 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation Scheme for Raman Spectra with Highly Correlated Annotations
Feb 01, 2024In biotechnology Raman Spectroscopy is rapidly gaining popularity as a process analytical technology (PAT) that measures cell densities, substrate- and product concentrations. As it records vibrational modes of molecules it provides that information non-invasively in a single spectrum. Typically, partial least squares (PLS) is the model of choice to infer information about variables of interest from the spectra. However, biological processes are known for their complexity where convolutional neural networks (CNN) present a powerful alternative. They can handle non-Gaussian noise and account for beam misalignment, pixel malfunctions or the presence of additional substances. However, they require a lot of data during model training, and they pick up non-linear dependencies in the process variables. In this work, we exploit the additive nature of spectra in order to generate additional data points from a given dataset that have statistically independent labels so that a network trained on such data exhibits low correlations between the model predictions. We show that training a CNN on these generated data points improves the performance on datasets where the annotations do not bear the same correlation as the dataset that was used for model training. This data augmentation technique enables us to reuse spectra as training data for new contexts that exhibit different correlations. The additional data allows for building a better and more robust model. This is of interest in scenarios where large amounts of historical data are available but are currently not used for model training. We demonstrate the capabilities of the proposed method using synthetic spectra of Ralstonia eutropha batch cultivations to monitor substrate, biomass and polyhydroxyalkanoate (PHA) biopolymer concentrations during of the experiments.
Deep Learning for Fast Inference of Mechanistic Models' Parameters
Dec 05, 2023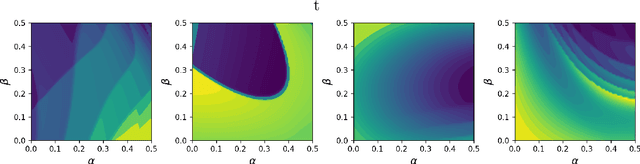
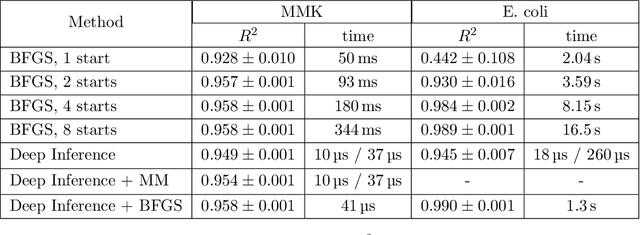
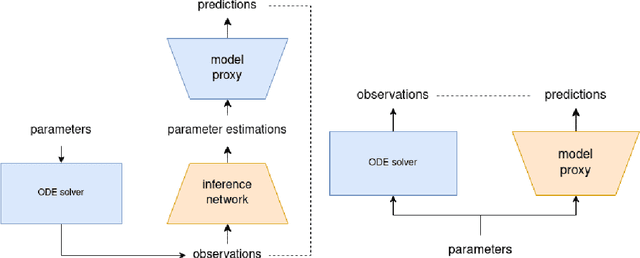
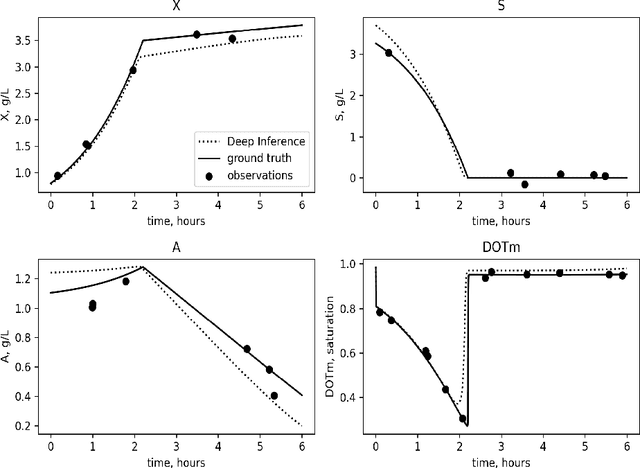
Inferring parameters of macro-kinetic growth models, typically represented by Ordinary Differential Equations (ODE), from the experimental data is a crucial step in bioprocess engineering. Conventionally, estimates of the parameters are obtained by fitting the mechanistic model to observations. Fitting, however, requires a significant computational power. Specifically, during the development of new bioprocesses that use previously unknown organisms or strains, efficient, robust, and computationally cheap methods for parameter estimation are of great value. In this work, we propose using Deep Neural Networks (NN) for directly predicting parameters of mechanistic models given observations. The approach requires spending computational resources for training a NN, nonetheless, once trained, such a network can provide parameter estimates orders of magnitude faster than conventional methods. We consider a training procedure that combines Neural Networks and mechanistic models. We demonstrate the performance of the proposed algorithms on data sampled from several mechanistic models used in bioengineering describing a typical industrial batch process and compare the proposed method, a typical gradient-based fitting procedure, and the combination of the two. We find that, while Neural Network estimates are slightly improved by further fitting, these estimates are measurably better than the fitting procedure alone.
Deep Set Neural Networks for forecasting asynchronous bioprocess timeseries
Dec 05, 2023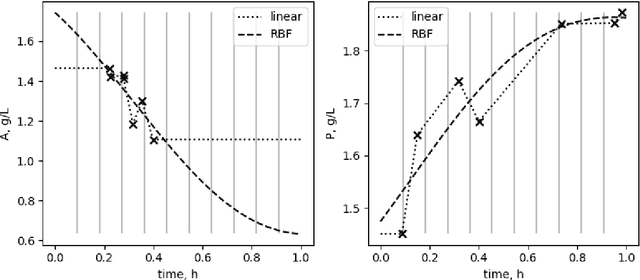
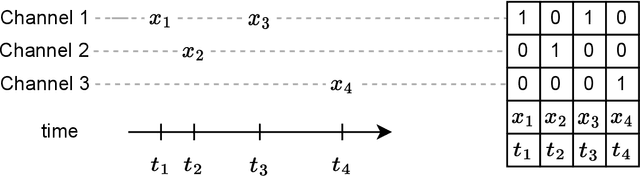
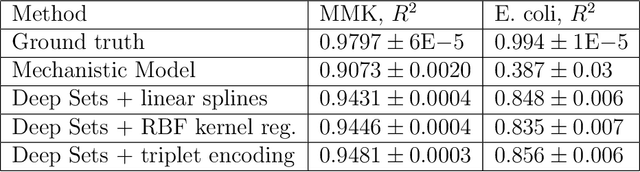
Cultivation experiments often produce sparse and irregular time series. Classical approaches based on mechanistic models, like Maximum Likelihood fitting or Monte-Carlo Markov chain sampling, can easily account for sparsity and time-grid irregularities, but most statistical and Machine Learning tools are not designed for handling sparse data out-of-the-box. Among popular approaches there are various schemes for filling missing values (imputation) and interpolation into a regular grid (alignment). However, such methods transfer the biases of the interpolation or imputation models to the target model. We show that Deep Set Neural Networks equipped with triplet encoding of the input data can successfully handle bio-process data without any need for imputation or alignment procedures. The method is agnostic to the particular nature of the time series and can be adapted for any task, for example, online monitoring, predictive control, design of experiments, etc. In this work, we focus on forecasting. We argue that such an approach is especially suitable for typical cultivation processes, demonstrate the performance of the method on several forecasting tasks using data generated from macrokinetic growth models under realistic conditions, and compare the method to a conventional fitting procedure and methods based on imputation and alignment.
When Bioprocess Engineering Meets Machine Learning: A Survey from the Perspective of Automated Bioprocess Development
Sep 02, 2022
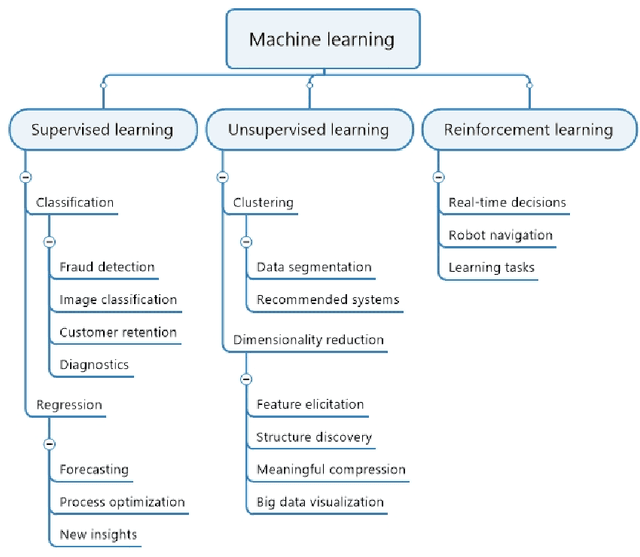
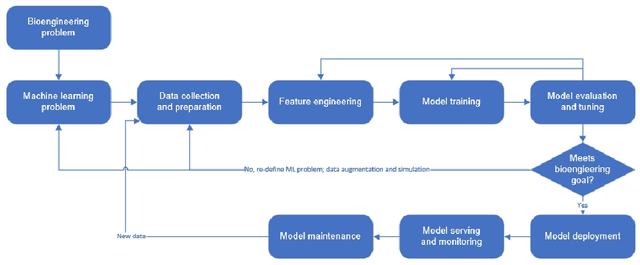
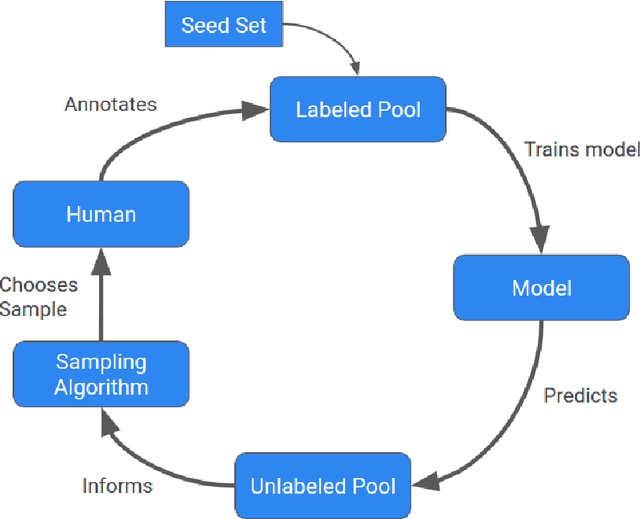
Machine learning (ML) has significantly contributed to the development of bioprocess engineering, but its application is still limited, hampering the enormous potential for bioprocess automation. ML for model building automation can be seen as a way of introducing another level of abstraction to focus expert humans in the most cognitive tasks of bioprocess development. First, probabilistic programming is used for the autonomous building of predictive models. Second, machine learning automatically assesses alternative decisions by planning experiments to test hypotheses and conducting investigations to gather informative data that focus on model selection based on the uncertainty of model predictions. This review provides a comprehensive overview of ML-based automation in bioprocess development. On the one hand, the biotech and bioengineering community should be aware of the potential and, most importantly, the limitation of existing ML solutions for their application in biotechnology and biopharma. On the other hand, it is essential to identify the missing links to enable the easy implementation of ML and Artificial Intelligence (AI) solutions in valuable solutions for the bio-community. We summarize recent ML implementation across several important subfields of bioprocess systems and raise two crucial challenges remaining the bottleneck of bioprocess automation and reducing uncertainty in biotechnology development. There is no one-fits-all procedure; however, this review should help identify the potential automation combining biotechnology and ML domains.
Normalizing flows for deep anomaly detection
Dec 19, 2019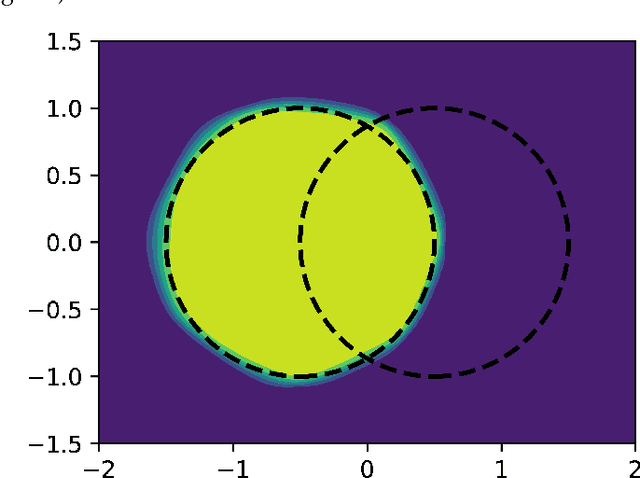
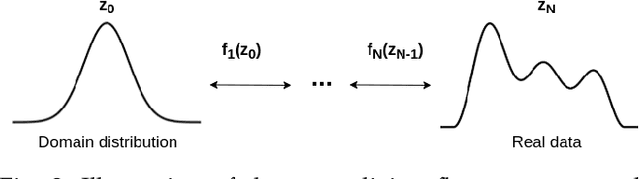
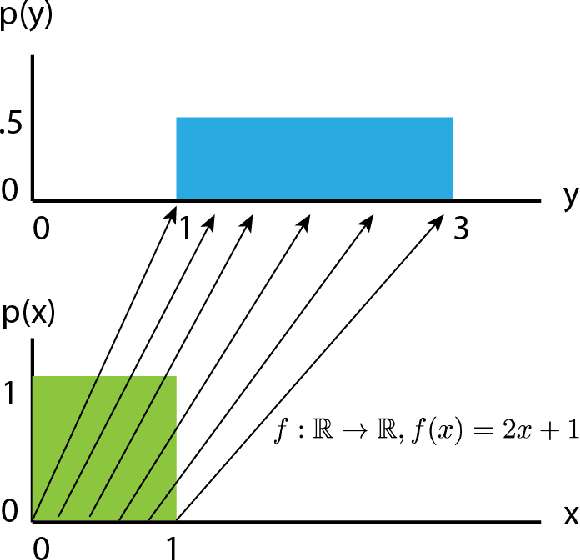
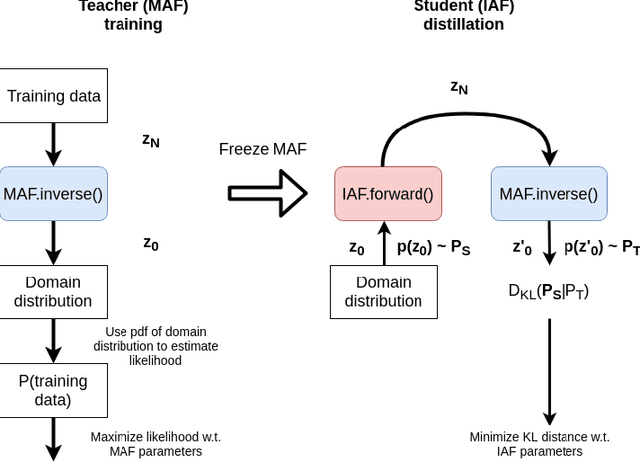
Anomaly detection for complex data is a challenging task from the perspective of machine learning. In this work, weconsider cases with missing certain kinds of anomalies in the training dataset, while significant statistics for the normal class isavailable. For such scenarios, conventional supervised methods might suffer from the class imbalance, while unsupervised methodstend to ignore difficult anomalous examples. We extend the idea of the supervised classification approach for class-imbalanceddatasets by exploiting normalizing flows for proper Bayesian inference of the posterior probabilities.
Adaptive Divergence for Rapid Adversarial Optimization
Dec 01, 2019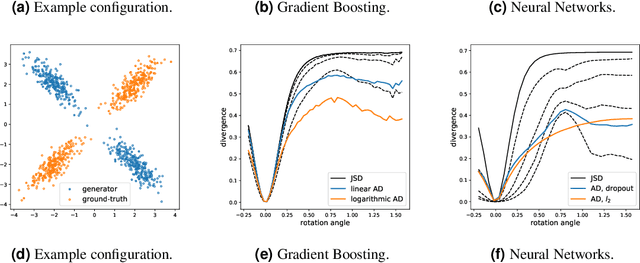
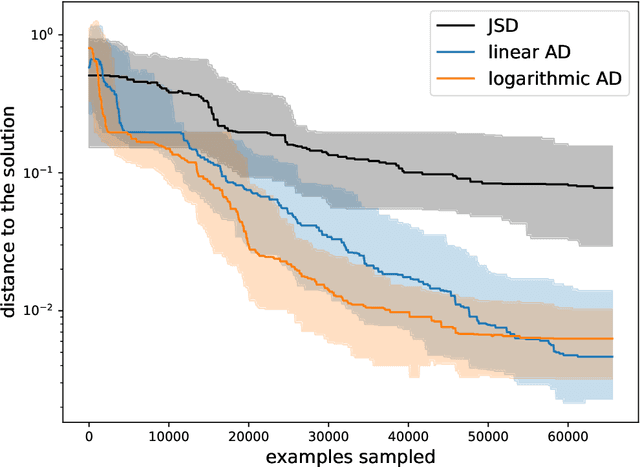
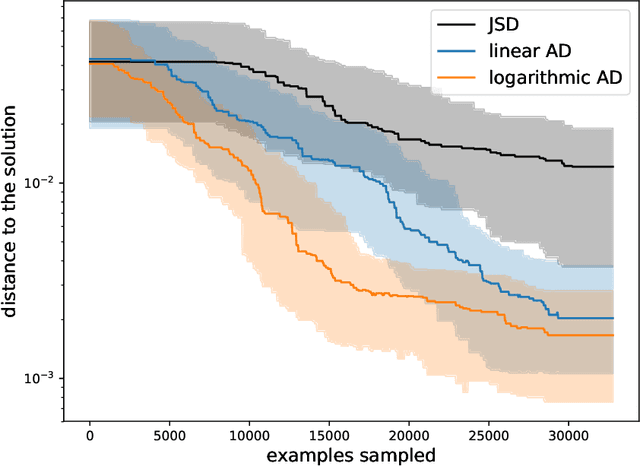
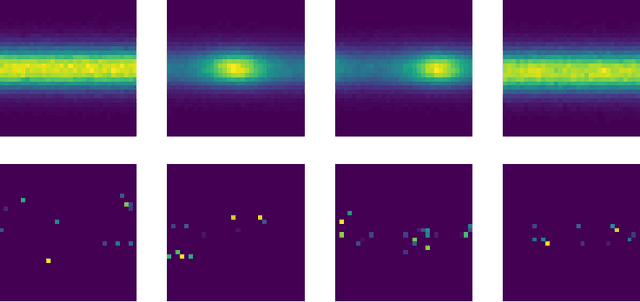
Adversarial Optimization (AO) provides a reliable, practical way to match two implicitly defined distributions, one of which is usually represented by a sample of real data, and the other is defined by a generator. Typically, AO involves training of a high-capacity model on each step of the optimization. In this work, we consider computationally heavy generators, for which training of high-capacity models is associated with substantial computational costs. To address this problem, we introduce a novel family of divergences, which varies the capacity of the underlying model, and allows for a significant acceleration with respect to the number of samples drawn from the generator. We demonstrate the performance of the proposed divergences on several tasks, including tuning parameters of a physics simulator, namely, Pythia event generator.
$(1 + \varepsilon)$-class Classification: an Anomaly Detection Method for Highly Imbalanced or Incomplete Data Sets
Jun 14, 2019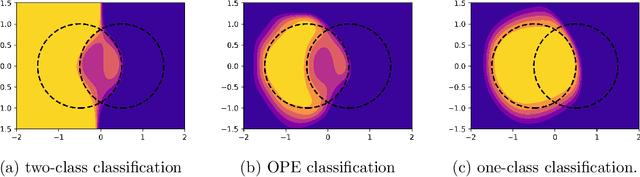
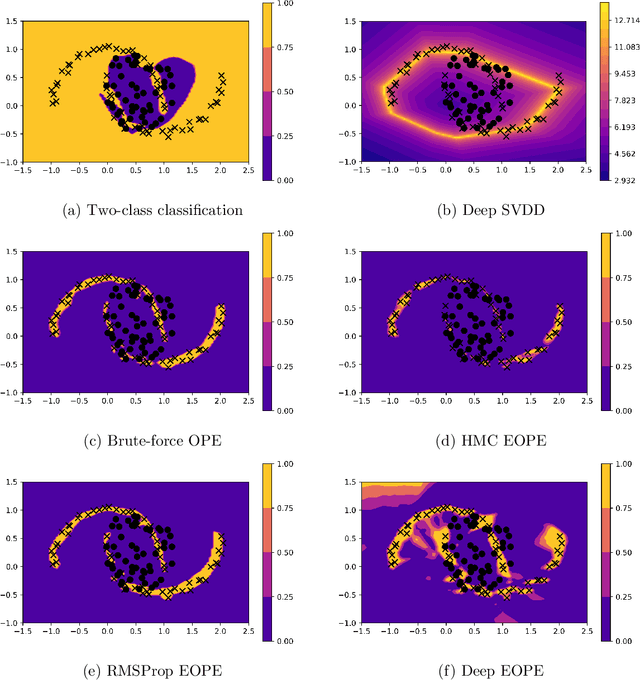
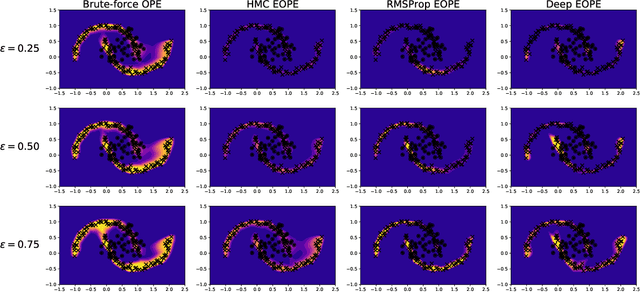
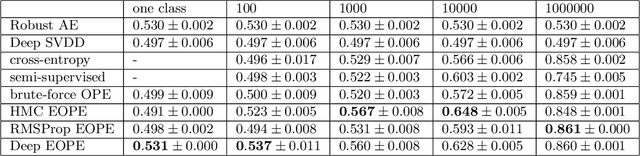
Anomaly detection is not an easy problem since distribution of anomalous samples is unknown a priori. We explore a novel method that gives a trade-off possibility between one-class and two-class approaches, and leads to a better performance on anomaly detection problems with small or non-representative anomalous samples. The method is evaluated using several data sets and compared to a set of conventional one-class and two-class approaches.
Machine Learning on data with sPlot background subtraction
Jun 14, 2019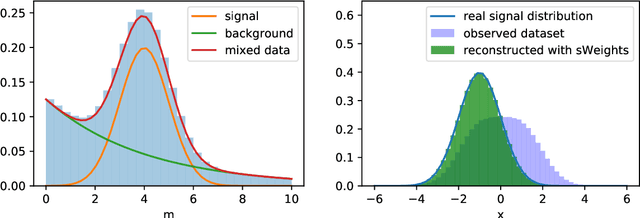
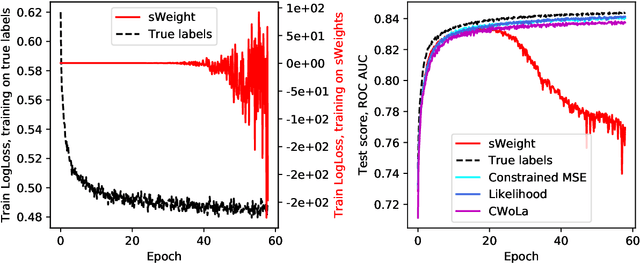
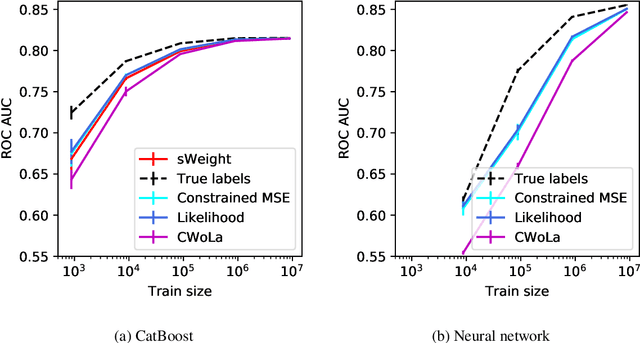
Data analysis in high energy physics often deals with data samples consisting of a mixture of signal and background events. The sPlot technique is a common method to subtract the contribution of the background by assigning weights to events. Part of the weights are by design negative. Negative weights lead to the divergence of some machine learning algorithms training due to absence of the lower bound in the loss function. In this paper we propose a mathematically rigorous way to train machine learning algorithms on data samples with background described by sPlot to obtain signal probabilities conditioned on observables, without encountering negative event weight at all. This allows usage of any out-of-the-box machine learning methods on such data.
Numerical optimization for Artificial Retina Algorithm
Oct 01, 2017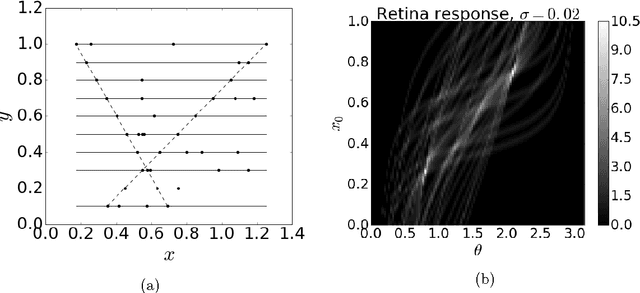
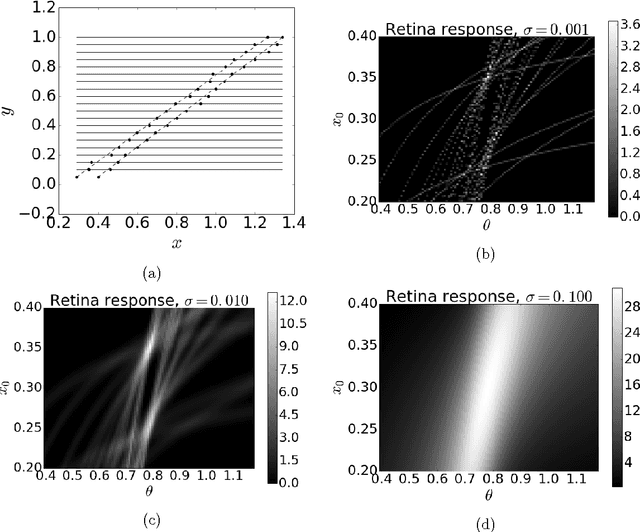
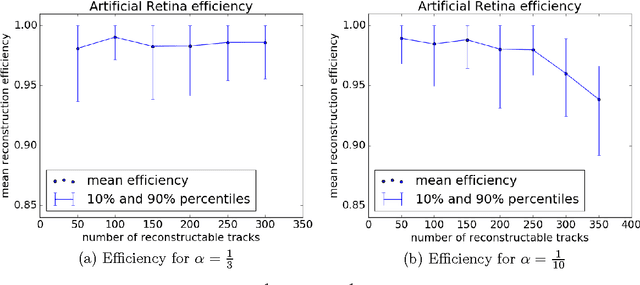
High-energy physics experiments rely on reconstruction of the trajectories of particles produced at the interaction point. This is a challenging task, especially in the high track multiplicity environment generated by p-p collisions at the LHC energies. A typical event includes hundreds of signal examples (interesting decays) and a significant amount of noise (uninteresting examples). This work describes a modification of the Artificial Retina algorithm for fast track finding: numerical optimization methods were adopted for fast local track search. This approach allows for considerable reduction of the total computational time per event. Test results on simplified simulated model of LHCb VELO (VErtex LOcator) detector are presented. Also this approach is well-suited for implementation of paralleled computations as GPGPU which look very attractive in the context of upcoming detector upgrades.
Towards automation of data quality system for CERN CMS experiment
Sep 25, 2017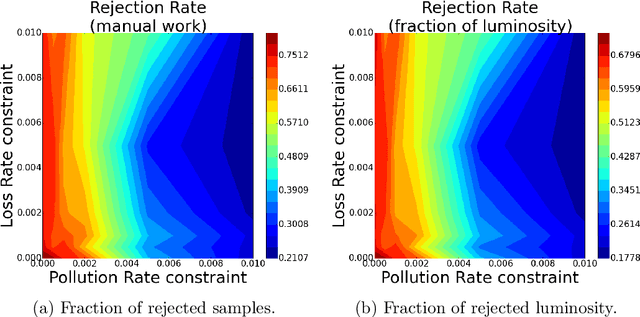
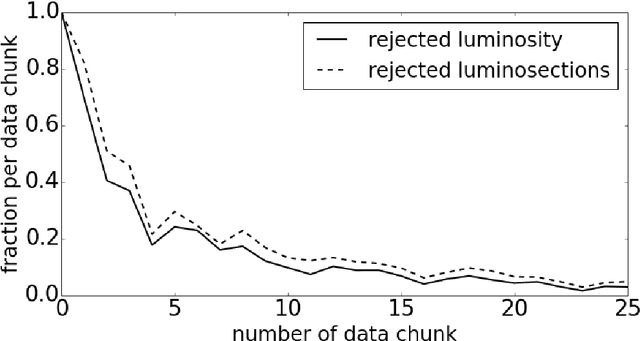
Daily operation of a large-scale experiment is a challenging task, particularly from perspectives of routine monitoring of quality for data being taken. We describe an approach that uses Machine Learning for the automated system to monitor data quality, which is based on partial use of data qualified manually by detector experts. The system automatically classifies marginal cases: both of good an bad data, and use human expert decision to classify remaining "grey area" cases. This study uses collision data collected by the CMS experiment at LHC in 2010. We demonstrate that proposed workflow is able to automatically process at least 20\% of samples without noticeable degradation of the result.