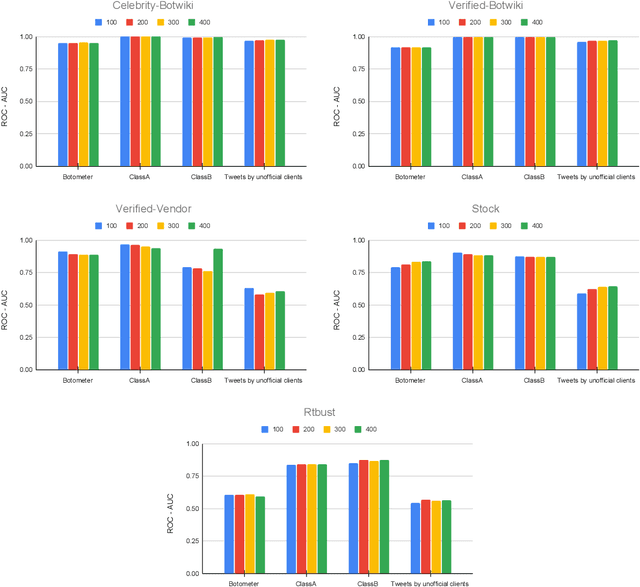
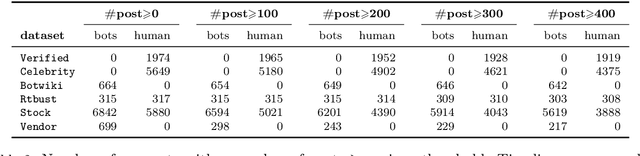

For more than a decade now, academicians and online platform administrators have been studying solutions to the problem of bot detection. Bots are computer algorithms whose use is far from being benign: malicious bots are purposely created to distribute spam, sponsor public characters and, ultimately, induce a bias within the public opinion. To fight the bot invasion on our online ecosystem, several approaches have been implemented, mostly based on (supervised and unsupervised) classifiers, which adopt the most varied account features, from the simplest to the most expensive ones to be extracted from the raw data obtainable through the Twitter public APIs. In this exploratory study, using Twitter as a benchmark, we compare the performances of four state-of-art feature sets in detecting novel bots: one of the output scores of the popular bot detector Botometer, which considers more than 1,000 features of an account to take a decision; two feature sets based on the account profile and timeline; and the information about the Twitter client from which the user tweets. The results of our analysis, conducted on six recently released datasets of Twitter accounts, hint at the possible use of general-purpose classifiers and cheap-to-compute account features for the detection of evolved bots.
* pre-print version
Evaluating Trustworthiness of Online News Publishers via Article Classification
Jan 03, 2024
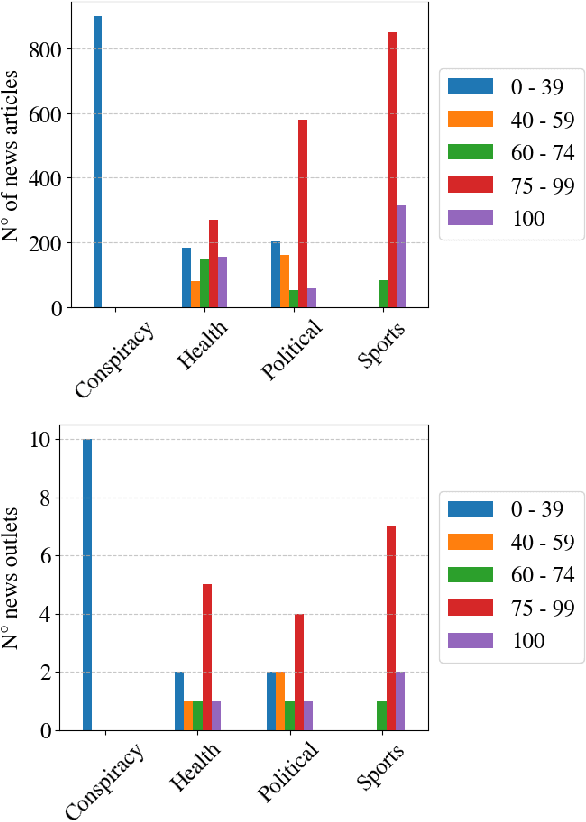

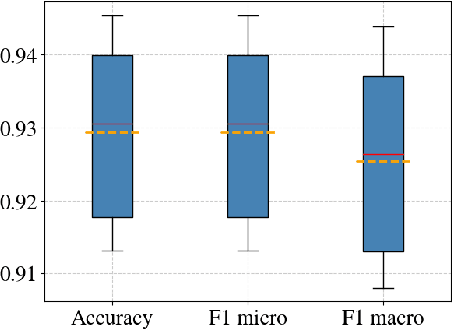
The proliferation of low-quality online information in today's era has underscored the need for robust and automatic mechanisms to evaluate the trustworthiness of online news publishers. In this paper, we analyse the trustworthiness of online news media outlets by leveraging a dataset of 4033 news stories from 40 different sources. We aim to infer the trustworthiness level of the source based on the classification of individual articles' content. The trust labels are obtained from NewsGuard, a journalistic organization that evaluates news sources using well-established editorial and publishing criteria. The results indicate that the classification model is highly effective in classifying the trustworthiness levels of the news articles. This research has practical applications in alerting readers to potentially untrustworthy news sources, assisting journalistic organizations in evaluating new or unfamiliar media outlets and supporting the selection of articles for their trustworthiness assessment.
From Online Behaviours to Images: A Novel Approach to Social Bot Detection
Apr 15, 2023



Online Social Networks have revolutionized how we consume and share information, but they have also led to a proliferation of content not always reliable and accurate. One particular type of social accounts is known to promote unreputable content, hyperpartisan, and propagandistic information. They are automated accounts, commonly called bots. Focusing on Twitter accounts, we propose a novel approach to bot detection: we first propose a new algorithm that transforms the sequence of actions that an account performs into an image; then, we leverage the strength of Convolutional Neural Networks to proceed with image classification. We compare our performances with state-of-the-art results for bot detection on genuine accounts / bot accounts datasets well known in the literature. The results confirm the effectiveness of the proposal, because the detection capability is on par with the state of the art, if not better in some cases.
Demystifying Misconceptions in Social Bots Research
Mar 30, 2023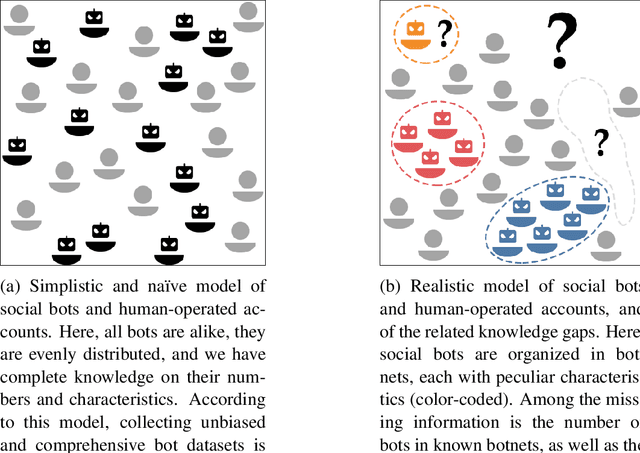
The science of social bots seeks knowledge and solutions to one of the most debated forms of online misinformation. Yet, social bots research is plagued by widespread biases, hyped results, and misconceptions that set the stage for ambiguities, unrealistic expectations, and seemingly irreconcilable findings. Overcoming such issues is instrumental towards ensuring reliable solutions and reaffirming the validity of the scientific method. In this contribution we revise some recent results in social bots research, highlighting and correcting factual errors as well as methodological and conceptual issues. More importantly, we demystify common misconceptions, addressing fundamental points on how social bots research is discussed. Our analysis surfaces the need to discuss misinformation research in a rigorous, unbiased, and responsible way. This article bolsters such effort by identifying and refuting common fallacious arguments used by both proponents and opponents of social bots research as well as providing indications on the correct methodologies and sound directions for future research in the field.
A Structured Analysis of Journalistic Evaluations for News Source Reliability
May 05, 2022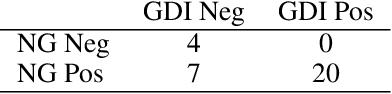

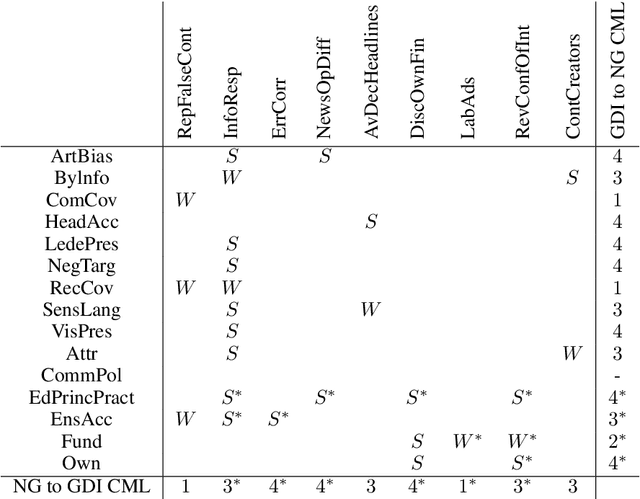
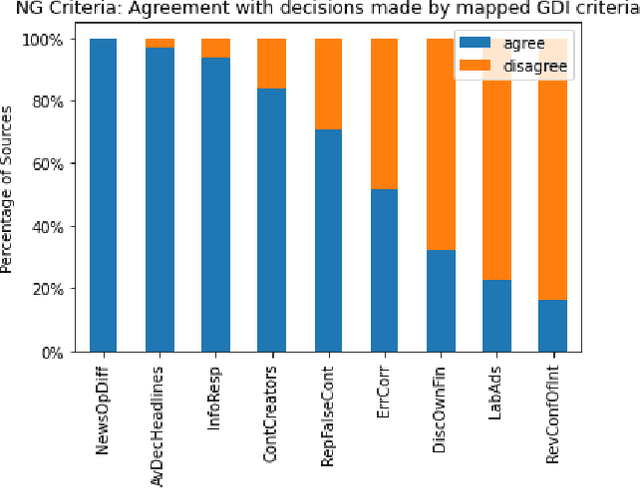
In today's era of information disorder, many organizations are moving to verify the veracity of news published on the web and social media. In particular, some agencies are exploring the world of online media and, through a largely manual process, ranking the credibility and transparency of news sources around the world. In this paper, we evaluate two procedures for assessing the risk of online media exposing their readers to m/disinformation. The procedures have been dictated by NewsGuard and The Global Disinformation Index, two well-known organizations combating d/misinformation via practices of good journalism. Specifically, considering a fixed set of media outlets, we examine how many of them were rated equally by the two procedures, and which aspects led to disagreement in the assessment. The result of our analysis shows a good degree of agreement, which in our opinion has a double value: it fortifies the correctness of the procedures and lays the groundwork for their automation.
Adversarial machine learning for protecting against online manipulation
Nov 23, 2021

Adversarial examples are inputs to a machine learning system that result in an incorrect output from that system. Attacks launched through this type of input can cause severe consequences: for example, in the field of image recognition, a stop signal can be misclassified as a speed limit indication.However, adversarial examples also represent the fuel for a flurry of research directions in different domains and applications. Here, we give an overview of how they can be profitably exploited as powerful tools to build stronger learning models, capable of better-withstanding attacks, for two crucial tasks: fake news and social bot detection.
Improving Opinion Spam Detection by Cumulative Relative Frequency Distribution
Dec 27, 2020


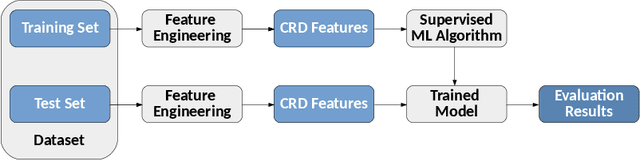
Over the last years, online reviews became very important since they can influence the purchase decision of consumers and the reputation of businesses, therefore, the practice of writing fake reviews can have severe consequences on customers and service providers. Various approaches have been proposed for detecting opinion spam in online reviews, especially based on supervised classifiers. In this contribution, we start from a set of effective features used for classifying opinion spam and we re-engineered them, by considering the Cumulative Relative Frequency Distribution of each feature. By an experimental evaluation carried out on real data from Yelp.com, we show that the use of the distributional features is able to improve the performances of classifiers.
Who framed Roger Reindeer? De-censorship of Facebook posts by snippet classification
Apr 10, 2018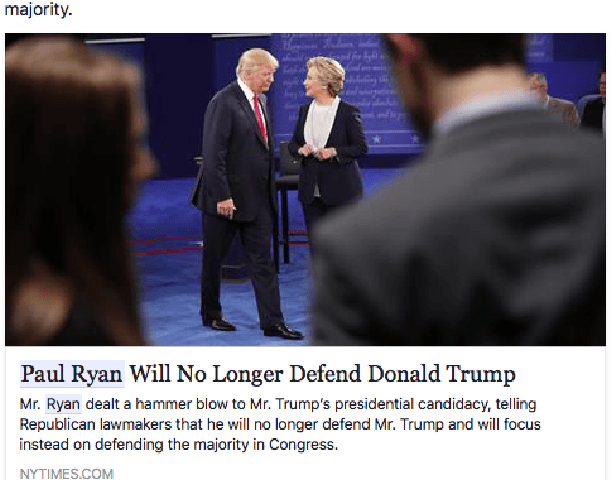
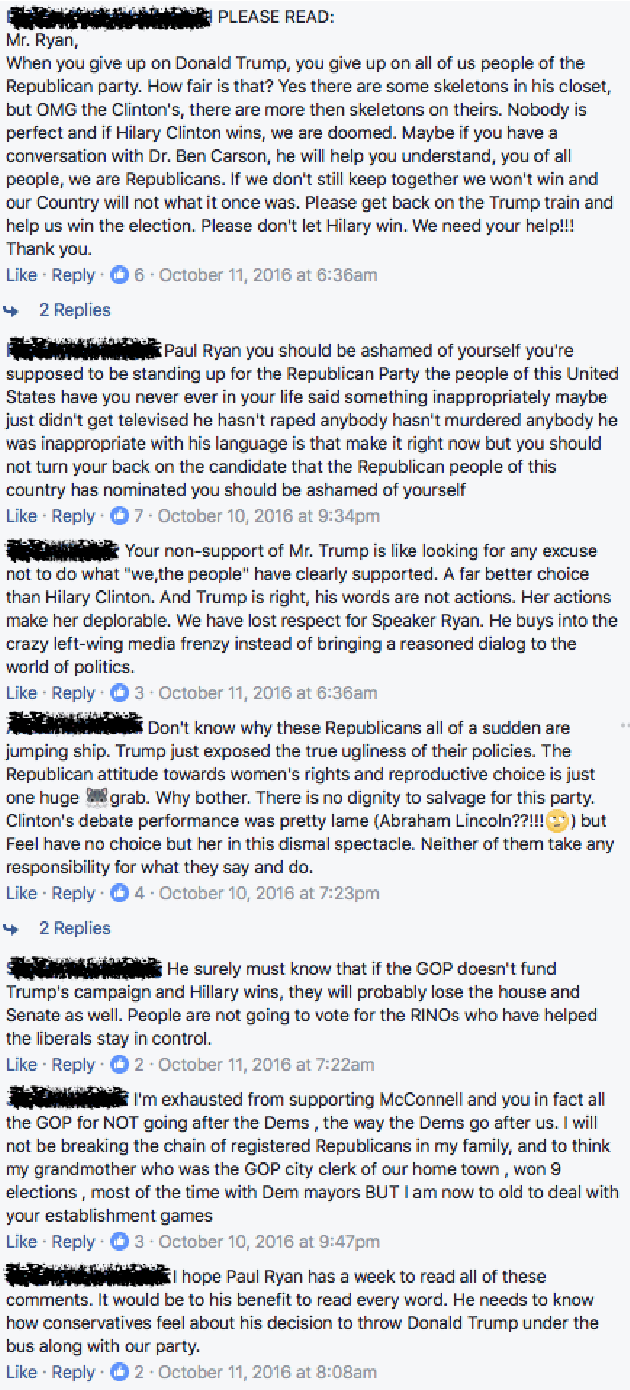
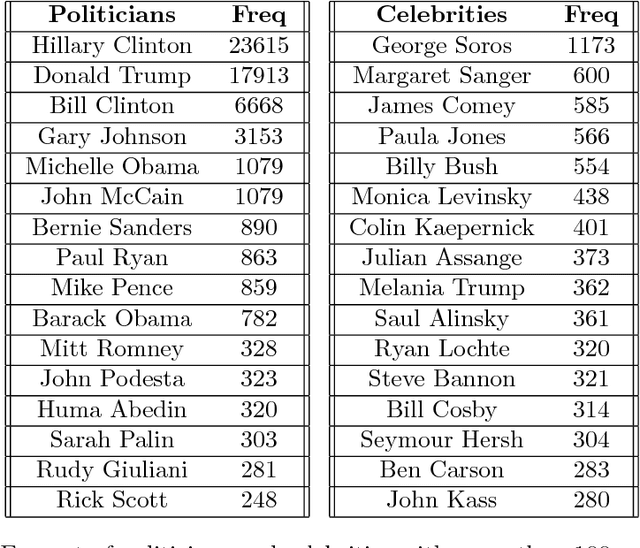
This paper considers online news censorship and it concentrates on censorship of identities. Obfuscating identities may occur for disparate reasons, from military to judiciary ones. In the majority of cases, this happens to protect individuals from being identified and persecuted by hostile people. However, being the collaborative web characterised by a redundancy of information, it is not unusual that the same fact is reported by multiple sources, which may not apply the same restriction policies in terms of censorship. Also, the proven aptitude of social network users to disclose personal information leads to the phenomenon that comments to news can reveal the data withheld in the news itself. This gives us a mean to figure out who the subject of the censored news is. We propose an adaptation of a text analysis approach to unveil censored identities. The approach is tested on a synthesised scenario, which however resembles a real use case. Leveraging a text analysis based on a context classifier trained over snippets from posts and comments of Facebook pages, we achieve promising results. Despite the quite constrained settings in which we operate -- such as considering only snippets of very short length -- our system successfully detects the censored name, choosing among 10 different candidate names, in more than 50\% of the investigated cases. This outperforms the results of two reference baselines. The findings reported in this paper, other than being supported by a thorough experimental methodology and interesting on their own, also pave the way for further investigation on the insidious issues of censorship on the web.
A study on text-score disagreement in online reviews
Jul 21, 2017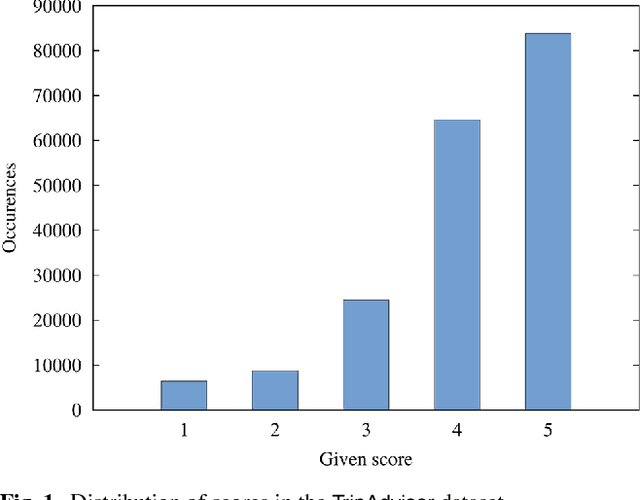
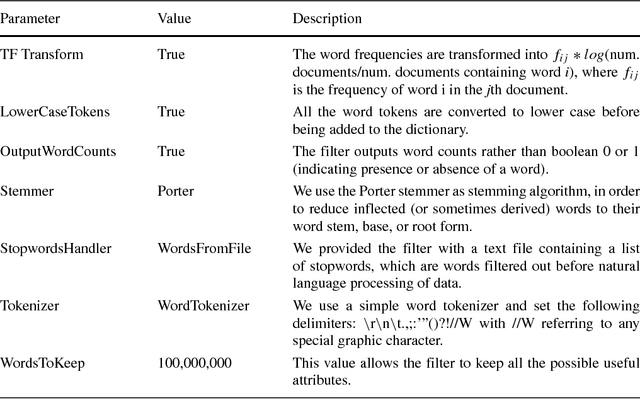


In this paper, we focus on online reviews and employ artificial intelligence tools, taken from the cognitive computing field, to help understanding the relationships between the textual part of the review and the assigned numerical score. We move from the intuitions that 1) a set of textual reviews expressing different sentiments may feature the same score (and vice-versa); and 2) detecting and analyzing the mismatches between the review content and the actual score may benefit both service providers and consumers, by highlighting specific factors of satisfaction (and dissatisfaction) in texts. To prove the intuitions, we adopt sentiment analysis techniques and we concentrate on hotel reviews, to find polarity mismatches therein. In particular, we first train a text classifier with a set of annotated hotel reviews, taken from the Booking website. Then, we analyze a large dataset, with around 160k hotel reviews collected from Tripadvisor, with the aim of detecting a polarity mismatch, indicating if the textual content of the review is in line, or not, with the associated score. Using well established artificial intelligence techniques and analyzing in depth the reviews featuring a mismatch between the text polarity and the score, we find that -on a scale of five stars- those reviews ranked with middle scores include a mixture of positive and negative aspects. The approach proposed here, beside acting as a polarity detector, provides an effective selection of reviews -on an initial very large dataset- that may allow both consumers and providers to focus directly on the review subset featuring a text/score disagreement, which conveniently convey to the user a summary of positive and negative features of the review target.