 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Joy of Neural Painting
Nov 22, 2021


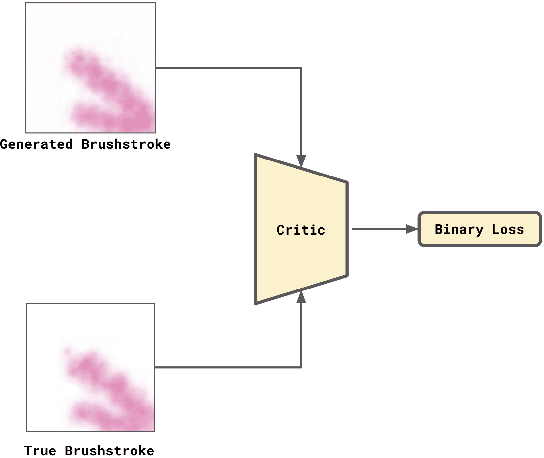
Neural Painters is a class of models that follows a GAN framework to generate brushstrokes, which are then composed to create paintings. GANs are great generative models for AI Art but they are known to be notoriously difficult to train. To overcome GAN's limitations and to speed up the Neural Painter training, we applied Transfer Learning to the process reducing it from days to only hours, while achieving the same level of visual aesthetics in the final paintings generated. We report our approach and results in this work.
NU:BRIEF -- A Privacy-aware Newsletter Personalization Engine for Publishers
Sep 08, 2021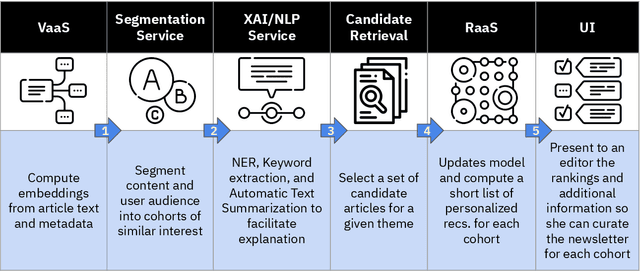
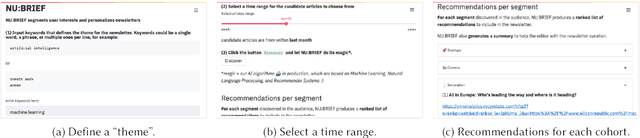
Newsletters have (re-) emerged as a powerful tool for publishers to engage with their readers directly and more effectively. Despite the diversity in their audiences, publishers' newsletters remain largely a one-size-fits-all offering, which is suboptimal. In this paper, we present NU:BRIEF, a web application for publishers that enables them to personalize their newsletters without harvesting personal data. Personalized newsletters build a habit and become a great conversion tool for publishers, providing an alternative readers-generated revenue model to a declining ad/clickbait-centered business model.
Why is it Difficult to Detect Sudden and Unexpected Epidemic Outbreaks in Twitter?
Nov 10, 2016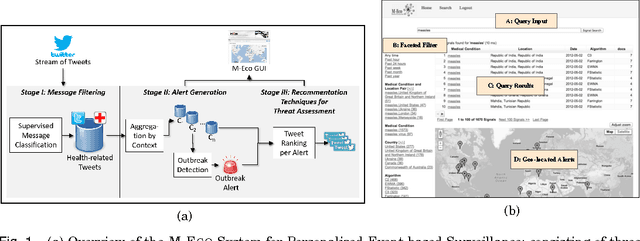
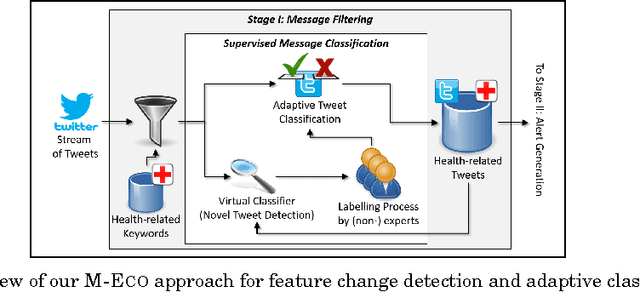
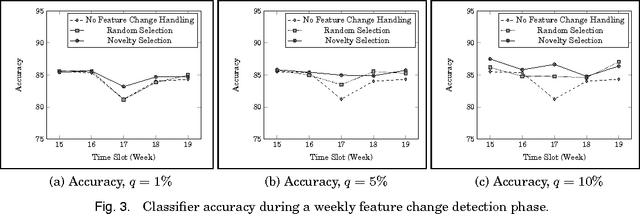
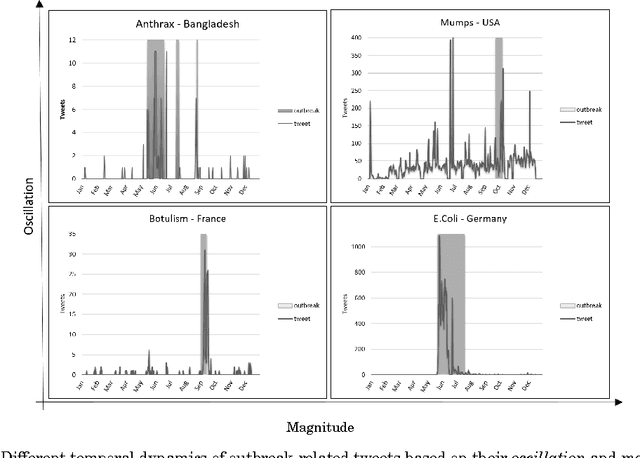
Social media services such as Twitter are a valuable source of information for decision support systems. Many studies have shown that this also holds for the medical domain, where Twitter is considered a viable tool for public health officials to sift through relevant information for the early detection, management, and control of epidemic outbreaks. This is possible due to the inherent capability of social media services to transmit information faster than traditional channels. However, the majority of current studies have limited their scope to the detection of common and seasonal health recurring events (e.g., Influenza-like Illness), partially due to the noisy nature of Twitter data, which makes outbreak detection and management very challenging. Within the European project M-Eco, we developed a Twitter-based Epidemic Intelligence (EI) system, which is designed to also handle a more general class of unexpected and aperiodic outbreaks. In particular, we faced three main research challenges in this endeavor: 1) dynamic classification to manage terminology evolution of Twitter messages, 2) alert generation to produce reliable outbreak alerts analyzing the (noisy) tweet time series, and 3) ranking and recommendation to support domain experts for better assessment of the generated alerts. In this paper, we empirically evaluate our proposed approach to these challenges using real-world outbreak datasets and a large collection of tweets. We validate our solution with domain experts, describe our experiences, and give a more realistic view on the benefits and issues of analyzing social media for public health.
Multi-Relational Learning at Scale with ADMM
Apr 03, 2016



Learning from multiple-relational data which contains noise, ambiguities, or duplicate entities is essential to a wide range of applications such as statistical inference based on Web Linked Data, recommender systems, computational biology, and natural language processing. These tasks usually require working with very large and complex datasets - e.g., the Web graph - however, current approaches to multi-relational learning are not practical for such scenarios due to their high computational complexity and poor scalability on large data. In this paper, we propose a novel and scalable approach for multi-relational factorization based on consensus optimization. Our model, called ConsMRF, is based on the Alternating Direction Method of Multipliers (ADMM) framework, which enables us to optimize each target relation using a smaller set of parameters than the state-of-the-art competitors in this task. Due to ADMM's nature, ConsMRF can be easily parallelized which makes it suitable for large multi-relational data. Experiments on large Web datasets - derived from DBpedia, Wikipedia and YAGO - show the efficiency and performance improvement of ConsMRF over strong competitors. In addition, ConsMRF near-linear scalability indicates great potential to tackle Web-scale problem sizes.
Towards Real-time Customer Experience Prediction for Telecommunication Operators
Sep 24, 2015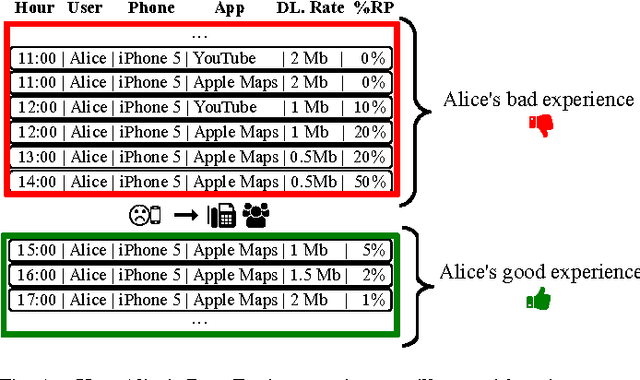
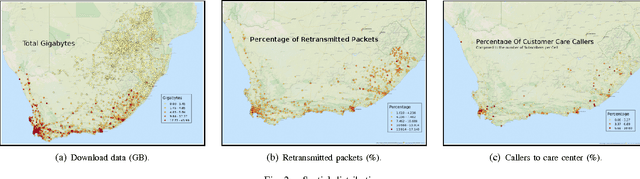
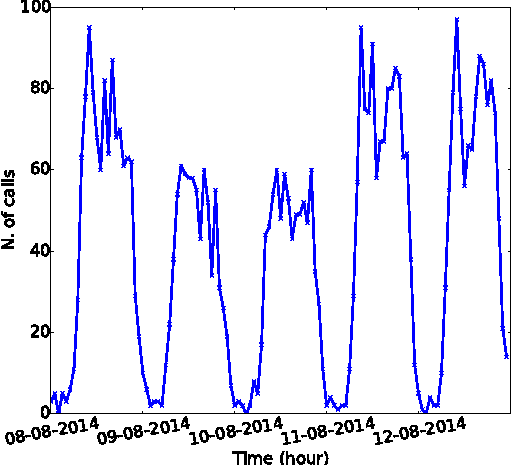
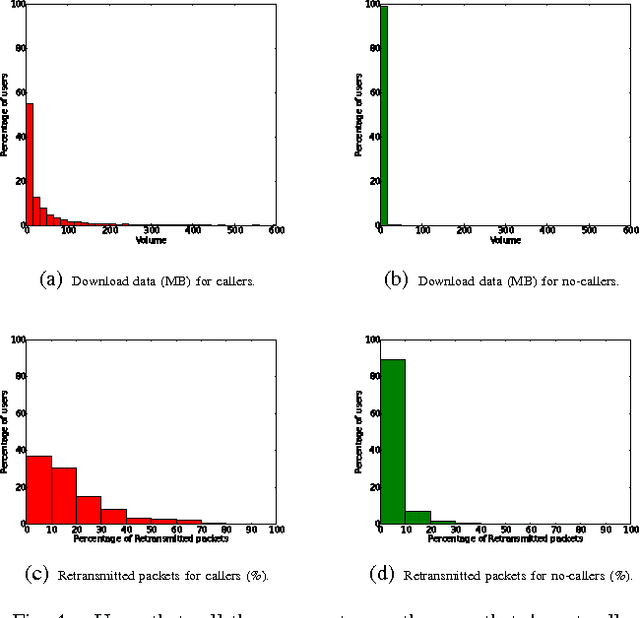
Telecommunications operators (telcos) traditional sources of income, voice and SMS, are shrinking due to customers using over-the-top (OTT) applications such as WhatsApp or Viber. In this challenging environment it is critical for telcos to maintain or grow their market share, by providing users with as good an experience as possible on their network. But the task of extracting customer insights from the vast amounts of data collected by telcos is growing in complexity and scale everey day. How can we measure and predict the quality of a user's experience on a telco network in real-time? That is the problem that we address in this paper. We present an approach to capture, in (near) real-time, the mobile customer experience in order to assess which conditions lead the user to place a call to a telco's customer care center. To this end, we follow a supervised learning approach for prediction and train our 'Restricted Random Forest' model using, as a proxy for bad experience, the observed customer transactions in the telco data feed before the user places a call to a customer care center. We evaluate our approach using a rich dataset provided by a major African telecommunication's company and a novel big data architecture for both the training and scoring of predictive models. Our empirical study shows our solution to be effective at predicting user experience by inferring if a customer will place a call based on his current context. These promising results open new possibilities for improved customer service, which will help telcos to reduce churn rates and improve customer experience, both factors that directly impact their revenue growth.
(Blue) Taxi Destination and Trip Time Prediction from Partial Trajectories
Sep 17, 2015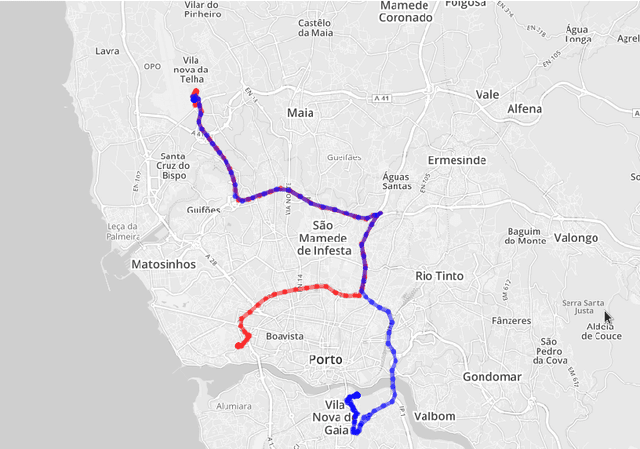
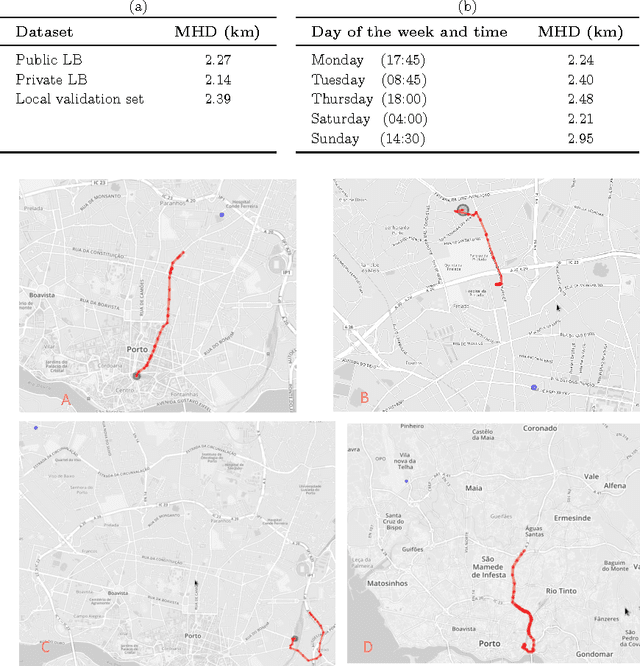
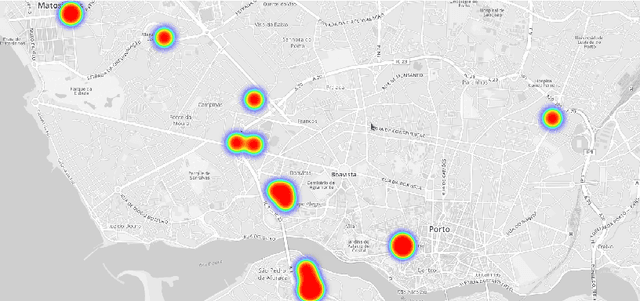
Real-time estimation of destination and travel time for taxis is of great importance for existing electronic dispatch systems. We present an approach based on trip matching and ensemble learning, in which we leverage the patterns observed in a dataset of roughly 1.7 million taxi journeys to predict the corresponding final destination and travel time for ongoing taxi trips, as a solution for the ECML/PKDD Discovery Challenge 2015 competition. The results of our empirical evaluation show that our approach is effective and very robust, which led our team -- BlueTaxi -- to the 3rd and 7th position of the final rankings for the trip time and destination prediction tasks, respectively. Given the fact that the final rankings were computed using a very small test set (with only 320 trips) we believe that our approach is one of the most robust solutions for the challenge based on the consistency of our good results across the test sets.
Predicting User Engagement in Twitter with Collaborative Ranking
Dec 26, 2014
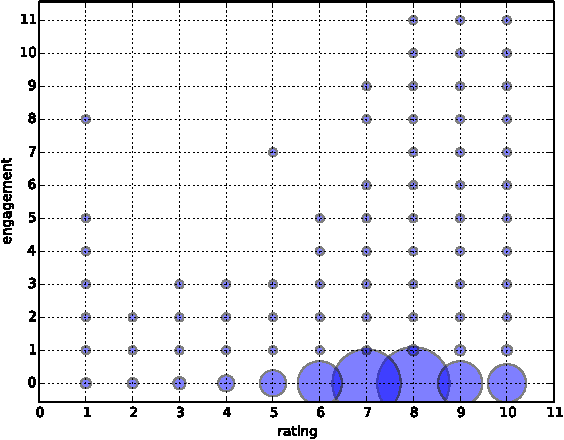

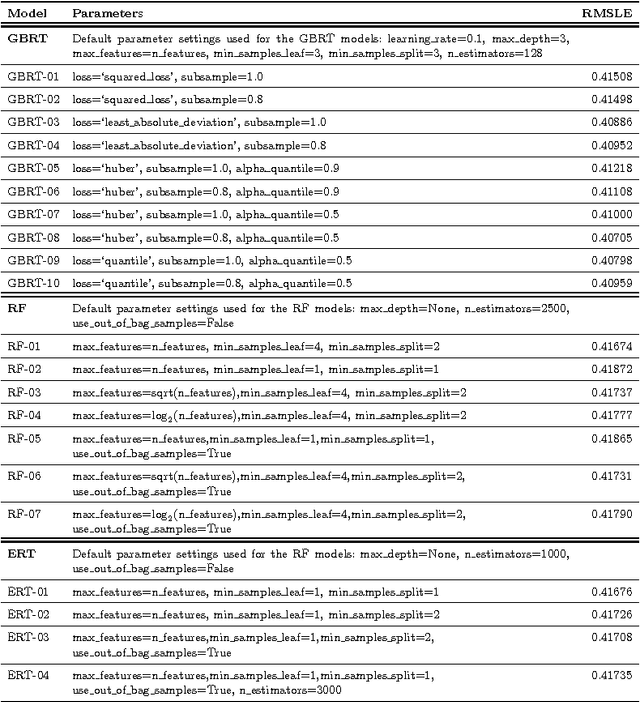
Collaborative Filtering (CF) is a core component of popular web-based services such as Amazon, YouTube, Netflix, and Twitter. Most applications use CF to recommend a small set of items to the user. For instance, YouTube presents to a user a list of top-n videos she would likely watch next based on her rating and viewing history. Current methods of CF evaluation have been focused on assessing the quality of a predicted rating or the ranking performance for top-n recommended items. However, restricting the recommender system evaluation to these two aspects is rather limiting and neglects other dimensions that could better characterize a well-perceived recommendation. In this paper, instead of optimizing rating or top-n recommendation, we focus on the task of predicting which items generate the highest user engagement. In particular, we use Twitter as our testbed and cast the problem as a Collaborative Ranking task where the rich features extracted from the metadata of the tweets help to complement the transaction information limited to user ids, item ids, ratings and timestamps. We learn a scoring function that directly optimizes the user engagement in terms of nDCG@10 on the predicted ranking. Experiments conducted on an extended version of the MovieTweetings dataset, released as part of the RecSys Challenge 2014, show the effectiveness of our approach.
* RecSysChallenge'14 at RecSys 2014, October 10, 2014, Foster City, CA, USA
Collaborative Filtering Ensemble for Personalized Name Recommendation
Jul 16, 2014

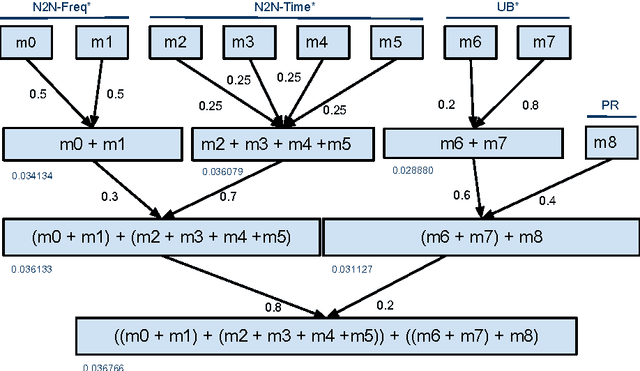
Out of thousands of names to choose from, picking the right one for your child is a daunting task. In this work, our objective is to help parents making an informed decision while choosing a name for their baby. We follow a recommender system approach and combine, in an ensemble, the individual rankings produced by simple collaborative filtering algorithms in order to produce a personalized list of names that meets the individual parents' taste. Our experiments were conducted using real-world data collected from the query logs of 'nameling' (nameling.net), an online portal for searching and exploring names, which corresponds to the dataset released in the context of the ECML PKDD Discover Challenge 2013. Our approach is intuitive, easy to implement, and features fast training and prediction steps.
* Top-N recommendation; personalized ranking; given name recommendation
Alleviating Media Bias Through Intelligent Agent Blogging
Feb 04, 2009
Consumers of mass media must have a comprehensive, balanced and plural selection of news to get an unbiased perspective; but achieving this goal can be very challenging, laborious and time consuming. News stories development over time, its (in)consistency, and different level of coverage across the media outlets are challenges that a conscientious reader has to overcome in order to alleviate bias. In this paper we present an intelligent agent framework currently facilitating analysis of the main sources of on-line news in El Salvador. We show how prior tools of text analysis and Web 2.0 technologies can be combined with minimal manual intervention to help individuals on their rational decision process, while holding media outlets accountable for their work.
Emergence of Spontaneous Order Through Neighborhood Formation in Peer-to-Peer Recommender Systems
Dec 23, 2008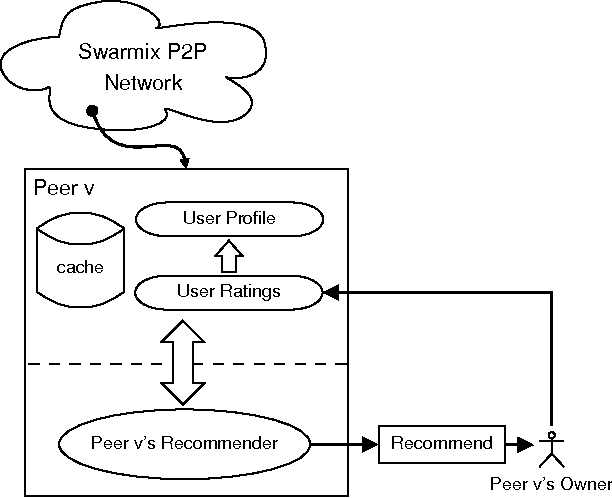

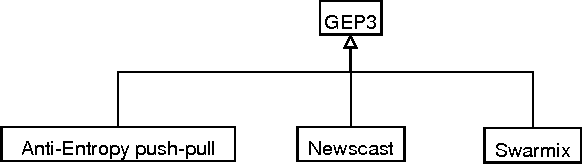

The advent of the Semantic Web necessitates paradigm shifts away from centralized client/server architectures towards decentralization and peer-to-peer computation, making the existence of central authorities superfluous and even impossible. At the same time, recommender systems are gaining considerable impact in e-commerce, providing people with recommendations that are personalized and tailored to their very needs. These recommender systems have traditionally been deployed with stark centralized scenarios in mind, operating in closed communities detached from their host network's outer perimeter. We aim at marrying these two worlds, i.e., decentralized peer-to-peer computing and recommender systems, in one agent-based framework. Our architecture features an epidemic-style protocol maintaining neighborhoods of like-minded peers in a robust, selforganizing fashion. In order to demonstrate our architecture's ability to retain scalability, robustness and to allow for convergence towards high-quality recommendations, we conduct offline experiments on top of the popular MovieLens dataset.
* WWW '05 International Workshop on Innovations in Web Infrastructure (IWI '05) May 10, 2005, Chiba, Japan