 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabResFlow: A Normalizing Spline Flow Model for Probabilistic Univariate Tabular Regression
Aug 23, 2025



Tabular regression is a well-studied problem with numerous industrial applications, yet most existing approaches focus on point estimation, often leading to overconfident predictions. This issue is particularly critical in industrial automation, where trustworthy decision-making is essential. Probabilistic regression models address this challenge by modeling prediction uncertainty. However, many conventional methods assume a fixed-shape distribution (typically Gaussian), and resort to estimating distribution parameters. This assumption is often restrictive, as real-world target distributions can be highly complex. To overcome this limitation, we introduce TabResFlow, a Normalizing Spline Flow model designed specifically for univariate tabular regression, where commonly used simple flow networks like RealNVP and Masked Autoregressive Flow (MAF) are unsuitable. TabResFlow consists of three key components: (1) An MLP encoder for each numerical feature. (2) A fully connected ResNet backbone for expressive feature extraction. (3) A conditional spline-based normalizing flow for flexible and tractable density estimation. We evaluate TabResFlow on nine public benchmark datasets, demonstrating that it consistently surpasses existing probabilistic regression models on likelihood scores. Our results demonstrate 9.64% improvement compared to the strongest probabilistic regression model (TreeFlow), and on average 5.6 times speed-up in inference time compared to the strongest deep learning alternative (NodeFlow). Additionally, we validate the practical applicability of TabResFlow in a real-world used car price prediction task under selective regression. To measure performance in this setting, we introduce a novel Area Under Risk Coverage (AURC) metric and show that TabResFlow achieves superior results across this metric.
STADE: Standard Deviation as a Pruning Metric
Mar 28, 2025Recently, Large Language Models (LLMs) have become very widespread and are used to solve a wide variety of tasks. To successfully handle these tasks, LLMs require longer training times and larger model sizes. This makes LLMs ideal candidates for pruning methods that reduce computational demands while maintaining performance. Previous methods require a retraining phase after pruning to maintain the original model's performance. However, state-of-the-art pruning methods, such as Wanda, prune the model without retraining, making the pruning process faster and more efficient. Building upon Wanda's work, this study provides a theoretical explanation of why the method is effective and leverages these insights to enhance the pruning process. Specifically, a theoretical analysis of the pruning problem reveals a common scenario in Machine Learning where Wanda is the optimal pruning method. Furthermore, this analysis is extended to cases where Wanda is no longer optimal, leading to the development of a new method, STADE, based on the standard deviation of the input. From a theoretical standpoint, STADE demonstrates better generality across different scenarios. Finally, extensive experiments on Llama and Open Pre-trained Transformers (OPT) models validate these theoretical findings, showing that depending on the training conditions, Wanda's optimal performance varies as predicted by the theoretical framework. These insights contribute to a more robust understanding of pruning strategies and their practical implications. Code is available at: https://github.com/Coello-dev/STADE/
Physiome-ODE: A Benchmark for Irregularly Sampled Multivariate Time Series Forecasting Based on Biological ODEs
Feb 11, 2025State-of-the-art methods for forecasting irregularly sampled time series with missing values predominantly rely on just four datasets and a few small toy examples for evaluation. While ordinary differential equations (ODE) are the prevalent models in science and engineering, a baseline model that forecasts a constant value outperforms ODE-based models from the last five years on three of these existing datasets. This unintuitive finding hampers further research on ODE-based models, a more plausible model family. In this paper, we develop a methodology to generate irregularly sampled multivariate time series (IMTS) datasets from ordinary differential equations and to select challenging instances via rejection sampling. Using this methodology, we create Physiome-ODE, a large and sophisticated benchmark of IMTS datasets consisting of 50 individual datasets, derived from real-world ordinary differential equations from research in biology. Physiome-ODE is the first benchmark for IMTS forecasting that we are aware of and an order of magnitude larger than the current evaluation setting of four datasets. Using our benchmark Physiome-ODE, we show qualitatively completely different results than those derived from the current four datasets: on Physiome-ODE ODE-based models can play to their strength and our benchmark can differentiate in a meaningful way between different IMTS forecasting models. This way, we expect to give a new impulse to research on ODE-based time series modeling.
A Cross-Domain Benchmark for Active Learning
Aug 01, 2024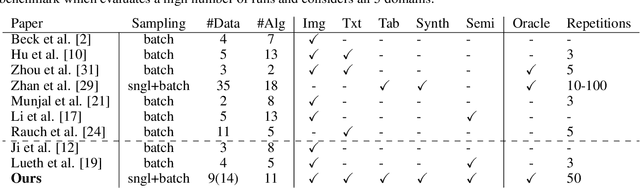
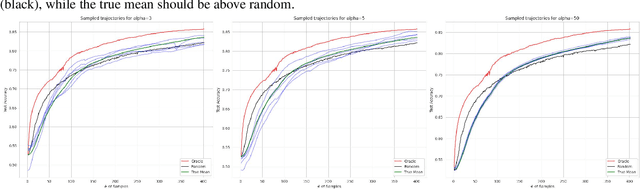
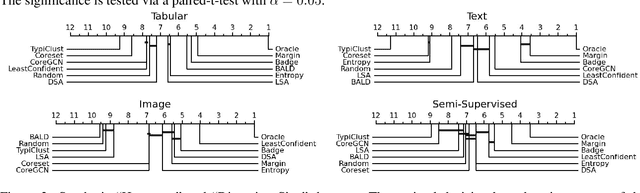
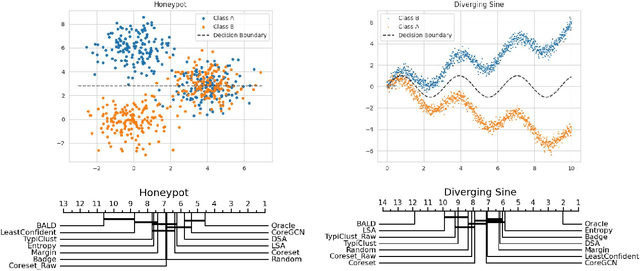
Active Learning (AL) deals with identifying the most informative samples for labeling to reduce data annotation costs for supervised learning tasks. AL research suffers from the fact that lifts from literature generalize poorly and that only a small number of repetitions of experiments are conducted. To overcome these obstacles, we propose \emph{CDALBench}, the first active learning benchmark which includes tasks in computer vision, natural language processing and tabular learning. Furthermore, by providing an efficient, greedy oracle, \emph{CDALBench} can be evaluated with 50 runs for each experiment. We show, that both the cross-domain character and a large amount of repetitions are crucial for sophisticated evaluation of AL research. Concretely, we show that the superiority of specific methods varies over the different domains, making it important to evaluate Active Learning with a cross-domain benchmark. Additionally, we show that having a large amount of runs is crucial. With only conducting three runs as often done in the literature, the superiority of specific methods can strongly vary with the specific runs. This effect is so strong, that, depending on the seed, even a well-established method's performance can be significantly better and significantly worse than random for the same dataset.
Functional Latent Dynamics for Irregularly Sampled Time Series Forecasting
May 06, 2024Irregularly sampled time series with missing values are often observed in multiple real-world applications such as healthcare, climate and astronomy. They pose a significant challenge to standard deep learn- ing models that operate only on fully observed and regularly sampled time series. In order to capture the continuous dynamics of the irreg- ular time series, many models rely on solving an Ordinary Differential Equation (ODE) in the hidden state. These ODE-based models tend to perform slow and require large memory due to sequential operations and a complex ODE solver. As an alternative to complex ODE-based mod- els, we propose a family of models called Functional Latent Dynamics (FLD). Instead of solving the ODE, we use simple curves which exist at all time points to specify the continuous latent state in the model. The coefficients of these curves are learned only from the observed values in the time series ignoring the missing values. Through extensive experi- ments, we demonstrate that FLD achieves better performance compared to the best ODE-based model while reducing the runtime and memory overhead. Specifically, FLD requires an order of magnitude less time to infer the forecasts compared to the best performing forecasting model.
Are EEG Sequences Time Series? EEG Classification with Time Series Models and Joint Subject Training
Apr 10, 2024



As with most other data domains, EEG data analysis relies on rich domain-specific preprocessing. Beyond such preprocessing, machine learners would hope to deal with such data as with any other time series data. For EEG classification many models have been developed with layer types and architectures we typically do not see in time series classification. Furthermore, typically separate models for each individual subject are learned, not one model for all of them. In this paper, we systematically study the differences between EEG classification models and generic time series classification models. We describe three different model setups to deal with EEG data from different subjects, subject-specific models (most EEG literature), subject-agnostic models and subject-conditional models. In experiments on three datasets, we demonstrate that off-the-shelf time series classification models trained per subject perform close to EEG classification models, but that do not quite reach the performance of domain-specific modeling. Additionally, we combine time-series models with subject embeddings to train one joint subject-conditional classifier on all subjects. The resulting models are competitive with dedicated EEG models in 2 out of 3 datasets, even outperforming all EEG methods on one of them.
Reproducibility and Geometric Intrinsic Dimensionality: An Investigation on Graph Neural Network Research
Mar 19, 2024Difficulties in replication and reproducibility of empirical evidences in machine learning research have become a prominent topic in recent years. Ensuring that machine learning research results are sound and reliable requires reproducibility, which verifies the reliability of research findings using the same code and data. This promotes open and accessible research, robust experimental workflows, and the rapid integration of new findings. Evaluating the degree to which research publications support these different aspects of reproducibility is one goal of the present work. For this we introduce an ontology of reproducibility in machine learning and apply it to methods for graph neural networks. Building on these efforts we turn towards another critical challenge in machine learning, namely the curse of dimensionality, which poses challenges in data collection, representation, and analysis, making it harder to find representative data and impeding the training and inference processes. Using the closely linked concept of geometric intrinsic dimension we investigate to which extend the used machine learning models are influenced by the intrinsic dimension of the data sets they are trained on.
ProbSAINT: Probabilistic Tabular Regression for Used Car Pricing
Mar 06, 2024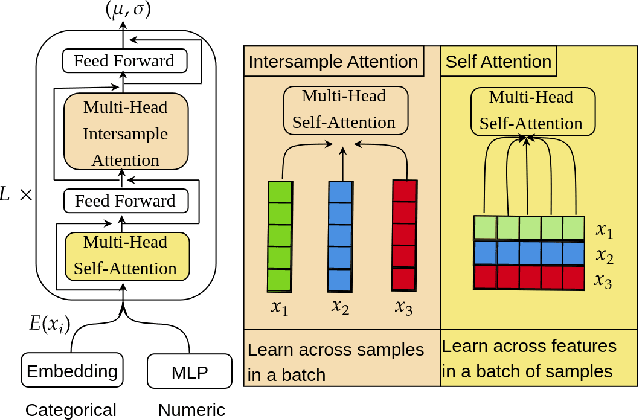
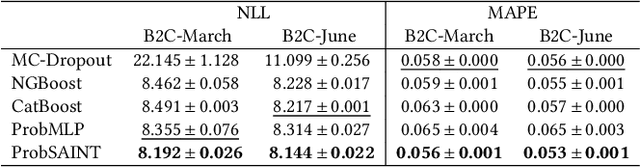
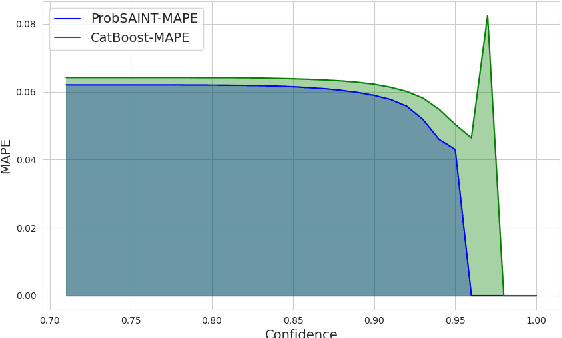
Used car pricing is a critical aspect of the automotive industry, influenced by many economic factors and market dynamics. With the recent surge in online marketplaces and increased demand for used cars, accurate pricing would benefit both buyers and sellers by ensuring fair transactions. However, the transition towards automated pricing algorithms using machine learning necessitates the comprehension of model uncertainties, specifically the ability to flag predictions that the model is unsure about. Although recent literature proposes the use of boosting algorithms or nearest neighbor-based approaches for swift and precise price predictions, encapsulating model uncertainties with such algorithms presents a complex challenge. We introduce ProbSAINT, a model that offers a principled approach for uncertainty quantification of its price predictions, along with accurate point predictions that are comparable to state-of-the-art boosting techniques. Furthermore, acknowledging that the business prefers pricing used cars based on the number of days the vehicle was listed for sale, we show how ProbSAINT can be used as a dynamic forecasting model for predicting price probabilities for different expected offer duration. Our experiments further indicate that ProbSAINT is especially accurate on instances where it is highly certain. This proves the applicability of its probabilistic predictions in real-world scenarios where trustworthiness is crucial.
Moco: A Learnable Meta Optimizer for Combinatorial Optimization
Feb 09, 2024Relevant combinatorial optimization problems (COPs) are often NP-hard. While they have been tackled mainly via handcrafted heuristics in the past, advances in neural networks have motivated the development of general methods to learn heuristics from data. Many approaches utilize a neural network to directly construct a solution, but are limited in further improving based on already constructed solutions at inference time. Our approach, Moco, learns a graph neural network that updates the solution construction procedure based on features extracted from the current search state. This meta training procedure targets the overall best solution found during the search procedure given information such as the search budget. This allows Moco to adapt to varying circumstances such as different computational budgets. Moco is a fully learnable meta optimizer that does not utilize any problem specific local search or decomposition. We test Moco on the Traveling Salesman Problem (TSP) and Maximum Independent Set (MIS) and show that it outperforms other approaches on MIS and is overall competitive on the TSP, especially outperforming related approaches, partially even if they use additional local search.
Selecting Features by their Resilience to the Curse of Dimensionality
Apr 17, 2023Real-world datasets are often of high dimension and effected by the curse of dimensionality. This hinders their comprehensibility and interpretability. To reduce the complexity feature selection aims to identify features that are crucial to learn from said data. While measures of relevance and pairwise similarities are commonly used, the curse of dimensionality is rarely incorporated into the process of selecting features. Here we step in with a novel method that identifies the features that allow to discriminate data subsets of different sizes. By adapting recent work on computing intrinsic dimensionalities, our method is able to select the features that can discriminate data and thus weaken the curse of dimensionality. Our experiments show that our method is competitive and commonly outperforms established feature selection methods. Furthermore, we propose an approximation that allows our method to scale to datasets consisting of millions of data points. Our findings suggest that features that discriminate data and are connected to a low intrinsic dimensionality are meaningful for learning procedures.