 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent State Encoders for Efficient Neural Combinatorial Optimization
Sep 05, 2025The primary paradigm in Neural Combinatorial Optimization (NCO) are construction methods, where a neural network is trained to sequentially add one solution component at a time until a complete solution is constructed. We observe that the typical changes to the state between two steps are small, since usually only the node that gets added to the solution is removed from the state. An efficient model should be able to reuse computation done in prior steps. To that end, we propose to train a recurrent encoder that computes the state embeddings not only based on the state but also the embeddings of the step before. We show that the recurrent encoder can achieve equivalent or better performance than a non-recurrent encoder even if it consists of $3\times$ fewer layers, thus significantly improving on latency. We demonstrate our findings on three different problems: the Traveling Salesman Problem (TSP), the Capacitated Vehicle Routing Problem (CVRP), and the Orienteering Problem (OP) and integrate the models into a large neighborhood search algorithm, to showcase the practical relevance of our findings.
Moco: A Learnable Meta Optimizer for Combinatorial Optimization
Feb 09, 2024Relevant combinatorial optimization problems (COPs) are often NP-hard. While they have been tackled mainly via handcrafted heuristics in the past, advances in neural networks have motivated the development of general methods to learn heuristics from data. Many approaches utilize a neural network to directly construct a solution, but are limited in further improving based on already constructed solutions at inference time. Our approach, Moco, learns a graph neural network that updates the solution construction procedure based on features extracted from the current search state. This meta training procedure targets the overall best solution found during the search procedure given information such as the search budget. This allows Moco to adapt to varying circumstances such as different computational budgets. Moco is a fully learnable meta optimizer that does not utilize any problem specific local search or decomposition. We test Moco on the Traveling Salesman Problem (TSP) and Maximum Independent Set (MIS) and show that it outperforms other approaches on MIS and is overall competitive on the TSP, especially outperforming related approaches, partially even if they use additional local search.
Routing Arena: A Benchmark Suite for Neural Routing Solvers
Oct 06, 2023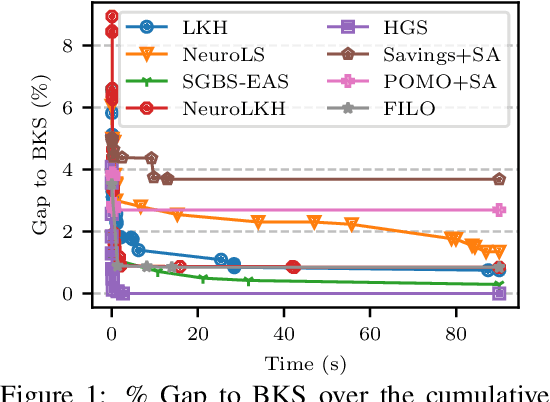
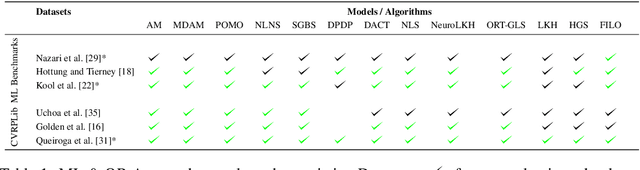
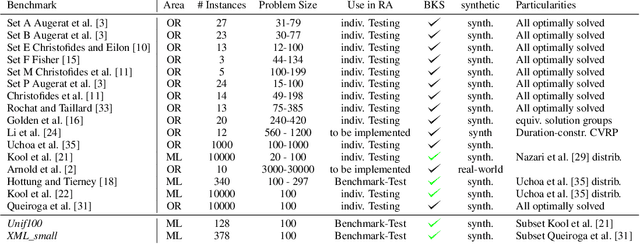
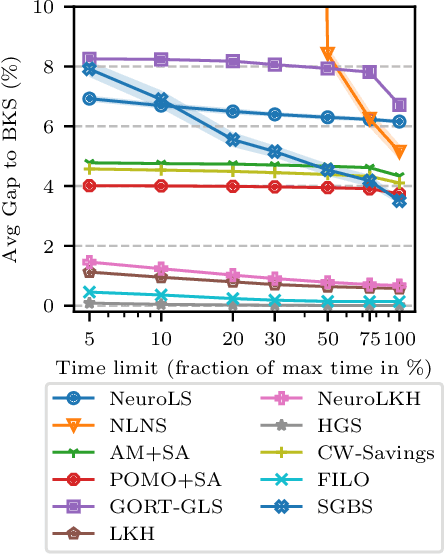
Neural Combinatorial Optimization has been researched actively in the last eight years. Even though many of the proposed Machine Learning based approaches are compared on the same datasets, the evaluation protocol exhibits essential flaws and the selection of baselines often neglects State-of-the-Art Operations Research approaches. To improve on both of these shortcomings, we propose the Routing Arena, a benchmark suite for Routing Problems that provides a seamless integration of consistent evaluation and the provision of baselines and benchmarks prevalent in the Machine Learning- and Operations Research field. The proposed evaluation protocol considers the two most important evaluation cases for different applications: First, the solution quality for an a priori fixed time budget and secondly the anytime performance of the respective methods. By setting the solution trajectory in perspective to a Best Known Solution and a Base Solver's solutions trajectory, we furthermore propose the Weighted Relative Average Performance (WRAP), a novel evaluation metric that quantifies the often claimed runtime efficiency of Neural Routing Solvers. A comprehensive first experimental evaluation demonstrates that the most recent Operations Research solvers generate state-of-the-art results in terms of solution quality and runtime efficiency when it comes to the vehicle routing problem. Nevertheless, some findings highlight the advantages of neural approaches and motivate a shift in how neural solvers should be conceptualized.
DeepStay: Stay Region Extraction from Location Trajectories using Weak Supervision
Jun 05, 2023Nowadays, mobile devices enable constant tracking of the user's position and location trajectories can be used to infer personal points of interest (POIs) like homes, workplaces, or stores. A common way to extract POIs is to first identify spatio-temporal regions where a user spends a significant amount of time, known as stay regions (SRs). Common approaches to SR extraction are evaluated either solely unsupervised or on a small-scale private dataset, as popular public datasets are unlabeled. Most of these methods rely on hand-crafted features or thresholds and do not learn beyond hyperparameter optimization. Therefore, we propose a weakly and self-supervised transformer-based model called DeepStay, which is trained on location trajectories to predict stay regions. To the best of our knowledge, this is the first approach based on deep learning and the first approach that is evaluated on a public, labeled dataset. Our SR extraction method outperforms state-of-the-art methods. In addition, we conducted a limited experiment on the task of transportation mode detection from GPS trajectories using the same architecture and achieved significantly higher scores than the state-of-the-art. Our code is available at https://github.com/christianll9/deepstay.
Learning to Control Local Search for Combinatorial Optimization
Jun 27, 2022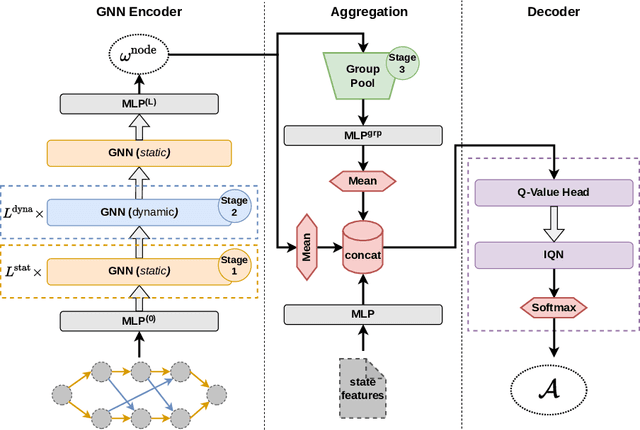
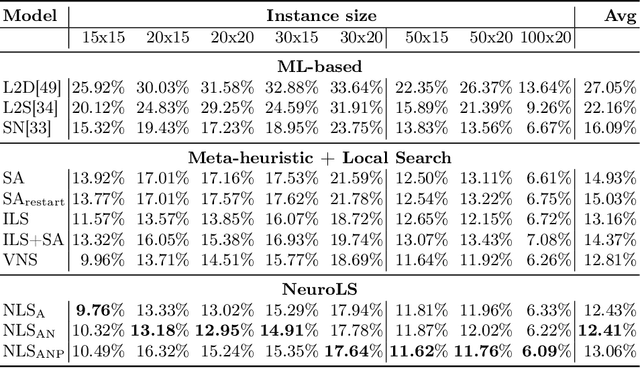
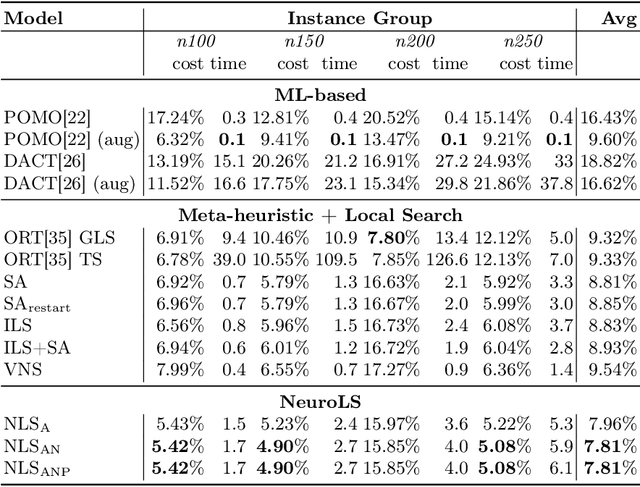
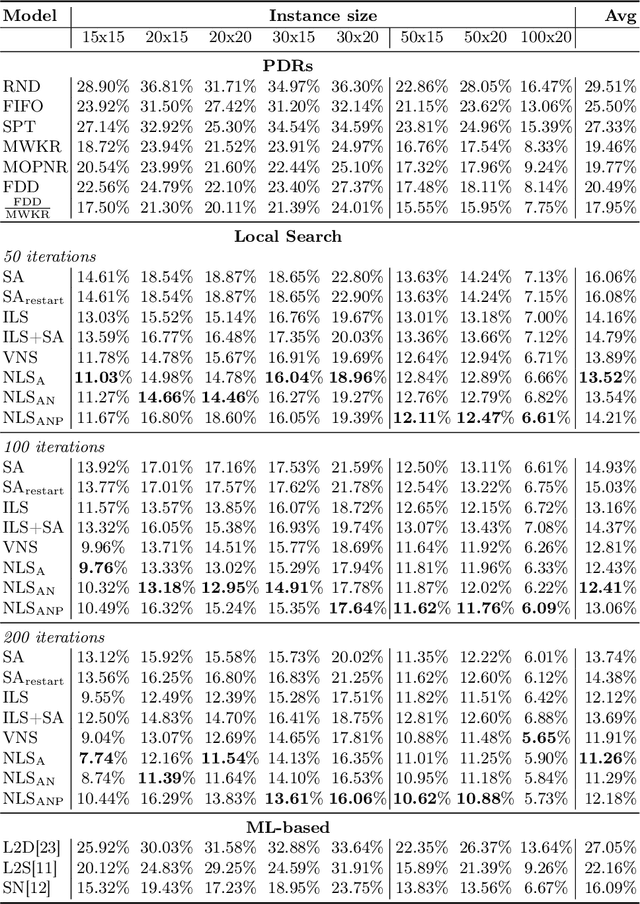
Combinatorial optimization problems are encountered in many practical contexts such as logistics and production, but exact solutions are particularly difficult to find and usually NP-hard for considerable problem sizes. To compute approximate solutions, a zoo of generic as well as problem-specific variants of local search is commonly used. However, which variant to apply to which particular problem is difficult to decide even for experts. In this paper we identify three independent algorithmic aspects of such local search algorithms and formalize their sequential selection over an optimization process as Markov Decision Process (MDP). We design a deep graph neural network as policy model for this MDP, yielding a learned controller for local search called NeuroLS. Ample experimental evidence shows that NeuroLS is able to outperform both, well-known general purpose local search controllers from Operations Research as well as latest machine learning-based approaches.
Large Neighborhood Search based on Neural Construction Heuristics
May 10, 2022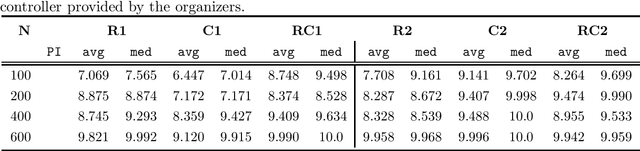
We propose a Large Neighborhood Search (LNS) approach utilizing a learned construction heuristic based on neural networks as repair operator to solve the vehicle routing problem with time windows (VRPTW). Our method uses graph neural networks to encode the problem and auto-regressively decodes a solution and is trained with reinforcement learning on the construction task without requiring any labels for supervision. The neural repair operator is combined with a local search routine, heuristic destruction operators and a selection procedure applied to a small population to arrive at a sophisticated solution approach. The key idea is to use the learned model to re-construct the partially destructed solution and to introduce randomness via the destruction heuristics (or the stochastic policy itself) to effectively explore a large neighborhood.
Supervised Permutation Invariant Networks for Solving the CVRP with Bounded Fleet Size
Jan 05, 2022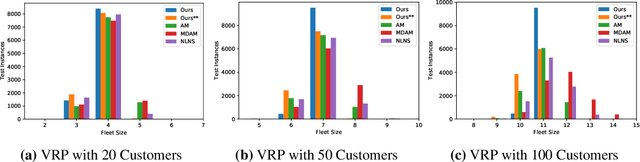
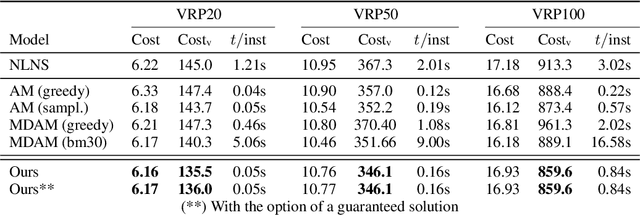
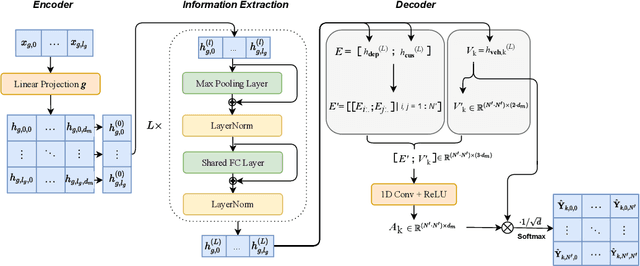
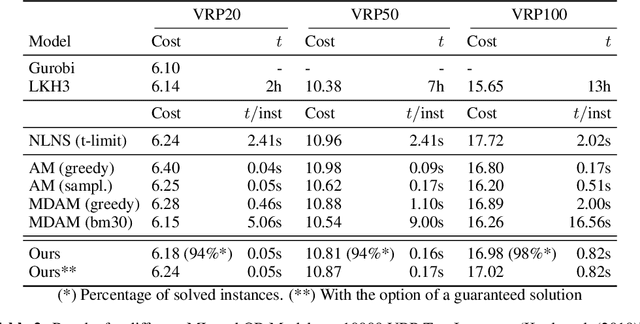
Learning to solve combinatorial optimization problems, such as the vehicle routing problem, offers great computational advantages over classical operations research solvers and heuristics. The recently developed deep reinforcement learning approaches either improve an initially given solution iteratively or sequentially construct a set of individual tours. However, most of the existing learning-based approaches are not able to work for a fixed number of vehicles and thus bypass the complex assignment problem of the customers onto an apriori given number of available vehicles. On the other hand, this makes them less suitable for real applications, as many logistic service providers rely on solutions provided for a specific bounded fleet size and cannot accommodate short term changes to the number of vehicles. In contrast we propose a powerful supervised deep learning framework that constructs a complete tour plan from scratch while respecting an apriori fixed number of available vehicles. In combination with an efficient post-processing scheme, our supervised approach is not only much faster and easier to train but also achieves competitive results that incorporate the practical aspect of vehicle costs. In thorough controlled experiments we compare our method to multiple state-of-the-art approaches where we demonstrate stable performance, while utilizing less vehicles and shed some light on existent inconsistencies in the experimentation protocols of the related work.
Do We Really Need Deep Learning Models for Time Series Forecasting?
Jan 06, 2021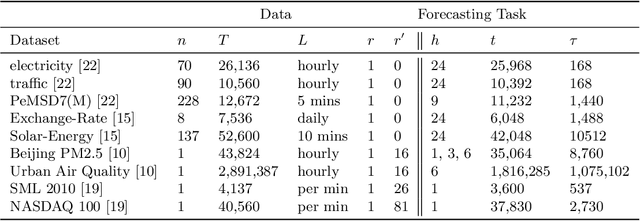

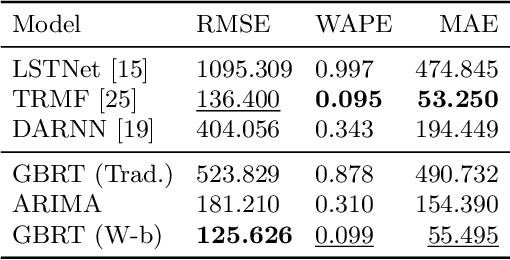
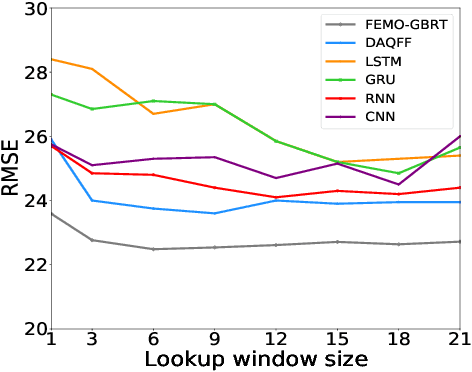
Time series forecasting is a crucial task in machine learning, as it has a wide range of applications including but not limited to forecasting electricity consumption, traffic, and air quality. Traditional forecasting models relied on rolling averages, vector auto-regression and auto-regressive integrated moving averages. On the other hand, deep learning and matrix factorization models have been recently proposed to tackle the same problem with more competitive performance. However, one major drawback of such models is that they tend to be overly complex in comparison to traditional techniques. In this paper, we try to answer whether these highly complex deep learning models are without alternative. We aim to enrich the pool of simple but powerful baselines by revisiting the gradient boosting regression trees for time series forecasting. Specifically, we reconfigure the way time series data is handled by Gradient Tree Boosting models in a windowed fashion that is similar to the deep learning models. For each training window, the target values are concatenated with external features, and then flattened to form one input instance for a multi-output gradient boosting regression tree model. We conducted a comparative study on nine datasets for eight state-of-the-art deep-learning models that were presented at top-level conferences in the last years. The results demonstrated that the proposed approach outperforms all of the state-of-the-art models.