 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Patch Shuffle (TPS): Leveraging Patch-Level Shuffling to Boost Generalization and Robustness in Time Series Forecasting
Apr 10, 2026Data augmentation is a crucial technique for improving model generalization and robustness, particularly in deep learning models where training data is limited. Although many augmentation methods have been developed for time series classification, most are not directly applicable to time series forecasting due to the need to preserve temporal coherence. In this work, we propose Temporal Patch Shuffle (TPS), a simple and model-agnostic data augmentation method for forecasting that extracts overlapping temporal patches, selectively shuffles a subset of patches using variance-based ordering as a conservative heuristic, and reconstructs the sequence by averaging overlapping regions. This design increases sample diversity while preserving forecast-consistent local temporal structure. We extensively evaluate TPS across nine long-term forecasting datasets using five recent model families (TSMixer, DLinear, PatchTST, TiDE, and LightTS), and across four short-term forecasting datasets using PatchTST, observing consistent performance improvements. Comprehensive ablation studies further demonstrate the effectiveness, robustness, and design rationale of the proposed method.
LAtte: Hyperbolic Lorentz Attention for Cross-Subject EEG Classification
Mar 11, 2026Electroencephalogram (EEG) classification is critical for applications ranging from medical diagnostics to brain-computer interfaces, yet it remains challenging due to the inherently low signal-to-noise ratio (SNR) and high inter-subject variability. To address these issues, we propose LAtte, a novel framework that integrates a Lorentz Attention Module with an InceptionTime-based encoder to enable robust and generalizable EEG classification. Unlike prior work, which evaluates primarily on single-subject performance, LAtte focuses on cross-subject training. First, we learn a shared baseline signal across all subjects using pretraining tasks to capture common underlying patterns. Then, we utilize novel Lorentz low-rank adapters to learn subject-specific embeddings that model individual differences. This allows us to learn a shared model that performs robustly across subjects, and can be subsequently finetuned for individual subjects or used to generalize to unseen subjects. We evaluate LAtte on three well-established EEG datasets, achieving a substantial improvement in performance over current state-of-the-art methods.
A Cross-Domain Benchmark for Active Learning
Aug 01, 2024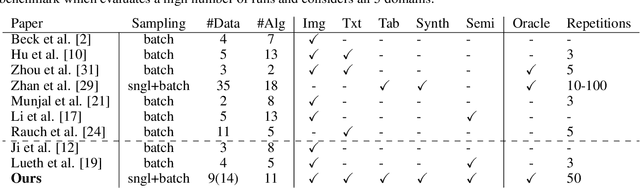
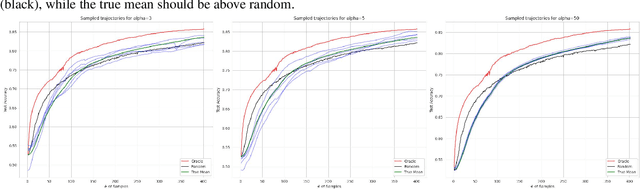
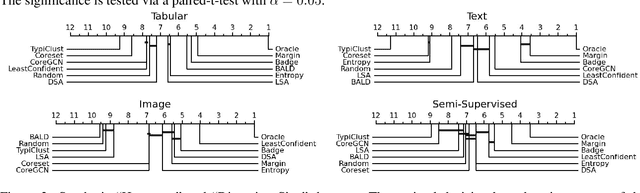
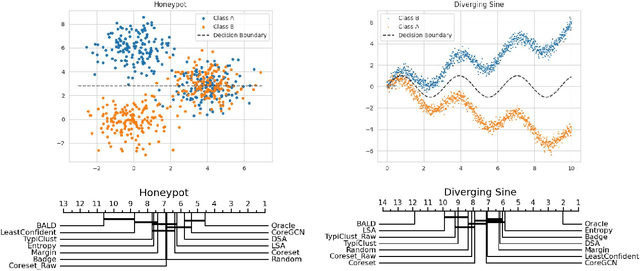
Active Learning (AL) deals with identifying the most informative samples for labeling to reduce data annotation costs for supervised learning tasks. AL research suffers from the fact that lifts from literature generalize poorly and that only a small number of repetitions of experiments are conducted. To overcome these obstacles, we propose \emph{CDALBench}, the first active learning benchmark which includes tasks in computer vision, natural language processing and tabular learning. Furthermore, by providing an efficient, greedy oracle, \emph{CDALBench} can be evaluated with 50 runs for each experiment. We show, that both the cross-domain character and a large amount of repetitions are crucial for sophisticated evaluation of AL research. Concretely, we show that the superiority of specific methods varies over the different domains, making it important to evaluate Active Learning with a cross-domain benchmark. Additionally, we show that having a large amount of runs is crucial. With only conducting three runs as often done in the literature, the superiority of specific methods can strongly vary with the specific runs. This effect is so strong, that, depending on the seed, even a well-established method's performance can be significantly better and significantly worse than random for the same dataset.
Are EEG Sequences Time Series? EEG Classification with Time Series Models and Joint Subject Training
Apr 10, 2024



As with most other data domains, EEG data analysis relies on rich domain-specific preprocessing. Beyond such preprocessing, machine learners would hope to deal with such data as with any other time series data. For EEG classification many models have been developed with layer types and architectures we typically do not see in time series classification. Furthermore, typically separate models for each individual subject are learned, not one model for all of them. In this paper, we systematically study the differences between EEG classification models and generic time series classification models. We describe three different model setups to deal with EEG data from different subjects, subject-specific models (most EEG literature), subject-agnostic models and subject-conditional models. In experiments on three datasets, we demonstrate that off-the-shelf time series classification models trained per subject perform close to EEG classification models, but that do not quite reach the performance of domain-specific modeling. Additionally, we combine time-series models with subject embeddings to train one joint subject-conditional classifier on all subjects. The resulting models are competitive with dedicated EEG models in 2 out of 3 datasets, even outperforming all EEG methods on one of them.
Towards Comparable Active Learning
Nov 30, 2023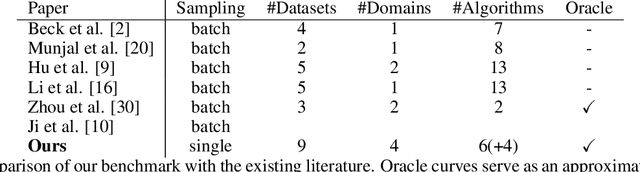
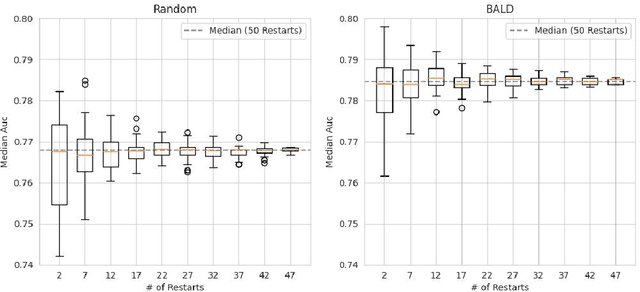
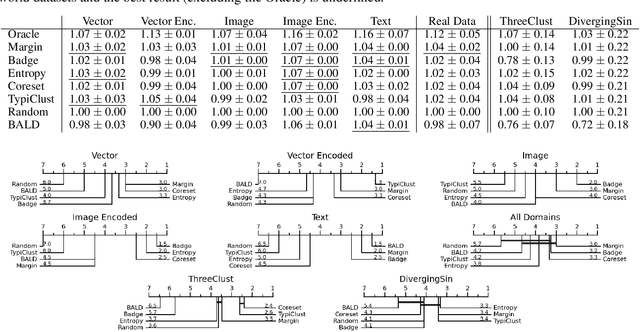
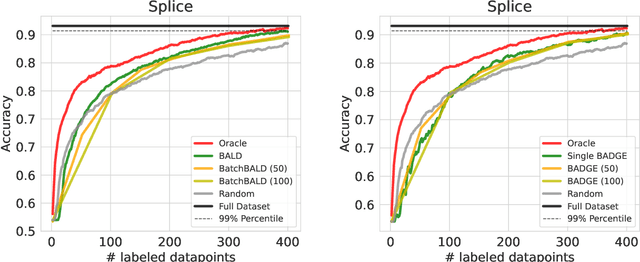
Active Learning has received significant attention in the field of machine learning for its potential in selecting the most informative samples for labeling, thereby reducing data annotation costs. However, we show that the reported lifts in recent literature generalize poorly to other domains leading to an inconclusive landscape in Active Learning research. Furthermore, we highlight overlooked problems for reproducing AL experiments that can lead to unfair comparisons and increased variance in the results. This paper addresses these issues by providing an Active Learning framework for a fair comparison of algorithms across different tasks and domains, as well as a fast and performant oracle algorithm for evaluation. To the best of our knowledge, we propose the first AL benchmark that tests algorithms in 3 major domains: Tabular, Image, and Text. We report empirical results for 6 widely used algorithms on 7 real-world and 2 synthetic datasets and aggregate them into a domain-specific ranking of AL algorithms.
Forecasting Irregularly Sampled Time Series using Graphs
May 22, 2023



Forecasting irregularly sampled time series with missing values is a crucial task for numerous real-world applications such as healthcare, astronomy, and climate sciences. State-of-the-art approaches to this problem rely on Ordinary Differential Equations (ODEs) but are known to be slow and to require additional features to handle missing values. To address this issue, we propose a novel model using Graphs for Forecasting Irregularly Sampled Time Series with missing values which we call GraFITi. GraFITi first converts the time series to a Sparsity Structure Graph which is a sparse bipartite graph, and then reformulates the forecasting problem as the edge weight prediction task in the graph. It uses the power of Graph Neural Networks to learn the graph and predict the target edge weights. We show that GraFITi can be used not only for our Sparsity Structure Graph but also for alternative graph representations of time series. GraFITi has been tested on 3 real-world and 1 synthetic irregularly sampled time series dataset with missing values and compared with various state-of-the-art models. The experimental results demonstrate that GraFITi improves the forecasting accuracy by up to 17% and reduces the run time up to 5 times compared to the state-of-the-art forecasting models.
Put Attention to Temporal Saliency Patterns of Multi-Horizon Time Series
Dec 15, 2022Time series, sets of sequences in chronological order, are essential data in statistical research with many forecasting applications. Although recent performance in many Transformer-based models has been noticeable, long multi-horizon time series forecasting remains a very challenging task. Going beyond transformers in sequence translation and transduction research, we observe the effects of down-and-up samplings that can nudge temporal saliency patterns to emerge in time sequences. Motivated by the mentioned observation, in this paper, we propose a novel architecture, Temporal Saliency Detection (TSD), on top of the attention mechanism and apply it to multi-horizon time series prediction. We renovate the traditional encoder-decoder architecture by making as a series of deep convolutional blocks to work in tandem with the multi-head self-attention. The proposed TSD approach facilitates the multiresolution of saliency patterns upon condensed multi-heads, thus progressively enhancing complex time series forecasting. Experimental results illustrate that our proposed approach has significantly outperformed existing state-of-the-art methods across multiple standard benchmark datasets in many far-horizon forecasting settings. Overall, TSD achieves 31% and 46% relative improvement over the current state-of-the-art models in multivariate and univariate time series forecasting scenarios on standard benchmarks. The Git repository is available at https://github.com/duongtrung/time-series-temporal-saliency-patterns.
Tripletformer for Probabilistic Interpolation of Asynchronous Time Series
Oct 05, 2022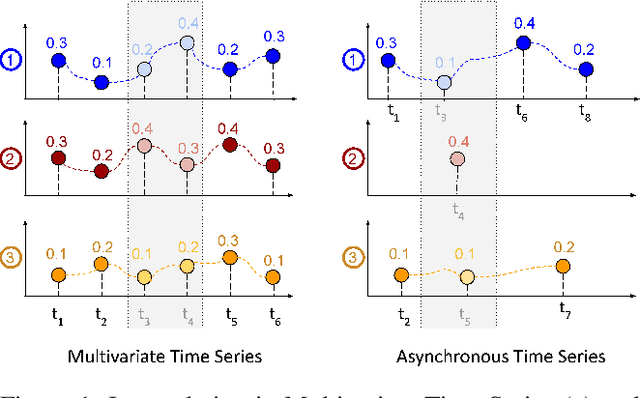
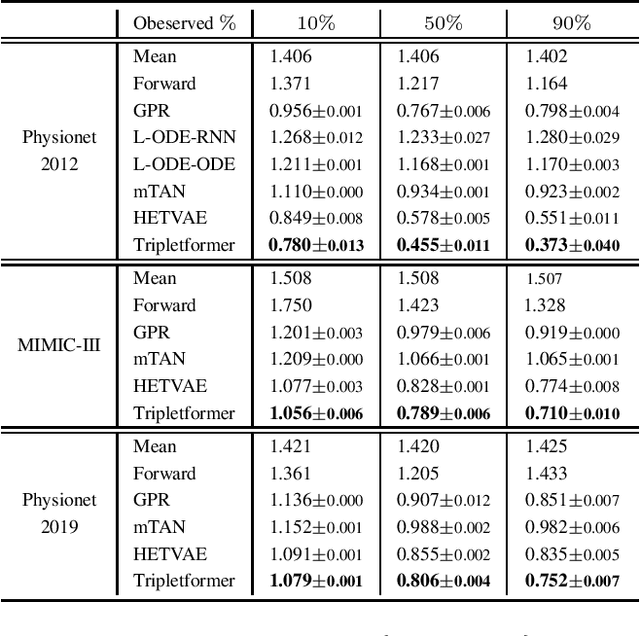
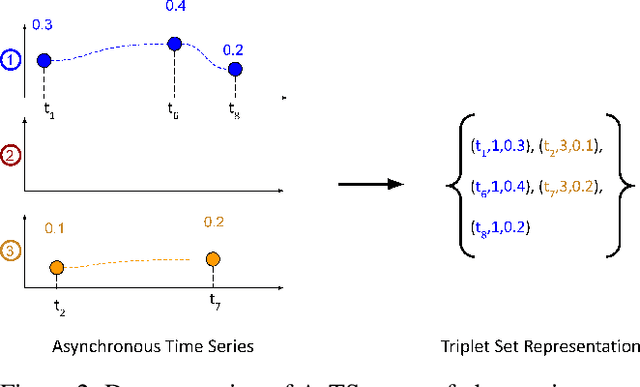
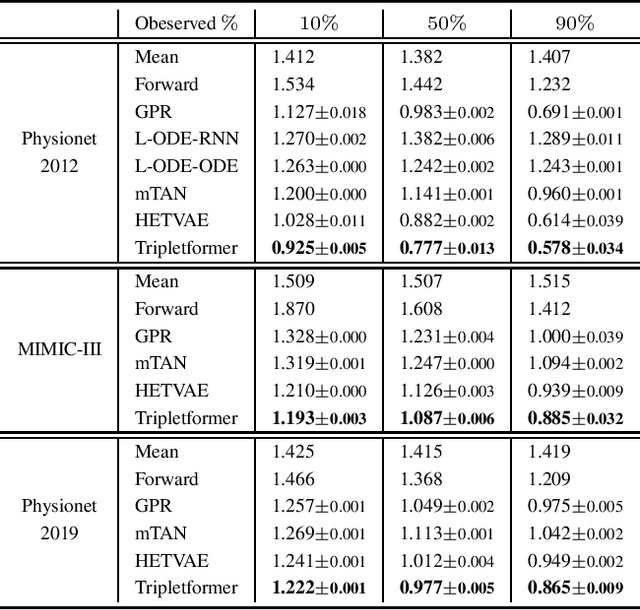
Asynchronous time series are often observed in several applications such as health care, astronomy, and climate science, and pose a significant challenge to the standard deep learning architectures. Interpolation of asynchronous time series is vital for many real-world tasks like root cause analysis, and medical diagnosis. In this paper, we propose a novel encoder-decoder architecture called Tripletformer, which works on the set of observations where each set element is a triple of time, channel, and value, for the probabilistic interpolation of the asynchronous time series. Both the encoder and the decoder of the Tripletformer are modeled using attention layers and fully connected layers and are invariant to the order in which set elements are presented. The proposed Tripletformer is compared with a range of baselines over multiple real-world and synthetic asynchronous time series datasets, and the experimental results attest that it produces more accurate and certain interpolations. We observe an improvement in negative loglikelihood error up to 33% over real and 800% over synthetic asynchronous time series datasets compared to the state-of-the-art model using the Tripletformer.
DCSF: Deep Convolutional Set Functions for Classification of Asynchronous Time Series
Aug 24, 2022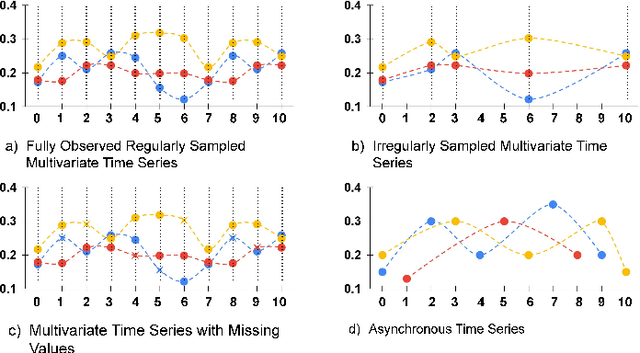
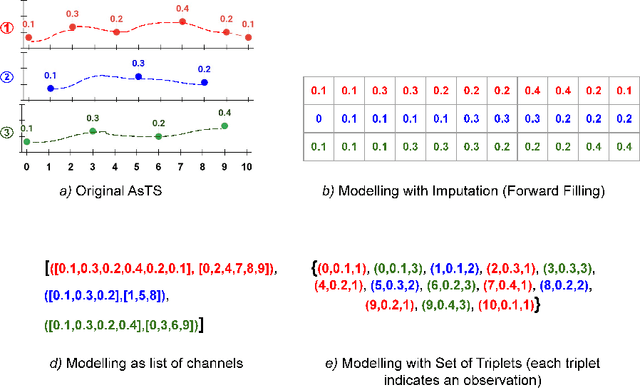

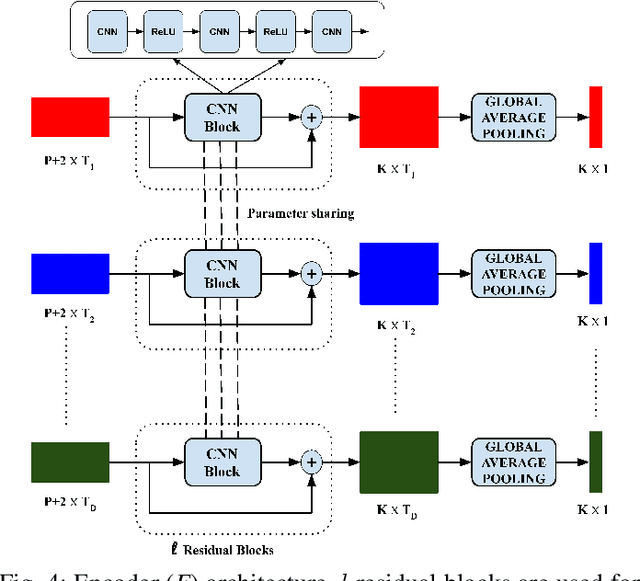
Asynchronous Time Series is a multivariate time series where all the channels are observed asynchronously-independently, making the time series extremely sparse when aligning them. We often observe this effect in applications with complex observation processes, such as health care, climate science, and astronomy, to name a few. Because of the asynchronous nature, they pose a significant challenge to deep learning architectures, which presume that the time series presented to them are regularly sampled, fully observed, and aligned with respect to time. This paper proposes a novel framework, that we call Deep Convolutional Set Functions (DCSF), which is highly scalable and memory efficient, for the asynchronous time series classification task. With the recent advancements in deep set learning architectures, we introduce a model that is invariant to the order in which time series' channels are presented to it. We explore convolutional neural networks, which are well researched for the closely related problem-classification of regularly sampled and fully observed time series, for encoding the set elements. We evaluate DCSF for AsTS classification, and online (per time point) AsTS classification. Our extensive experiments on multiple real-world and synthetic datasets verify that the suggested model performs substantially better than a range of state-of-the-art models in terms of accuracy and run time.
Few-Shot Forecasting of Time-Series with Heterogeneous Channels
Apr 07, 2022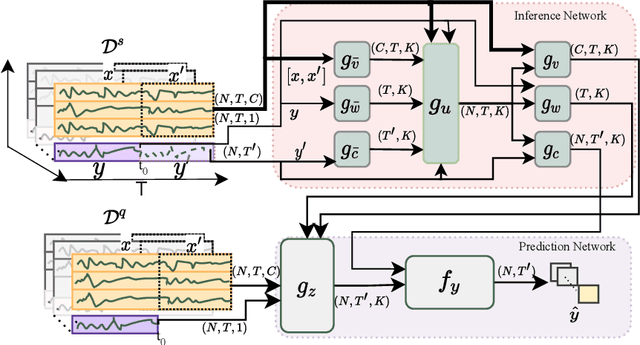
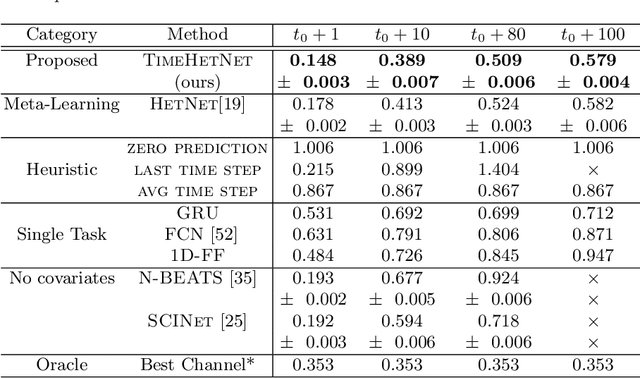
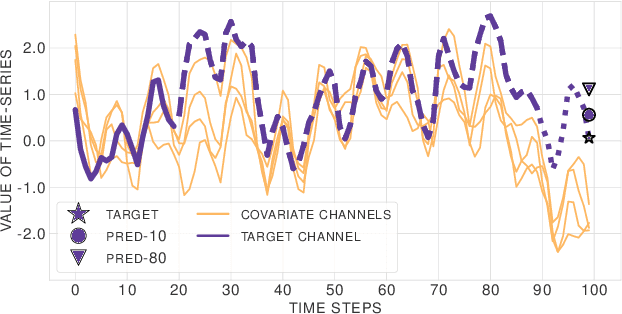

Learning complex time series forecasting models usually requires a large amount of data, as each model is trained from scratch for each task/data set. Leveraging learning experience with similar datasets is a well-established technique for classification problems called few-shot classification. However, existing approaches cannot be applied to time-series forecasting because i) multivariate time-series datasets have different channels and ii) forecasting is principally different from classification. In this paper we formalize the problem of few-shot forecasting of time-series with heterogeneous channels for the first time. Extending recent work on heterogeneous attributes in vector data, we develop a model composed of permutation-invariant deep set-blocks which incorporate a temporal embedding. We assemble the first meta-dataset of 40 multivariate time-series datasets and show through experiments that our model provides a good generalization, outperforming baselines carried over from simpler scenarios that either fail to learn across tasks or miss temporal information.