 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysiome-ODE: A Benchmark for Irregularly Sampled Multivariate Time Series Forecasting Based on Biological ODEs
Feb 11, 2025State-of-the-art methods for forecasting irregularly sampled time series with missing values predominantly rely on just four datasets and a few small toy examples for evaluation. While ordinary differential equations (ODE) are the prevalent models in science and engineering, a baseline model that forecasts a constant value outperforms ODE-based models from the last five years on three of these existing datasets. This unintuitive finding hampers further research on ODE-based models, a more plausible model family. In this paper, we develop a methodology to generate irregularly sampled multivariate time series (IMTS) datasets from ordinary differential equations and to select challenging instances via rejection sampling. Using this methodology, we create Physiome-ODE, a large and sophisticated benchmark of IMTS datasets consisting of 50 individual datasets, derived from real-world ordinary differential equations from research in biology. Physiome-ODE is the first benchmark for IMTS forecasting that we are aware of and an order of magnitude larger than the current evaluation setting of four datasets. Using our benchmark Physiome-ODE, we show qualitatively completely different results than those derived from the current four datasets: on Physiome-ODE ODE-based models can play to their strength and our benchmark can differentiate in a meaningful way between different IMTS forecasting models. This way, we expect to give a new impulse to research on ODE-based time series modeling.
Marginalization Consistent Mixture of Separable Flows for Probabilistic Irregular Time Series Forecasting
Jun 11, 2024



Probabilistic forecasting models for joint distributions of targets in irregular time series are a heavily under-researched area in machine learning with, to the best of our knowledge, only three models researched so far: GPR, the Gaussian Process Regression model~\citep{Durichen2015.Multitask}, TACTiS, the Transformer-Attentional Copulas for Time Series~\cite{Drouin2022.Tactis, ashok2024tactis} and ProFITi \citep{Yalavarthi2024.Probabilistica}, a multivariate normalizing flow model based on invertible attention layers. While ProFITi, thanks to using multivariate normalizing flows, is the more expressive model with better predictive performance, we will show that it suffers from marginalization inconsistency: it does not guarantee that the marginal distributions of a subset of variables in its predictive distributions coincide with the directly predicted distributions of these variables. Also, TACTiS does not provide any guarantees for marginalization consistency. We develop a novel probabilistic irregular time series forecasting model, Marginalization Consistent Mixtures of Separable Flows (moses), that mixes several normalizing flows with (i) Gaussian Processes with full covariance matrix as source distributions and (ii) a separable invertible transformation, aiming to combine the expressivity of normalizing flows with the marginalization consistency of Gaussians. In experiments on four different datasets we show that moses outperforms other state-of-the-art marginalization consistent models, performs on par with ProFITi, but different from ProFITi, guarantee marginalization consistency.
Probabilistic Forecasting of Irregular Time Series via Conditional Flows
Feb 09, 2024



Probabilistic forecasting of irregularly sampled multivariate time series with missing values is an important problem in many fields, including health care, astronomy, and climate. State-of-the-art methods for the task estimate only marginal distributions of observations in single channels and at single timepoints, assuming a fixed-shape parametric distribution. In this work, we propose a novel model, ProFITi, for probabilistic forecasting of irregularly sampled time series with missing values using conditional normalizing flows. The model learns joint distributions over the future values of the time series conditioned on past observations and queried channels and times, without assuming any fixed shape of the underlying distribution. As model components, we introduce a novel invertible triangular attention layer and an invertible non-linear activation function on and onto the whole real line. We conduct extensive experiments on four datasets and demonstrate that the proposed model provides $4$ times higher likelihood over the previously best model.
Put Attention to Temporal Saliency Patterns of Multi-Horizon Time Series
Dec 15, 2022Time series, sets of sequences in chronological order, are essential data in statistical research with many forecasting applications. Although recent performance in many Transformer-based models has been noticeable, long multi-horizon time series forecasting remains a very challenging task. Going beyond transformers in sequence translation and transduction research, we observe the effects of down-and-up samplings that can nudge temporal saliency patterns to emerge in time sequences. Motivated by the mentioned observation, in this paper, we propose a novel architecture, Temporal Saliency Detection (TSD), on top of the attention mechanism and apply it to multi-horizon time series prediction. We renovate the traditional encoder-decoder architecture by making as a series of deep convolutional blocks to work in tandem with the multi-head self-attention. The proposed TSD approach facilitates the multiresolution of saliency patterns upon condensed multi-heads, thus progressively enhancing complex time series forecasting. Experimental results illustrate that our proposed approach has significantly outperformed existing state-of-the-art methods across multiple standard benchmark datasets in many far-horizon forecasting settings. Overall, TSD achieves 31% and 46% relative improvement over the current state-of-the-art models in multivariate and univariate time series forecasting scenarios on standard benchmarks. The Git repository is available at https://github.com/duongtrung/time-series-temporal-saliency-patterns.
When Bioprocess Engineering Meets Machine Learning: A Survey from the Perspective of Automated Bioprocess Development
Sep 02, 2022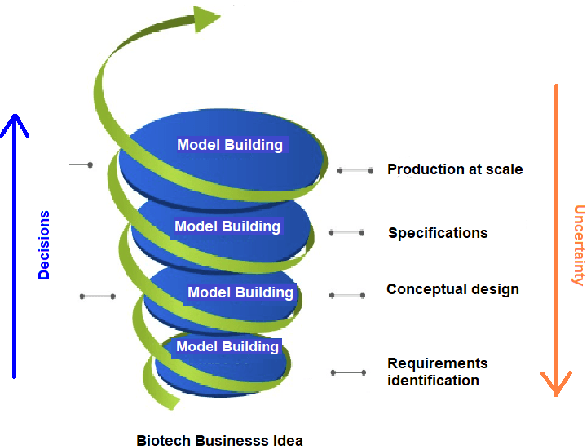
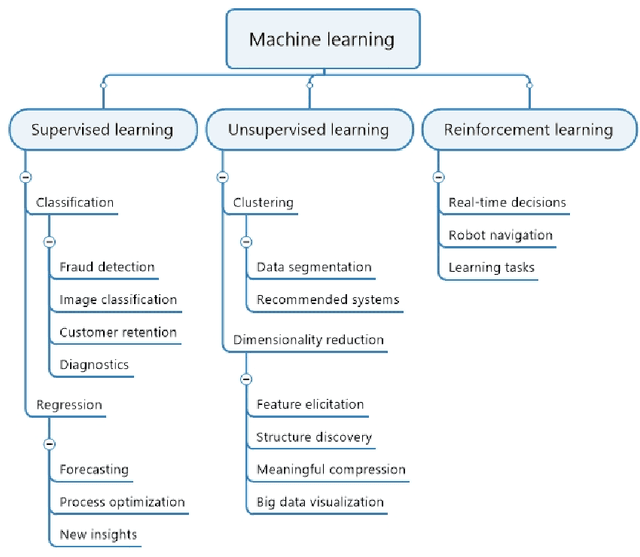
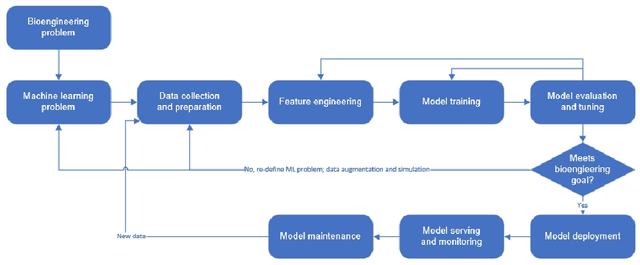
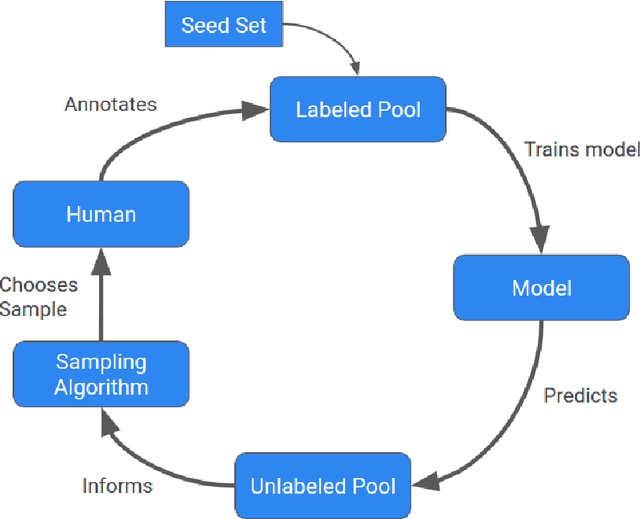
Machine learning (ML) has significantly contributed to the development of bioprocess engineering, but its application is still limited, hampering the enormous potential for bioprocess automation. ML for model building automation can be seen as a way of introducing another level of abstraction to focus expert humans in the most cognitive tasks of bioprocess development. First, probabilistic programming is used for the autonomous building of predictive models. Second, machine learning automatically assesses alternative decisions by planning experiments to test hypotheses and conducting investigations to gather informative data that focus on model selection based on the uncertainty of model predictions. This review provides a comprehensive overview of ML-based automation in bioprocess development. On the one hand, the biotech and bioengineering community should be aware of the potential and, most importantly, the limitation of existing ML solutions for their application in biotechnology and biopharma. On the other hand, it is essential to identify the missing links to enable the easy implementation of ML and Artificial Intelligence (AI) solutions in valuable solutions for the bio-community. We summarize recent ML implementation across several important subfields of bioprocess systems and raise two crucial challenges remaining the bottleneck of bioprocess automation and reducing uncertainty in biotechnology development. There is no one-fits-all procedure; however, this review should help identify the potential automation combining biotechnology and ML domains.
Deep Metric Learning for Ground Images
Sep 03, 2021
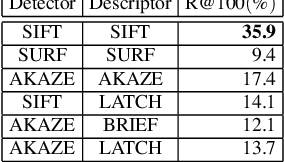


Ground texture based localization methods are potential prospects for low-cost, high-accuracy self-localization solutions for robots. These methods estimate the pose of a given query image, i.e. the current observation of the ground from a downward-facing camera, in respect to a set of reference images whose poses are known in the application area. In this work, we deal with the initial localization task, in which we have no prior knowledge about the current robot positioning. In this situation, the localization method would have to consider all available reference images. However, in order to reduce computational effort and the risk of receiving a wrong result, we would like to consider only those reference images that are actually overlapping with the query image. For this purpose, we propose a deep metric learning approach that retrieves the most similar reference images to the query image. In contrast to existing approaches to image retrieval for ground images, our approach achieves significantly better recall performance and improves the localization performance of a state-of-the-art ground texture based localization method.
Multi-script Handwritten Digit Recognition Using Multi-task Learning
Jun 15, 2021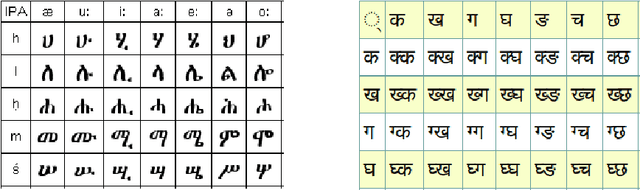



Handwritten digit recognition is one of the extensively studied area in machine learning. Apart from the wider research on handwritten digit recognition on MNIST dataset, there are many other research works on various script recognition. However, it is not very common for multi-script digit recognition which encourage the development of robust and multipurpose systems. Additionally working on multi-script digit recognition enables multi-task learning, considering the script classification as a related task for instance. It is evident that multi-task learning improves model performance through inductive transfer using the information contained in related tasks. Therefore, in this study multi-script handwritten digit recognition using multi-task learning will be investigated. As a specific case of demonstrating the solution to the problem, Amharic handwritten character recognition will also be experimented. The handwritten digits of three scripts including Latin, Arabic and Kannada are studied to show that multi-task models with reformulation of the individual tasks have shown promising results. In this study a novel way of using the individual tasks predictions was proposed to help classification performance and regularize the different loss for the purpose of the main task. This finding has outperformed the baseline and the conventional multi-task learning models. More importantly, it avoided the need for weighting the different losses of the tasks, which is one of the challenges in multi-task learning.
Improving Sample Efficiency with Normalized RBF Kernels
Jul 31, 2020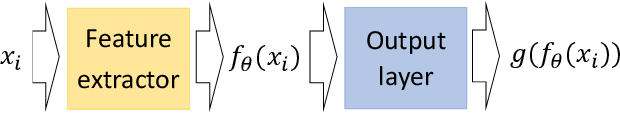
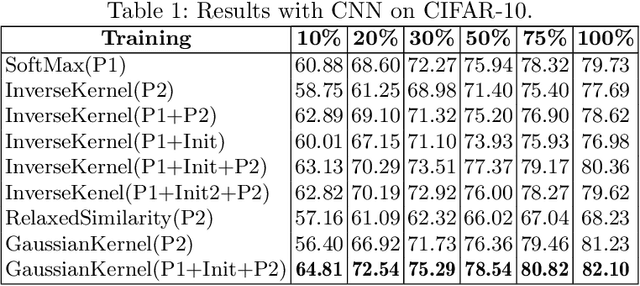
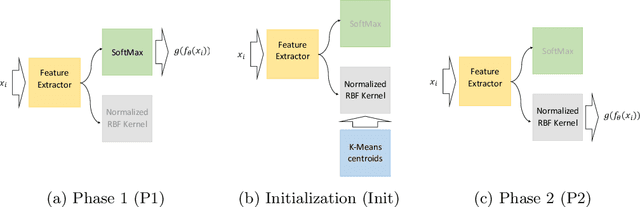
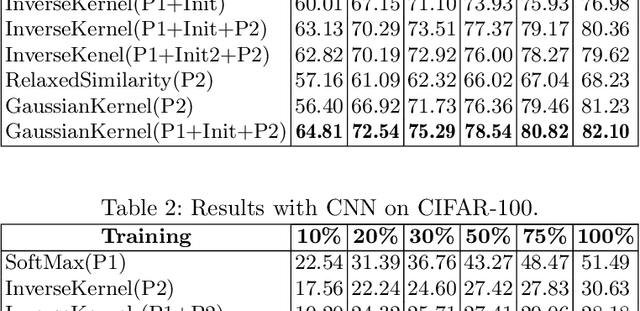
In deep learning models, learning more with less data is becoming more important. This paper explores how neural networks with normalized Radial Basis Function (RBF) kernels can be trained to achieve better sample efficiency. Moreover, we show how this kind of output layer can find embedding spaces where the classes are compact and well-separated. In order to achieve this, we propose a two-phase method to train those type of neural networks on classification tasks. Experiments on CIFAR-10 and CIFAR-100 show that networks with normalized kernels as output layer can achieve higher sample efficiency, high compactness and well-separability through the presented method in comparison to networks with SoftMax output layer.
Chameleon: Learning Model Initializations Across Tasks With Different Schemas
Oct 01, 2019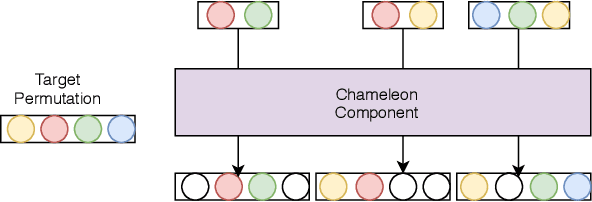
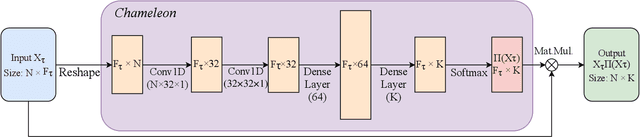
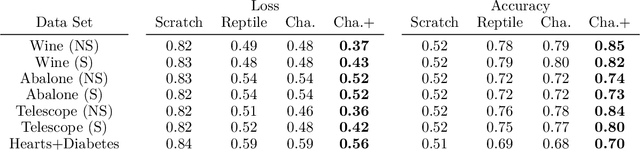
Parametric models, and particularly neural networks, require weight initialization as a starting point for gradient-based optimization. In most current practices, this is accomplished by using some form of random initialization. Instead, recent work shows that a specific initial parameter set can be learned from a population of tasks, i.e., dataset and target variable for supervised learning tasks. Using this initial parameter set leads to faster convergence for new tasks (model-agnostic meta-learning). Currently, methods for learning model initializations are limited to a population of tasks sharing the same schema, i.e., the same number, order, type and semantics of predictor and target variables. In this paper, we address the problem of meta-learning parameter initialization across tasks with different schemas, i.e., if the number of predictors varies across tasks, while they still share some variables. We propose Chameleon, a model that learns to align different predictor schemas to a common representation. We use permutations and masks of the predictors of the training tasks at hand. In experiments on real-life data sets, we show that Chameleon successfully can learn parameter initializations across tasks with different schemas providing a 26% lift on accuracy on average over random initialization and of 5% over a state-of-the-art method for fixed-schema learning model initializations. To the best of our knowledge, our paper is the first work on the problem of learning model initialization across tasks with different schemas.
Learning Surrogate Losses
May 24, 2019

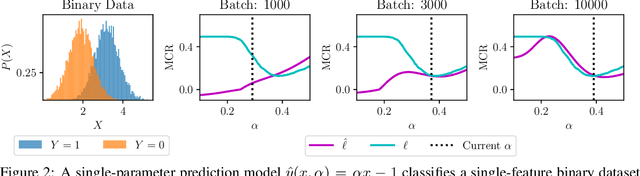

The minimization of loss functions is the heart and soul of Machine Learning. In this paper, we propose an off-the-shelf optimization approach that can minimize virtually any non-differentiable and non-decomposable loss function (e.g. Miss-classification Rate, AUC, F1, Jaccard Index, Mathew Correlation Coefficient, etc.) seamlessly. Our strategy learns smooth relaxation versions of the true losses by approximating them through a surrogate neural network. The proposed loss networks are set-wise models which are invariant to the order of mini-batch instances. Ultimately, the surrogate losses are learned jointly with the prediction model via bilevel optimization. Empirical results on multiple datasets with diverse real-life loss functions compared with state-of-the-art baselines demonstrate the efficiency of learning surrogate losses.