 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Amharic Handwritten Word Recognition Using Auxiliary Task
Feb 25, 2022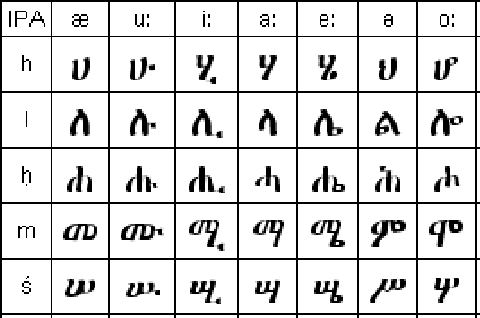
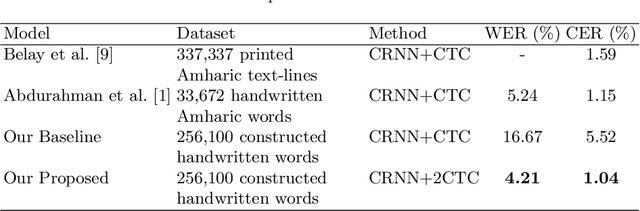

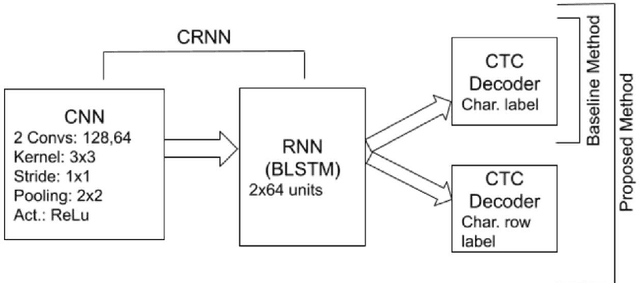
Amharic is one of the official languages of the Federal Democratic Republic of Ethiopia. It is one of the languages that use an Ethiopic script which is derived from Gee'z, ancient and currently a liturgical language. Amharic is also one of the most widely used literature-rich languages of Ethiopia. There are very limited innovative and customized research works in Amharic optical character recognition (OCR) in general and Amharic handwritten text recognition in particular. In this study, Amharic handwritten word recognition will be investigated. State-of-the-art deep learning techniques including convolutional neural networks together with recurrent neural networks and connectionist temporal classification (CTC) loss were used to make the recognition in an end-to-end fashion. More importantly, an innovative way of complementing the loss function using the auxiliary task from the row-wise similarities of the Amharic alphabet was tested to show a significant recognition improvement over a baseline method. Such findings will promote innovative problem-specific solutions as well as will open insight to a generalized solution that emerges from problem-specific domains.
Multi-script Handwritten Digit Recognition Using Multi-task Learning
Jun 15, 2021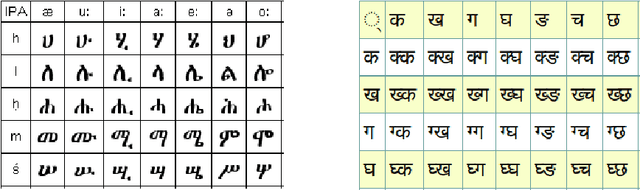



Handwritten digit recognition is one of the extensively studied area in machine learning. Apart from the wider research on handwritten digit recognition on MNIST dataset, there are many other research works on various script recognition. However, it is not very common for multi-script digit recognition which encourage the development of robust and multipurpose systems. Additionally working on multi-script digit recognition enables multi-task learning, considering the script classification as a related task for instance. It is evident that multi-task learning improves model performance through inductive transfer using the information contained in related tasks. Therefore, in this study multi-script handwritten digit recognition using multi-task learning will be investigated. As a specific case of demonstrating the solution to the problem, Amharic handwritten character recognition will also be experimented. The handwritten digits of three scripts including Latin, Arabic and Kannada are studied to show that multi-task models with reformulation of the individual tasks have shown promising results. In this study a novel way of using the individual tasks predictions was proposed to help classification performance and regularize the different loss for the purpose of the main task. This finding has outperformed the baseline and the conventional multi-task learning models. More importantly, it avoided the need for weighting the different losses of the tasks, which is one of the challenges in multi-task learning.