 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAtte: Hyperbolic Lorentz Attention for Cross-Subject EEG Classification
Mar 11, 2026Electroencephalogram (EEG) classification is critical for applications ranging from medical diagnostics to brain-computer interfaces, yet it remains challenging due to the inherently low signal-to-noise ratio (SNR) and high inter-subject variability. To address these issues, we propose LAtte, a novel framework that integrates a Lorentz Attention Module with an InceptionTime-based encoder to enable robust and generalizable EEG classification. Unlike prior work, which evaluates primarily on single-subject performance, LAtte focuses on cross-subject training. First, we learn a shared baseline signal across all subjects using pretraining tasks to capture common underlying patterns. Then, we utilize novel Lorentz low-rank adapters to learn subject-specific embeddings that model individual differences. This allows us to learn a shared model that performs robustly across subjects, and can be subsequently finetuned for individual subjects or used to generalize to unseen subjects. We evaluate LAtte on three well-established EEG datasets, achieving a substantial improvement in performance over current state-of-the-art methods.
HPMixer: Hierarchical Patching for Multivariate Time Series Forecasting
Feb 19, 2026In long-term multivariate time series forecasting, effectively capturing both periodic patterns and residual dynamics is essential. To address this within standard deep learning benchmark settings, we propose the Hierarchical Patching Mixer (HPMixer), which models periodicity and residuals in a decoupled yet complementary manner. The periodic component utilizes a learnable cycle module [7] enhanced with a nonlinear channel-wise MLP for greater expressiveness. The residual component is processed through a Learnable Stationary Wavelet Transform (LSWT) to extract stable, shift-invariant frequency-domain representations. Subsequently, a channel-mixing encoder models explicit inter-channel dependencies, while a two-level non-overlapping hierarchical patching mechanism captures coarse- and fine-scale residual variations. By integrating decoupled periodicity modeling with structured, multi-scale residual learning, HPMixer provides an effective framework. Extensive experiments on standard multivariate benchmarks demonstrate that HPMixer achieves competitive or state-of-the-art performance compared to recent baselines.
HexFormer: Hyperbolic Vision Transformer with Exponential Map Aggregation
Jan 27, 2026Data across modalities such as images, text, and graphs often contains hierarchical and relational structures, which are challenging to model within Euclidean geometry. Hyperbolic geometry provides a natural framework for representing such structures. Building on this property, this work introduces HexFormer, a hyperbolic vision transformer for image classification that incorporates exponential map aggregation within its attention mechanism. Two designs are explored: a hyperbolic ViT (HexFormer) and a hybrid variant (HexFormer-Hybrid) that combines a hyperbolic encoder with an Euclidean linear classification head. HexFormer incorporates a novel attention mechanism based on exponential map aggregation, which yields more accurate and stable aggregated representations than standard centroid based averaging, showing that simpler approaches retain competitive merit. Experiments across multiple datasets demonstrate consistent performance improvements over Euclidean baselines and prior hyperbolic ViTs, with the hybrid variant achieving the strongest overall results. Additionally, this study provides an analysis of gradient stability in hyperbolic transformers. The results reveal that hyperbolic models exhibit more stable gradients and reduced sensitivity to warmup strategies compared to Euclidean architectures, highlighting their robustness and efficiency in training. Overall, these findings indicate that hyperbolic geometry can enhance vision transformer architectures by improving gradient stability and accuracy. In addition, relatively simple mechanisms such as exponential map aggregation can provide strong practical benefits.
Recurrent State Encoders for Efficient Neural Combinatorial Optimization
Sep 05, 2025The primary paradigm in Neural Combinatorial Optimization (NCO) are construction methods, where a neural network is trained to sequentially add one solution component at a time until a complete solution is constructed. We observe that the typical changes to the state between two steps are small, since usually only the node that gets added to the solution is removed from the state. An efficient model should be able to reuse computation done in prior steps. To that end, we propose to train a recurrent encoder that computes the state embeddings not only based on the state but also the embeddings of the step before. We show that the recurrent encoder can achieve equivalent or better performance than a non-recurrent encoder even if it consists of $3\times$ fewer layers, thus significantly improving on latency. We demonstrate our findings on three different problems: the Traveling Salesman Problem (TSP), the Capacitated Vehicle Routing Problem (CVRP), and the Orienteering Problem (OP) and integrate the models into a large neighborhood search algorithm, to showcase the practical relevance of our findings.
TabResFlow: A Normalizing Spline Flow Model for Probabilistic Univariate Tabular Regression
Aug 23, 2025



Tabular regression is a well-studied problem with numerous industrial applications, yet most existing approaches focus on point estimation, often leading to overconfident predictions. This issue is particularly critical in industrial automation, where trustworthy decision-making is essential. Probabilistic regression models address this challenge by modeling prediction uncertainty. However, many conventional methods assume a fixed-shape distribution (typically Gaussian), and resort to estimating distribution parameters. This assumption is often restrictive, as real-world target distributions can be highly complex. To overcome this limitation, we introduce TabResFlow, a Normalizing Spline Flow model designed specifically for univariate tabular regression, where commonly used simple flow networks like RealNVP and Masked Autoregressive Flow (MAF) are unsuitable. TabResFlow consists of three key components: (1) An MLP encoder for each numerical feature. (2) A fully connected ResNet backbone for expressive feature extraction. (3) A conditional spline-based normalizing flow for flexible and tractable density estimation. We evaluate TabResFlow on nine public benchmark datasets, demonstrating that it consistently surpasses existing probabilistic regression models on likelihood scores. Our results demonstrate 9.64% improvement compared to the strongest probabilistic regression model (TreeFlow), and on average 5.6 times speed-up in inference time compared to the strongest deep learning alternative (NodeFlow). Additionally, we validate the practical applicability of TabResFlow in a real-world used car price prediction task under selective regression. To measure performance in this setting, we introduce a novel Area Under Risk Coverage (AURC) metric and show that TabResFlow achieves superior results across this metric.
The Role of Active Learning in Modern Machine Learning
Aug 01, 2025


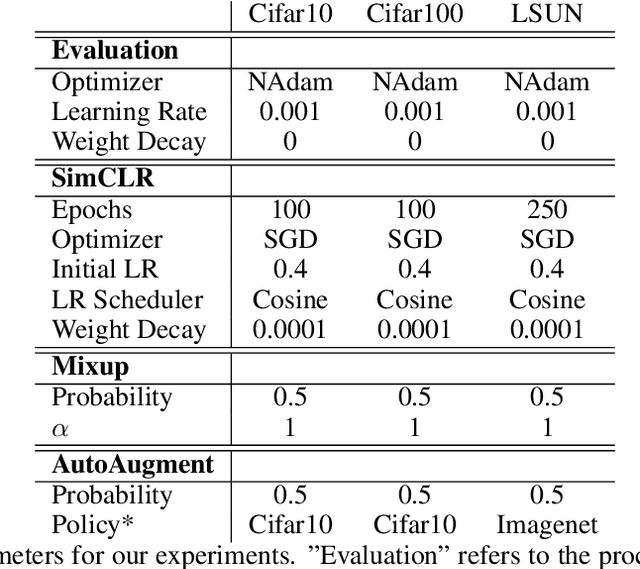
Even though Active Learning (AL) is widely studied, it is rarely applied in contexts outside its own scientific literature. We posit that the reason for this is AL's high computational cost coupled with the comparatively small lifts it is typically able to generate in scenarios with few labeled points. In this work we study the impact of different methods to combat this low data scenario, namely data augmentation (DA), semi-supervised learning (SSL) and AL. We find that AL is by far the least efficient method of solving the low data problem, generating a lift of only 1-4\% over random sampling, while DA and SSL methods can generate up to 60\% lift in combination with random sampling. However, when AL is combined with strong DA and SSL techniques, it surprisingly is still able to provide improvements. Based on these results, we frame AL not as a method to combat missing labels, but as the final building block to squeeze the last bits of performance out of data after appropriate DA and SSL methods as been applied.
STADE: Standard Deviation as a Pruning Metric
Mar 28, 2025Recently, Large Language Models (LLMs) have become very widespread and are used to solve a wide variety of tasks. To successfully handle these tasks, LLMs require longer training times and larger model sizes. This makes LLMs ideal candidates for pruning methods that reduce computational demands while maintaining performance. Previous methods require a retraining phase after pruning to maintain the original model's performance. However, state-of-the-art pruning methods, such as Wanda, prune the model without retraining, making the pruning process faster and more efficient. Building upon Wanda's work, this study provides a theoretical explanation of why the method is effective and leverages these insights to enhance the pruning process. Specifically, a theoretical analysis of the pruning problem reveals a common scenario in Machine Learning where Wanda is the optimal pruning method. Furthermore, this analysis is extended to cases where Wanda is no longer optimal, leading to the development of a new method, STADE, based on the standard deviation of the input. From a theoretical standpoint, STADE demonstrates better generality across different scenarios. Finally, extensive experiments on Llama and Open Pre-trained Transformers (OPT) models validate these theoretical findings, showing that depending on the training conditions, Wanda's optimal performance varies as predicted by the theoretical framework. These insights contribute to a more robust understanding of pruning strategies and their practical implications. Code is available at: https://github.com/Coello-dev/STADE/
IMTS-Mixer: Mixer-Networks for Irregular Multivariate Time Series Forecasting
Feb 17, 2025Forecasting Irregular Multivariate Time Series (IMTS) has recently emerged as a distinct research field, necessitating specialized models to address its unique challenges. While most forecasting literature assumes regularly spaced observations without missing values, many real-world datasets - particularly in healthcare, climate research, and biomechanics - violate these assumptions. Time Series (TS)-mixer models have achieved remarkable success in regular multivariate time series forecasting. However, they remain unexplored for IMTS due to their requirement for complete and evenly spaced observations. To bridge this gap, we introduce IMTS-Mixer, a novel forecasting architecture designed specifically for IMTS. Our approach retains the core principles of TS mixer models while introducing innovative methods to transform IMTS into fixed-size matrix representations, enabling their seamless integration with mixer modules. We evaluate IMTS-Mixer on a benchmark of four real-world datasets from various domains. Our results demonstrate that IMTS-Mixer establishes a new state-of-the-art in forecasting accuracy while also improving computational efficiency.
Physiome-ODE: A Benchmark for Irregularly Sampled Multivariate Time Series Forecasting Based on Biological ODEs
Feb 11, 2025State-of-the-art methods for forecasting irregularly sampled time series with missing values predominantly rely on just four datasets and a few small toy examples for evaluation. While ordinary differential equations (ODE) are the prevalent models in science and engineering, a baseline model that forecasts a constant value outperforms ODE-based models from the last five years on three of these existing datasets. This unintuitive finding hampers further research on ODE-based models, a more plausible model family. In this paper, we develop a methodology to generate irregularly sampled multivariate time series (IMTS) datasets from ordinary differential equations and to select challenging instances via rejection sampling. Using this methodology, we create Physiome-ODE, a large and sophisticated benchmark of IMTS datasets consisting of 50 individual datasets, derived from real-world ordinary differential equations from research in biology. Physiome-ODE is the first benchmark for IMTS forecasting that we are aware of and an order of magnitude larger than the current evaluation setting of four datasets. Using our benchmark Physiome-ODE, we show qualitatively completely different results than those derived from the current four datasets: on Physiome-ODE ODE-based models can play to their strength and our benchmark can differentiate in a meaningful way between different IMTS forecasting models. This way, we expect to give a new impulse to research on ODE-based time series modeling.
Bayesian Active Learning By Distribution Disagreement
Jan 02, 2025
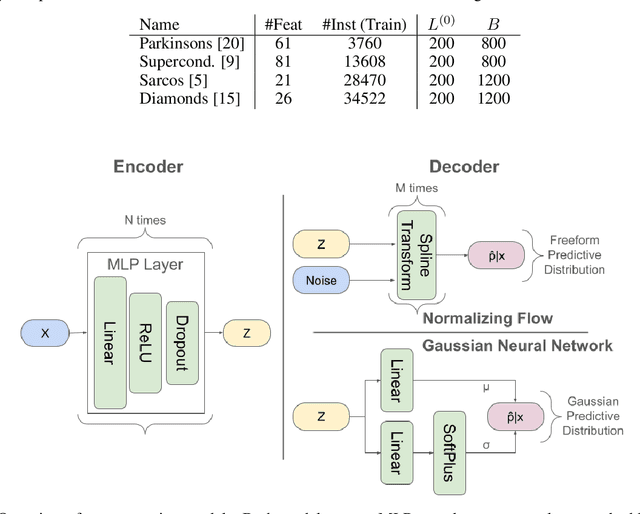
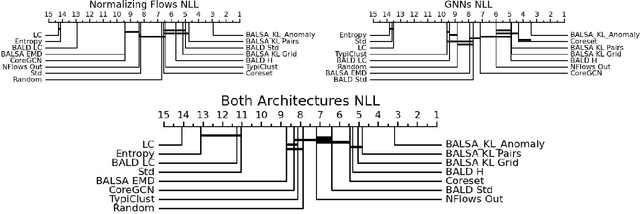
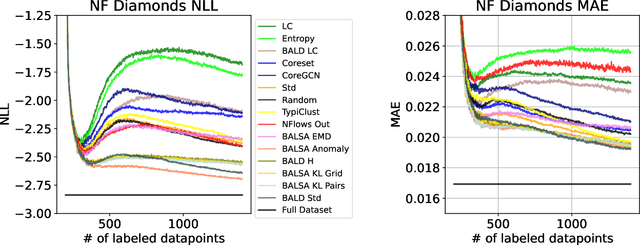
Active Learning (AL) for regression has been systematically under-researched due to the increased difficulty of measuring uncertainty in regression models. Since normalizing flows offer a full predictive distribution instead of a point forecast, they facilitate direct usage of known heuristics for AL like Entropy or Least-Confident sampling. However, we show that most of these heuristics do not work well for normalizing flows in pool-based AL and we need more sophisticated algorithms to distinguish between aleatoric and epistemic uncertainty. In this work we propose BALSA, an adaptation of the BALD algorithm, tailored for regression with normalizing flows. With this work we extend current research on uncertainty quantification with normalizing flows \cite{berry2023normalizing, berry2023escaping} to real world data and pool-based AL with multiple acquisition functions and query sizes. We report SOTA results for BALSA across 4 different datasets and 2 different architectures.