 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho framed Roger Reindeer? De-censorship of Facebook posts by snippet classification
Apr 10, 2018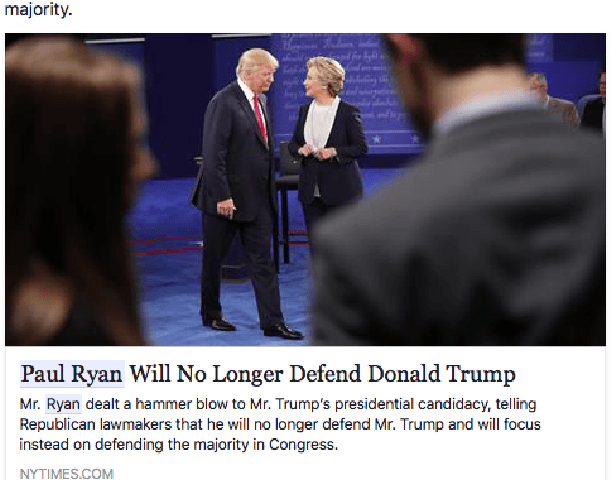
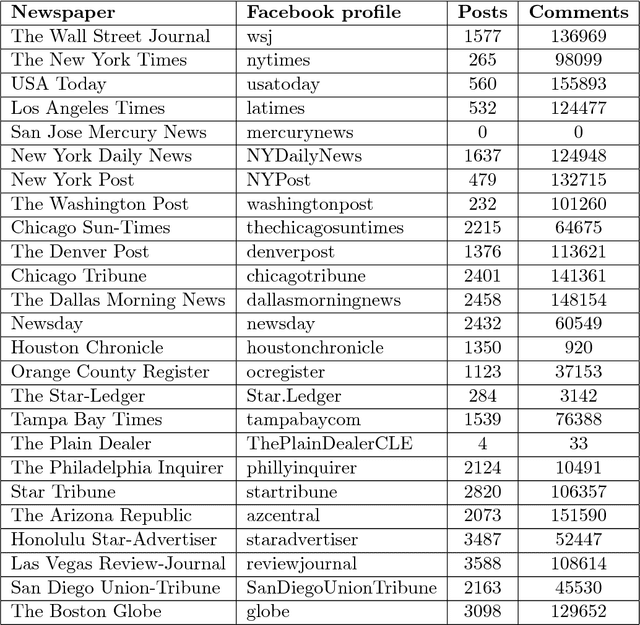
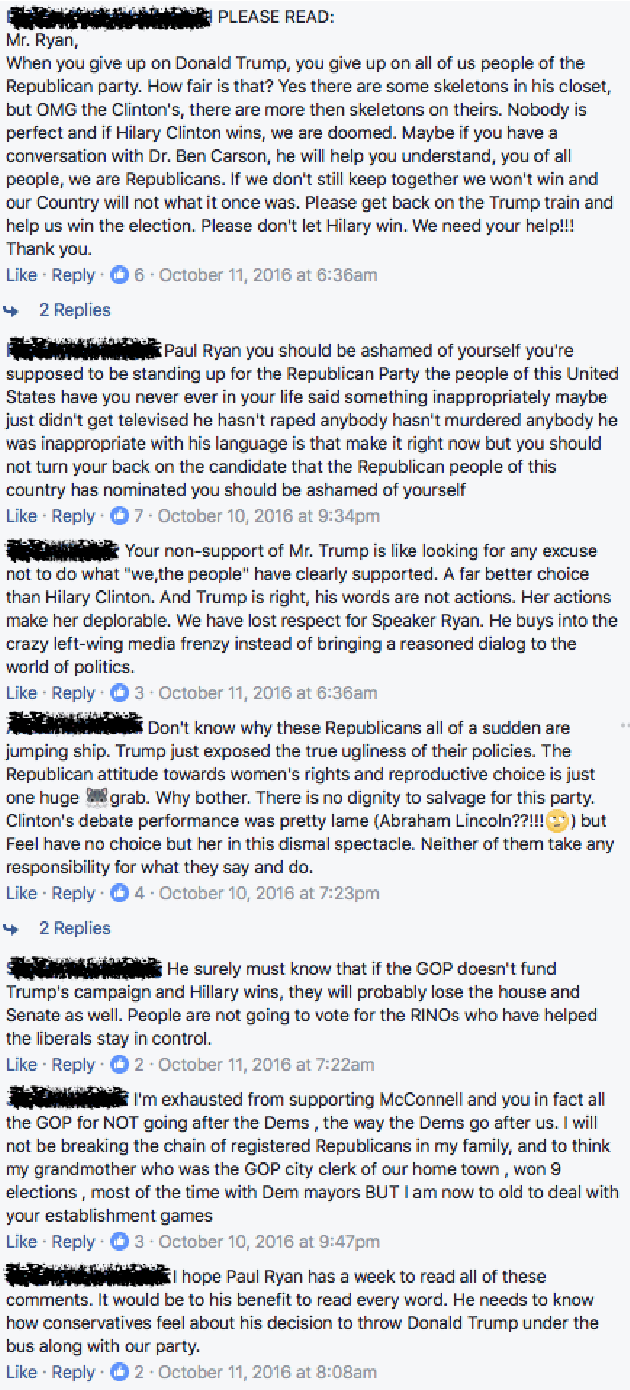
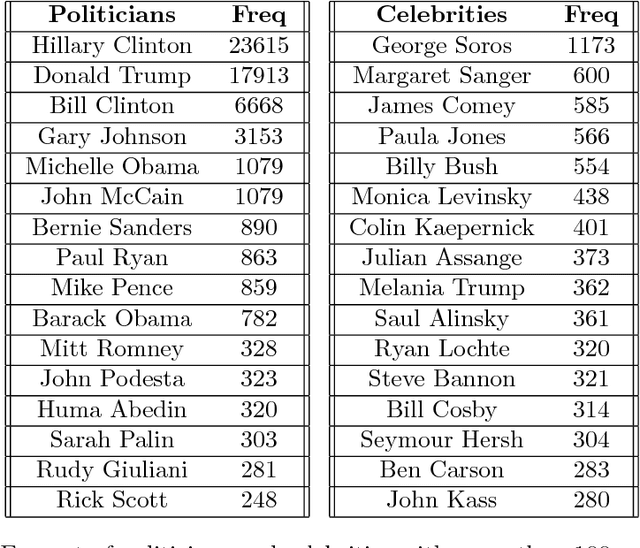
This paper considers online news censorship and it concentrates on censorship of identities. Obfuscating identities may occur for disparate reasons, from military to judiciary ones. In the majority of cases, this happens to protect individuals from being identified and persecuted by hostile people. However, being the collaborative web characterised by a redundancy of information, it is not unusual that the same fact is reported by multiple sources, which may not apply the same restriction policies in terms of censorship. Also, the proven aptitude of social network users to disclose personal information leads to the phenomenon that comments to news can reveal the data withheld in the news itself. This gives us a mean to figure out who the subject of the censored news is. We propose an adaptation of a text analysis approach to unveil censored identities. The approach is tested on a synthesised scenario, which however resembles a real use case. Leveraging a text analysis based on a context classifier trained over snippets from posts and comments of Facebook pages, we achieve promising results. Despite the quite constrained settings in which we operate -- such as considering only snippets of very short length -- our system successfully detects the censored name, choosing among 10 different candidate names, in more than 50\% of the investigated cases. This outperforms the results of two reference baselines. The findings reported in this paper, other than being supported by a thorough experimental methodology and interesting on their own, also pave the way for further investigation on the insidious issues of censorship on the web.
Mining Worse and Better Opinions. Unsupervised and Agnostic Aggregation of Online Reviews
Apr 18, 2017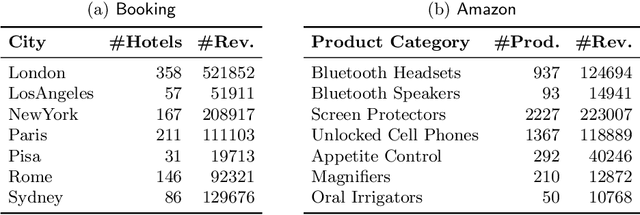
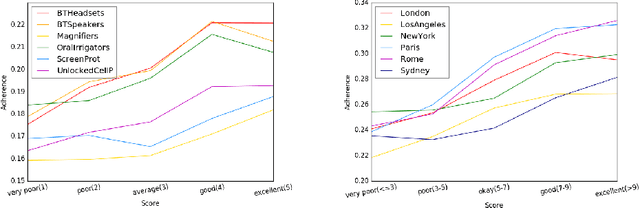

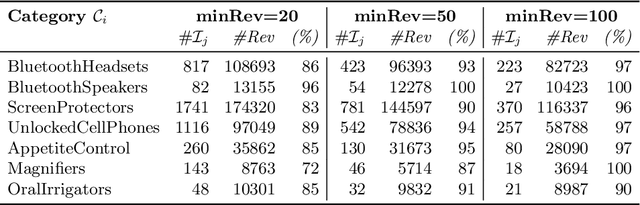
In this paper, we propose a novel approach for aggregating online reviews, according to the opinions they express. Our methodology is unsupervised - due to the fact that it does not rely on pre-labeled reviews - and it is agnostic - since it does not make any assumption about the domain or the language of the review content. We measure the adherence of a review content to the domain terminology extracted from a review set. First, we demonstrate the informativeness of the adherence metric with respect to the score associated with a review. Then, we exploit the metric values to group reviews, according to the opinions they express. Our experimental campaign has been carried out on two large datasets collected from Booking and Amazon, respectively.
Semi-supervised knowledge extraction for detection of drugs and their effects
Sep 21, 2016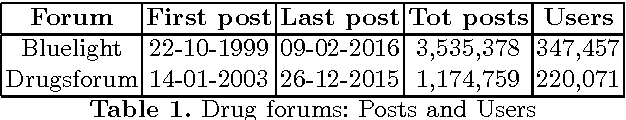
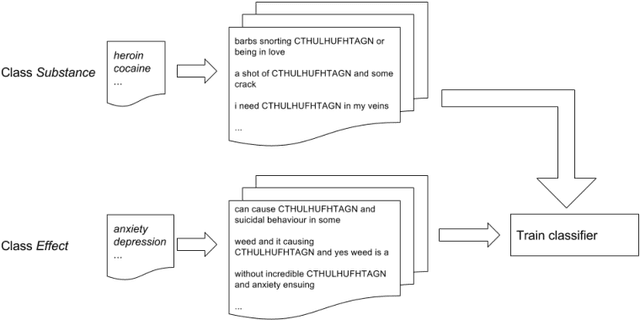
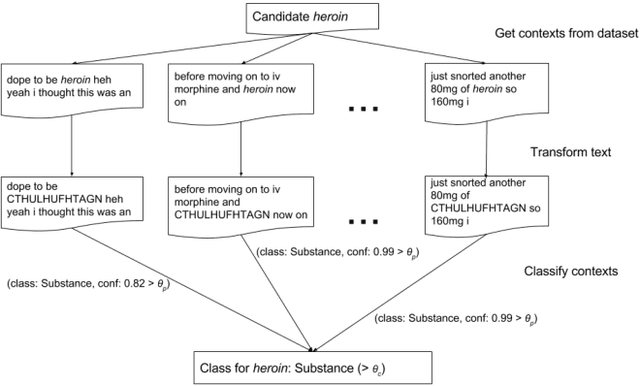
New Psychoactive Substances (NPS) are drugs that lay in a grey area of legislation, since they are not internationally and officially banned, possibly leading to their not prosecutable trade. The exacerbation of the phenomenon is that NPS can be easily sold and bought online. Here, we consider large corpora of textual posts, published on online forums specialized on drug discussions, plus a small set of known substances and associated effects, which we call seeds. We propose a semi-supervised approach to knowledge extraction, applied to the detection of drugs (comprising NPS) and effects from the corpora under investigation. Based on the very small set of initial seeds, the work highlights how a contrastive approach and context deduction are effective in detecting substances and effects from the corpora. Our promising results, which feature a F1 score close to 0.9, pave the way for shortening the detection time of new psychoactive substances, once these are discussed and advertised on the Internet.