 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI in Time-Sensitive Scenarios: Prefetched Offline Explanation Model
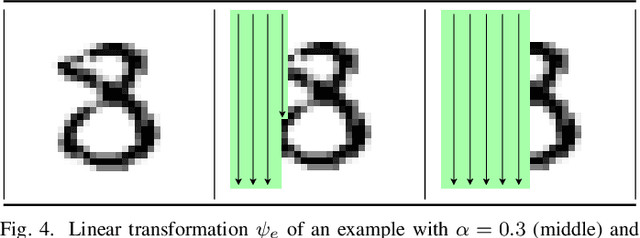
Mar 06, 2025As predictive machine learning models become increasingly adopted and advanced, their role has evolved from merely predicting outcomes to actively shaping them. This evolution has underscored the importance of Trustworthy AI, highlighting the necessity to extend our focus beyond mere accuracy and toward a comprehensive understanding of these models' behaviors within the specific contexts of their applications. To further progress in explainability, we introduce Poem, Prefetched Offline Explanation Model, a model-agnostic, local explainability algorithm for image data. The algorithm generates exemplars, counterexemplars and saliency maps to provide quick and effective explanations suitable for time-sensitive scenarios. Leveraging an existing local algorithm, \poem{} infers factual and counterfactual rules from data to create illustrative examples and opposite scenarios with an enhanced stability by design. A novel mechanism then matches incoming test points with an explanation base and produces diverse exemplars, informative saliency maps and believable counterexemplars. Experimental results indicate that Poem outperforms its predecessor Abele in speed and ability to generate more nuanced and varied exemplars alongside more insightful saliency maps and valuable counterexemplars.
Urban Region Embeddings from Service-Specific Mobile Traffic Data
Nov 20, 2024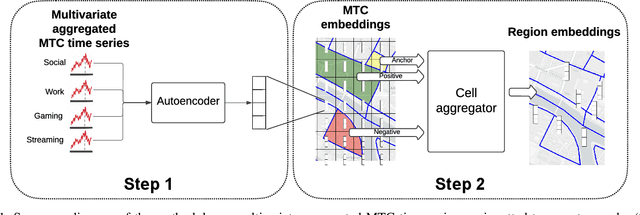
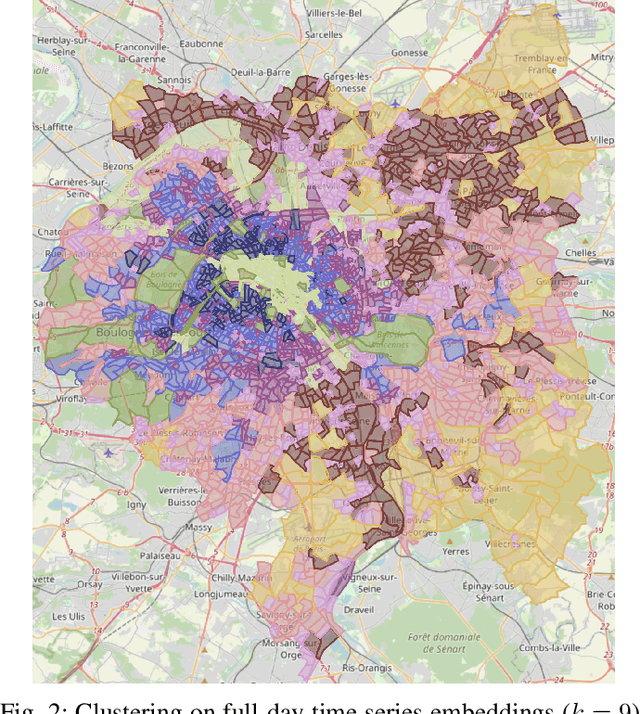
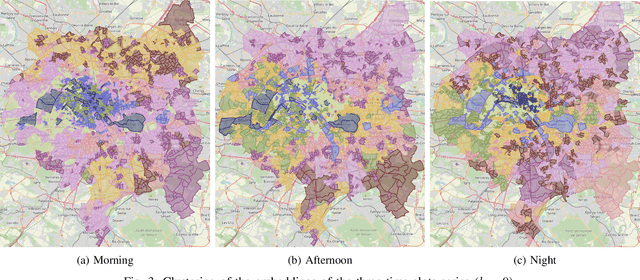
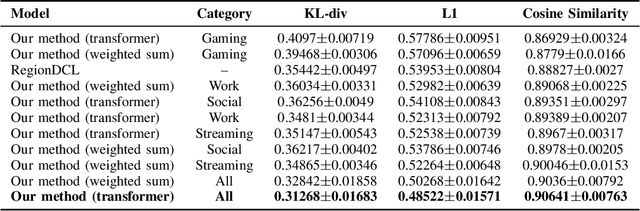
With the advent of advanced 4G/5G mobile networks, mobile phone data collected by operators now includes detailed, service-specific traffic information with high spatio-temporal resolution. In this paper, we leverage this type of data to explore its potential for generating high-quality representations of urban regions. To achieve this, we present a methodology for creating urban region embeddings from service-specific mobile traffic data, employing a temporal convolutional network-based autoencoder, transformers, and learnable weighted sum models to capture key urban features. In the extensive experimental evaluation conducted using a real-world dataset, we demonstrate that the embeddings generated by our methodology effectively capture urban characteristics. Specifically, our embeddings are compared against those of a state-of-the-art competitor across two downstream tasks. Additionally, through clustering techniques, we investigate how well the embeddings produced by our methodology capture the temporal dynamics and characteristics of the underlying urban regions. Overall, this work highlights the potential of service-specific mobile traffic data for urban research and emphasizes the importance of making such data accessible to support public innovation.
Evaluating Trustworthiness of Online News Publishers via Article Classification
Jan 03, 2024
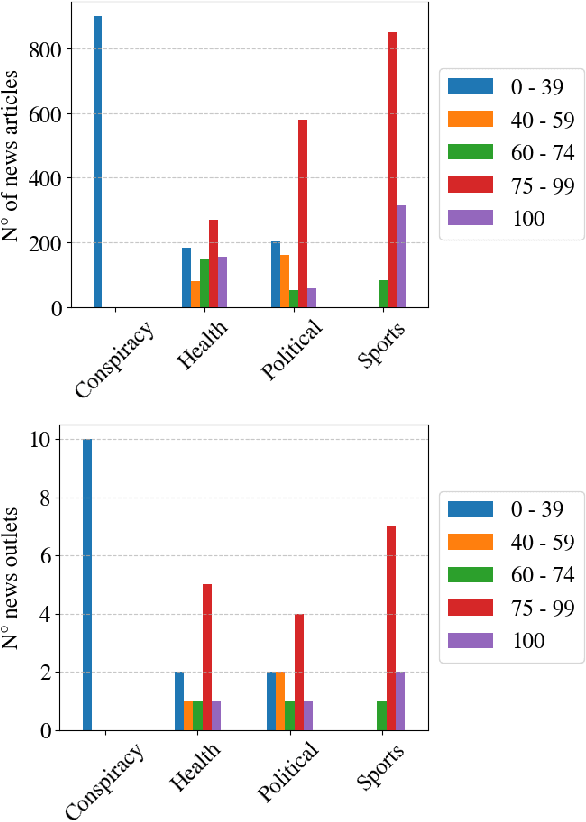

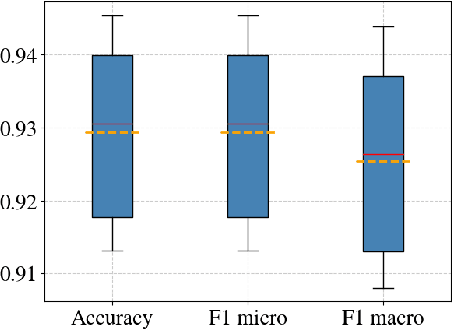
The proliferation of low-quality online information in today's era has underscored the need for robust and automatic mechanisms to evaluate the trustworthiness of online news publishers. In this paper, we analyse the trustworthiness of online news media outlets by leveraging a dataset of 4033 news stories from 40 different sources. We aim to infer the trustworthiness level of the source based on the classification of individual articles' content. The trust labels are obtained from NewsGuard, a journalistic organization that evaluates news sources using well-established editorial and publishing criteria. The results indicate that the classification model is highly effective in classifying the trustworthiness levels of the news articles. This research has practical applications in alerting readers to potentially untrustworthy news sources, assisting journalistic organizations in evaluating new or unfamiliar media outlets and supporting the selection of articles for their trustworthiness assessment.
Sharpening Ponzi Schemes Detection on Ethereum with Machine Learning
Jan 12, 2023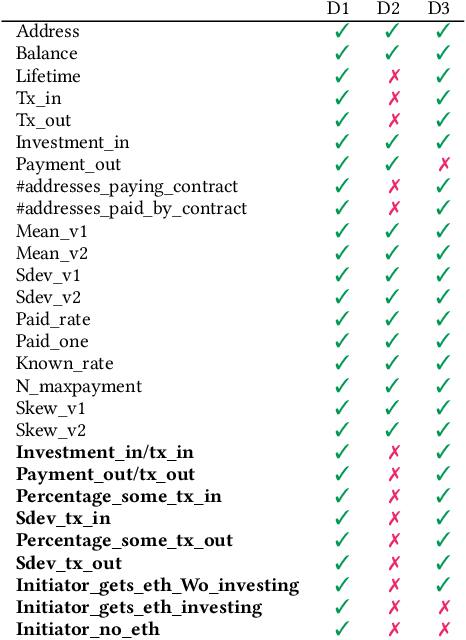
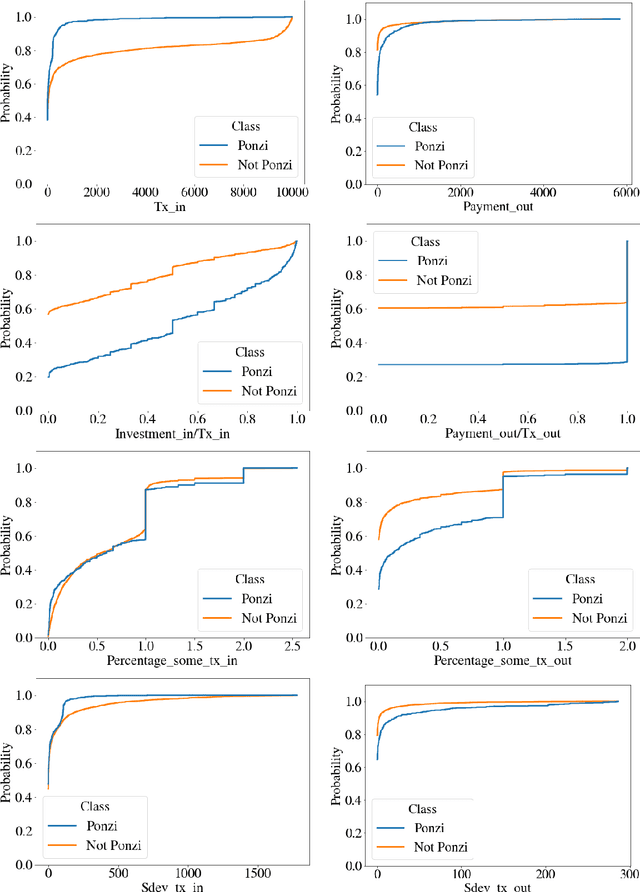
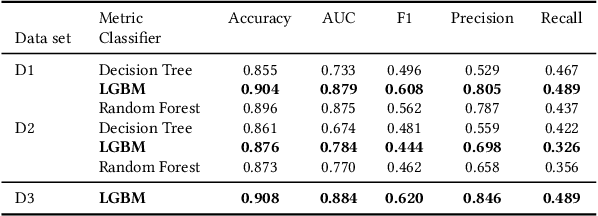
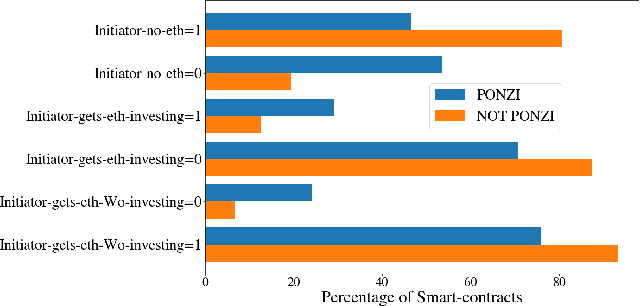
Blockchain technology has been successfully exploited for deploying new economic applications. However, it has started arousing the interest of malicious users who deliver scams to deceive honest users and to gain economic advantages. Among the various scams, Ponzi schemes are one of the most common. Here, we present an automatic technique for detecting smart Ponzi contracts on Ethereum. We release a reusable data set with 4422 unique real-world smart contracts. Then, we introduce a new set of features that allow us to improve the classification. Finally, we identify a small and effective set of features that ensures a good classification quality.
MUSTACHE: Multi-Step-Ahead Predictions for Cache Eviction
Nov 03, 2022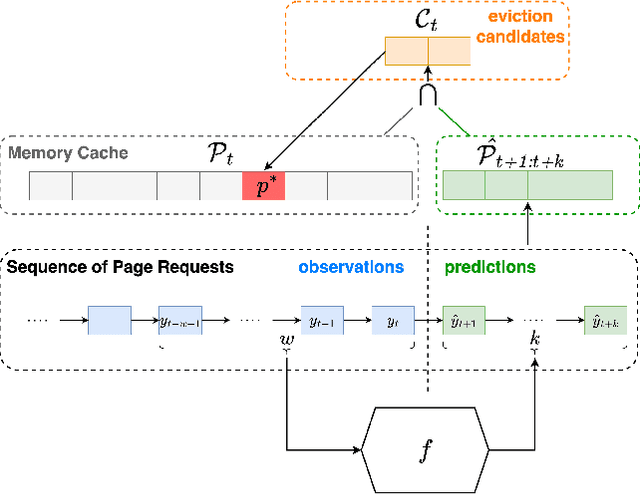

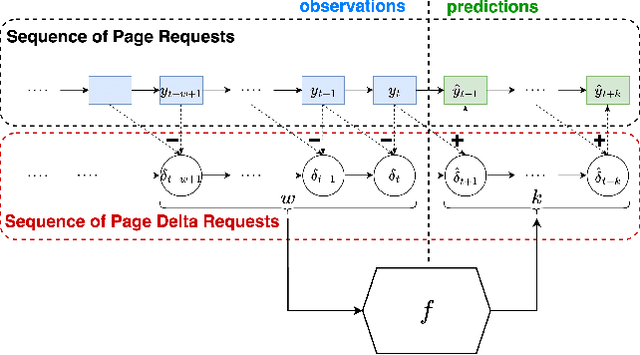

In this work, we propose MUSTACHE, a new page cache replacement algorithm whose logic is learned from observed memory access requests rather than fixed like existing policies. We formulate the page request prediction problem as a categorical time series forecasting task. Then, our method queries the learned page request forecaster to obtain the next $k$ predicted page memory references to better approximate the optimal B\'el\'ady's replacement algorithm. We implement several forecasting techniques using advanced deep learning architectures and integrate the best-performing one into an existing open-source cache simulator. Experiments run on benchmark datasets show that MUSTACHE outperforms the best page replacement heuristic (i.e., exact LRU), improving the cache hit ratio by 1.9% and reducing the number of reads/writes required to handle cache misses by 18.4% and 10.3%.
Covert Channel Attack to Federated Learning Systems
Apr 21, 2021


Federated learning (FL) goes beyond traditional, centralized machine learning by distributing model training among a large collection of edge clients. These clients cooperatively train a global, e.g., cloud-hosted, model without disclosing their local, private training data. The global model is then shared among all the participants which use it for local predictions. In this paper, we put forward a novel attacker model aiming at turning FL systems into covert channels to implement a stealth communication infrastructure. The main intuition is that, during federated training, a malicious sender can poison the global model by submitting purposely crafted examples. Although the effect of the model poisoning is negligible to other participants, and does not alter the overall model performance, it can be observed by a malicious receiver and used to transmit a single bit.
Towards Real-time Customer Experience Prediction for Telecommunication Operators
Sep 24, 2015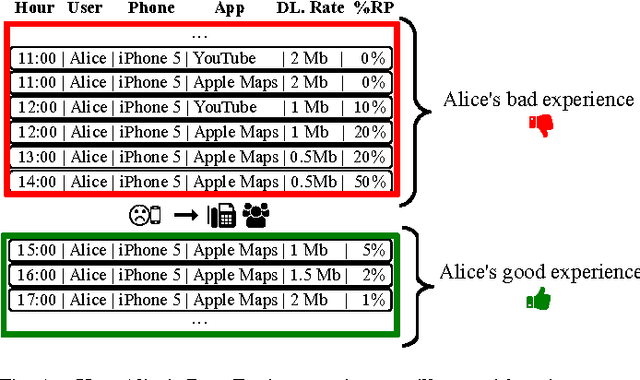
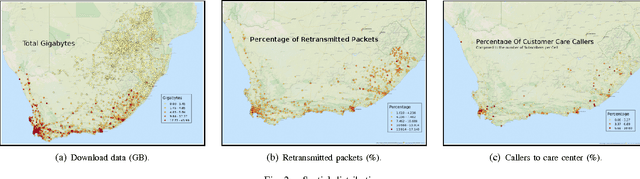
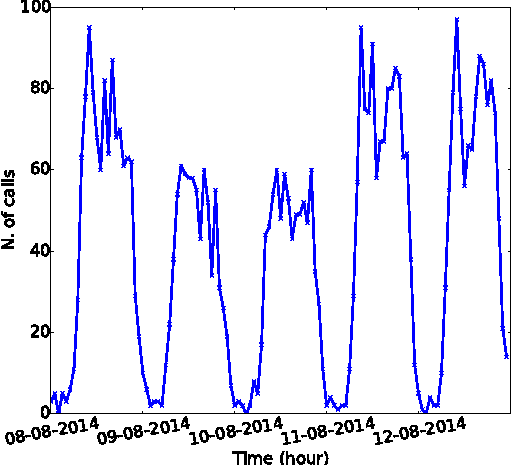
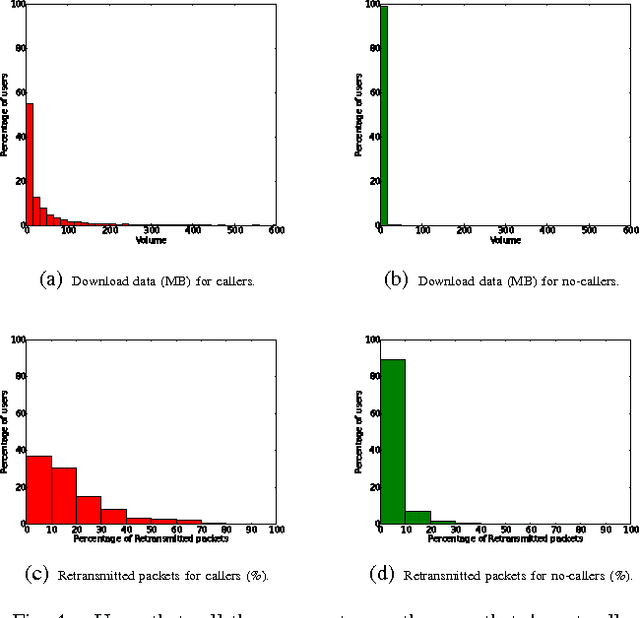
Telecommunications operators (telcos) traditional sources of income, voice and SMS, are shrinking due to customers using over-the-top (OTT) applications such as WhatsApp or Viber. In this challenging environment it is critical for telcos to maintain or grow their market share, by providing users with as good an experience as possible on their network. But the task of extracting customer insights from the vast amounts of data collected by telcos is growing in complexity and scale everey day. How can we measure and predict the quality of a user's experience on a telco network in real-time? That is the problem that we address in this paper. We present an approach to capture, in (near) real-time, the mobile customer experience in order to assess which conditions lead the user to place a call to a telco's customer care center. To this end, we follow a supervised learning approach for prediction and train our 'Restricted Random Forest' model using, as a proxy for bad experience, the observed customer transactions in the telco data feed before the user places a call to a customer care center. We evaluate our approach using a rich dataset provided by a major African telecommunication's company and a novel big data architecture for both the training and scoring of predictive models. Our empirical study shows our solution to be effective at predicting user experience by inferring if a customer will place a call based on his current context. These promising results open new possibilities for improved customer service, which will help telcos to reduce churn rates and improve customer experience, both factors that directly impact their revenue growth.
Predicting User Engagement in Twitter with Collaborative Ranking
Dec 26, 2014
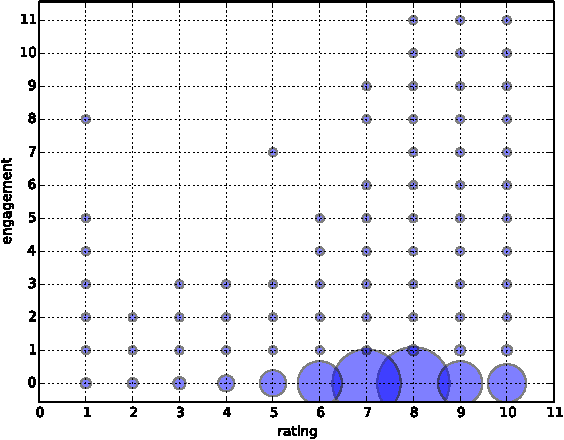

Collaborative Filtering (CF) is a core component of popular web-based services such as Amazon, YouTube, Netflix, and Twitter. Most applications use CF to recommend a small set of items to the user. For instance, YouTube presents to a user a list of top-n videos she would likely watch next based on her rating and viewing history. Current methods of CF evaluation have been focused on assessing the quality of a predicted rating or the ranking performance for top-n recommended items. However, restricting the recommender system evaluation to these two aspects is rather limiting and neglects other dimensions that could better characterize a well-perceived recommendation. In this paper, instead of optimizing rating or top-n recommendation, we focus on the task of predicting which items generate the highest user engagement. In particular, we use Twitter as our testbed and cast the problem as a Collaborative Ranking task where the rich features extracted from the metadata of the tweets help to complement the transaction information limited to user ids, item ids, ratings and timestamps. We learn a scoring function that directly optimizes the user engagement in terms of nDCG@10 on the predicted ranking. Experiments conducted on an extended version of the MovieTweetings dataset, released as part of the RecSys Challenge 2014, show the effectiveness of our approach.
* RecSysChallenge'14 at RecSys 2014, October 10, 2014, Foster City, CA, USA