 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Comparable Active Learning
Paper and Code
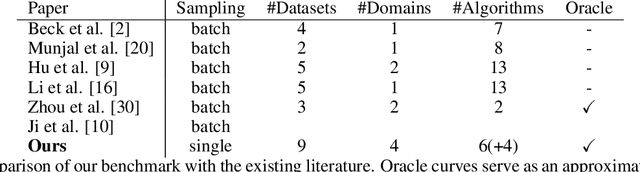
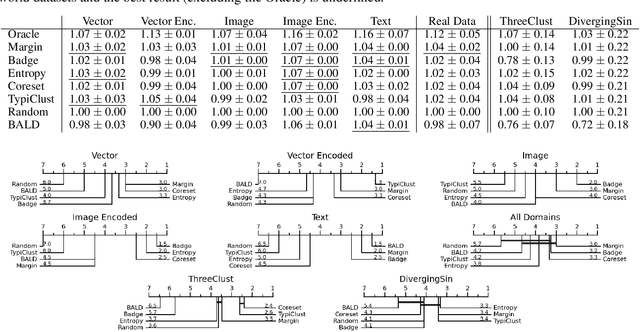
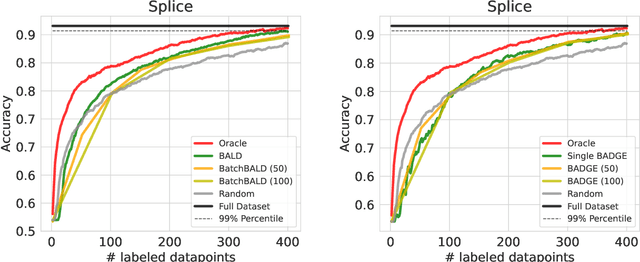
Active Learning has received significant attention in the field of machine learning for its potential in selecting the most informative samples for labeling, thereby reducing data annotation costs. However, we show that the reported lifts in recent literature generalize poorly to other domains leading to an inconclusive landscape in Active Learning research. Furthermore, we highlight overlooked problems for reproducing AL experiments that can lead to unfair comparisons and increased variance in the results. This paper addresses these issues by providing an Active Learning framework for a fair comparison of algorithms across different tasks and domains, as well as a fast and performant oracle algorithm for evaluation. To the best of our knowledge, we propose the first AL benchmark that tests algorithms in 3 major domains: Tabular, Image, and Text. We report empirical results for 6 widely used algorithms on 7 real-world and 2 synthetic datasets and aggregate them into a domain-specific ranking of AL algorithms.