 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePut Attention to Temporal Saliency Patterns of Multi-Horizon Time Series
Dec 15, 2022Time series, sets of sequences in chronological order, are essential data in statistical research with many forecasting applications. Although recent performance in many Transformer-based models has been noticeable, long multi-horizon time series forecasting remains a very challenging task. Going beyond transformers in sequence translation and transduction research, we observe the effects of down-and-up samplings that can nudge temporal saliency patterns to emerge in time sequences. Motivated by the mentioned observation, in this paper, we propose a novel architecture, Temporal Saliency Detection (TSD), on top of the attention mechanism and apply it to multi-horizon time series prediction. We renovate the traditional encoder-decoder architecture by making as a series of deep convolutional blocks to work in tandem with the multi-head self-attention. The proposed TSD approach facilitates the multiresolution of saliency patterns upon condensed multi-heads, thus progressively enhancing complex time series forecasting. Experimental results illustrate that our proposed approach has significantly outperformed existing state-of-the-art methods across multiple standard benchmark datasets in many far-horizon forecasting settings. Overall, TSD achieves 31% and 46% relative improvement over the current state-of-the-art models in multivariate and univariate time series forecasting scenarios on standard benchmarks. The Git repository is available at https://github.com/duongtrung/time-series-temporal-saliency-patterns.
When Bioprocess Engineering Meets Machine Learning: A Survey from the Perspective of Automated Bioprocess Development
Sep 02, 2022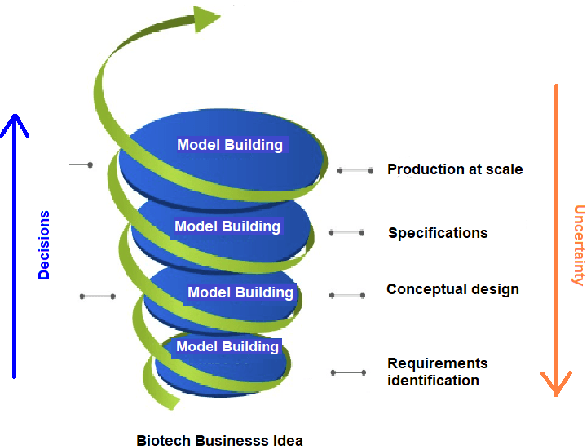
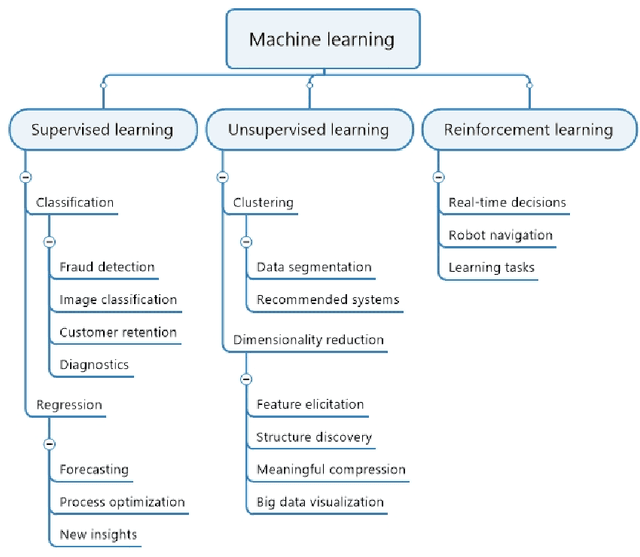
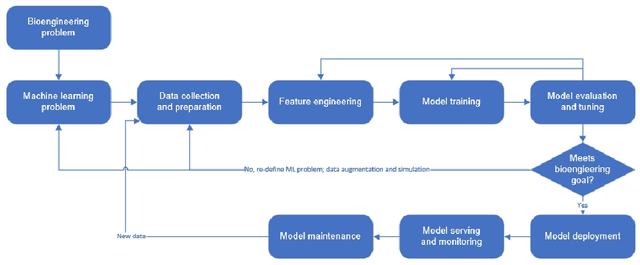
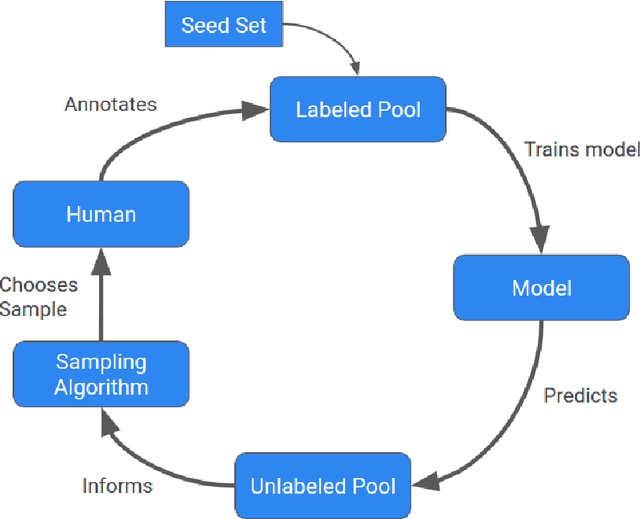
Machine learning (ML) has significantly contributed to the development of bioprocess engineering, but its application is still limited, hampering the enormous potential for bioprocess automation. ML for model building automation can be seen as a way of introducing another level of abstraction to focus expert humans in the most cognitive tasks of bioprocess development. First, probabilistic programming is used for the autonomous building of predictive models. Second, machine learning automatically assesses alternative decisions by planning experiments to test hypotheses and conducting investigations to gather informative data that focus on model selection based on the uncertainty of model predictions. This review provides a comprehensive overview of ML-based automation in bioprocess development. On the one hand, the biotech and bioengineering community should be aware of the potential and, most importantly, the limitation of existing ML solutions for their application in biotechnology and biopharma. On the other hand, it is essential to identify the missing links to enable the easy implementation of ML and Artificial Intelligence (AI) solutions in valuable solutions for the bio-community. We summarize recent ML implementation across several important subfields of bioprocess systems and raise two crucial challenges remaining the bottleneck of bioprocess automation and reducing uncertainty in biotechnology development. There is no one-fits-all procedure; however, this review should help identify the potential automation combining biotechnology and ML domains.
Yformer: U-Net Inspired Transformer Architecture for Far Horizon Time Series Forecasting
Oct 13, 2021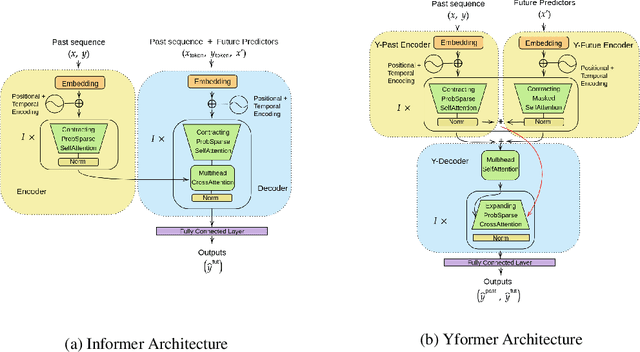
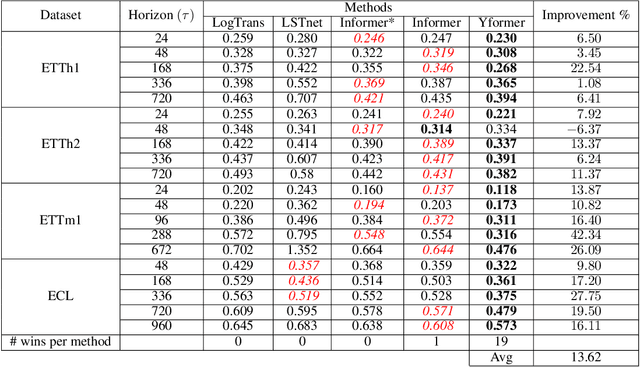
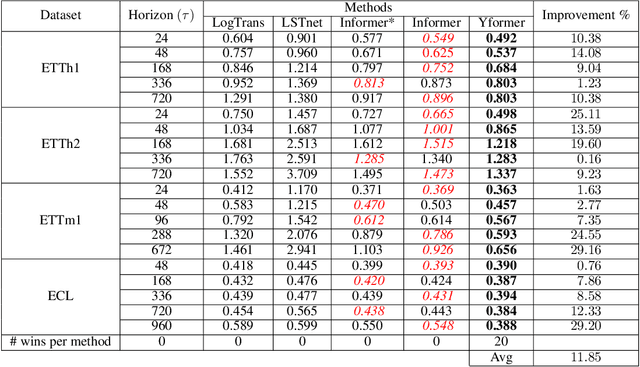
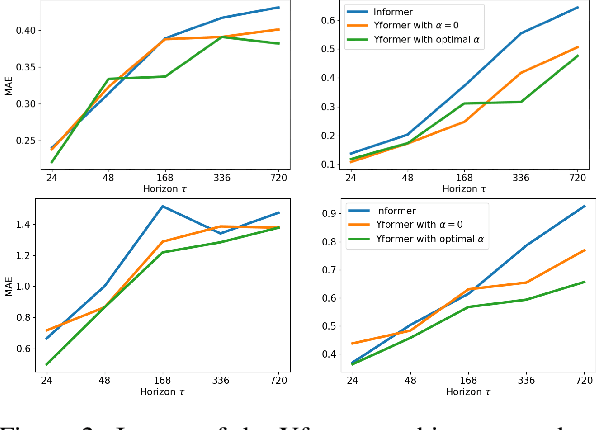
Time series data is ubiquitous in research as well as in a wide variety of industrial applications. Effectively analyzing the available historical data and providing insights into the far future allows us to make effective decisions. Recent research has witnessed the superior performance of transformer-based architectures, especially in the regime of far horizon time series forecasting. However, the current state of the art sparse Transformer architectures fail to couple down- and upsampling procedures to produce outputs in a similar resolution as the input. We propose the Yformer model, based on a novel Y-shaped encoder-decoder architecture that (1) uses direct connection from the downscaled encoder layer to the corresponding upsampled decoder layer in a U-Net inspired architecture, (2) Combines the downscaling/upsampling with sparse attention to capture long-range effects, and (3) stabilizes the encoder-decoder stacks with the addition of an auxiliary reconstruction loss. Extensive experiments have been conducted with relevant baselines on four benchmark datasets, demonstrating an average improvement of 19.82, 18.41 percentage MSE and 13.62, 11.85 percentage MAE in comparison to the current state of the art for the univariate and the multivariate settings respectively.
Bank Card Usage Prediction Exploiting Geolocation Information
Oct 13, 2016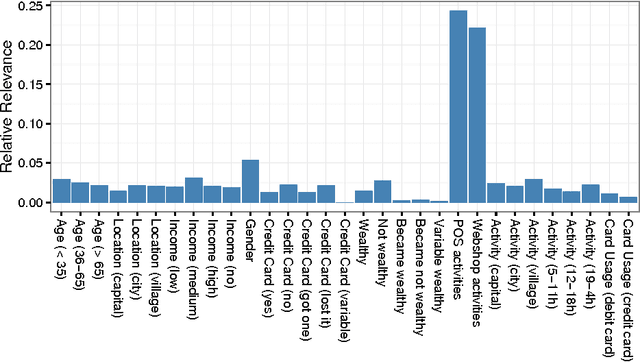
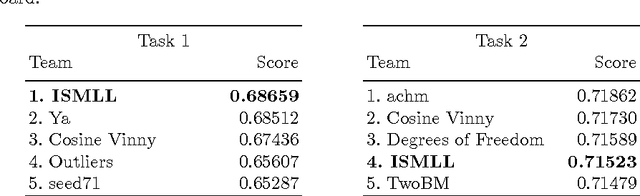
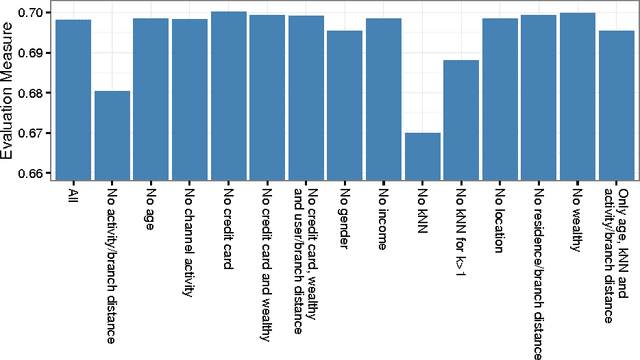
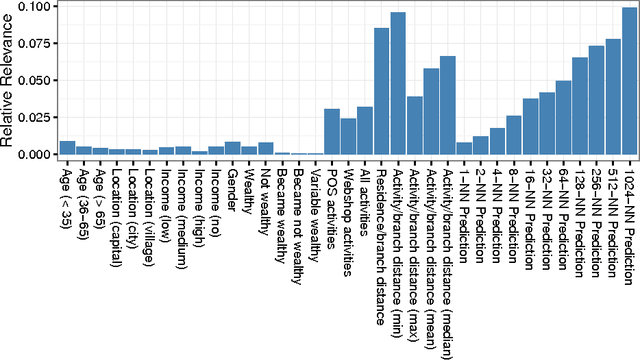
We describe the solution of team ISMLL for the ECML-PKDD 2016 Discovery Challenge on Bank Card Usage for both tasks. Our solution is based on three pillars. Gradient boosted decision trees as a strong regression and classification model, an intensive search for good hyperparameter configurations and strong features that exploit geolocation information. This approach achieved the best performance on the public leaderboard for the first task and a decent fourth position for the second task.