 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot human motion prediction for heterogeneous sensors
Dec 22, 2022Human motion prediction is a complex task as it involves forecasting variables over time on a graph of connected sensors. This is especially true in the case of few-shot learning, where we strive to forecast motion sequences for previously unseen actions based on only a few examples. Despite this, almost all related approaches for few-shot motion prediction do not incorporate the underlying graph, while it is a common component in classical motion prediction. Furthermore, state-of-the-art methods for few-shot motion prediction are restricted to motion tasks with a fixed output space meaning these tasks are all limited to the same sensor graph. In this work, we propose to extend recent works on few-shot time-series forecasting with heterogeneous attributes with graph neural networks to introduce the first few-shot motion approach that explicitly incorporates the spatial graph while also generalizing across motion tasks with heterogeneous sensors. In our experiments on motion tasks with heterogeneous sensors, we demonstrate significant performance improvements with lifts from 10.4% up to 39.3% compared to best state-of-the-art models. Moreover, we show that our model can perform on par with the best approach so far when evaluating on tasks with a fixed output space while maintaining two magnitudes fewer parameters.
End-to-End Image-Based Fashion Recommendation
May 05, 2022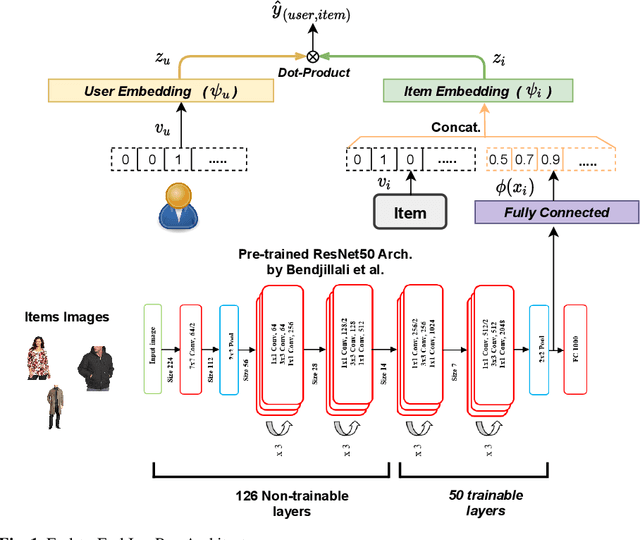

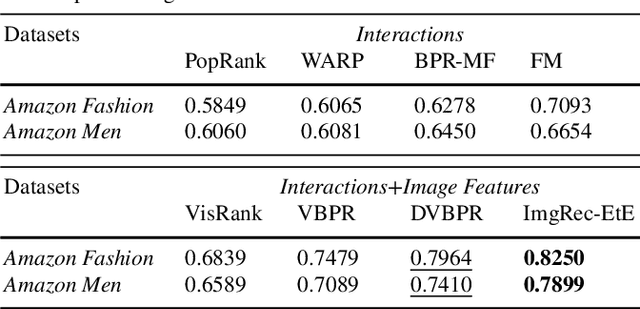

In fashion-based recommendation settings, incorporating the item image features is considered a crucial factor, and it has shown significant improvements to many traditional models, including but not limited to matrix factorization, auto-encoders, and nearest neighbor models. While there are numerous image-based recommender approaches that utilize dedicated deep neural networks, comparisons to attribute-aware models are often disregarded despite their ability to be easily extended to leverage items' image features. In this paper, we propose a simple yet effective attribute-aware model that incorporates image features for better item representation learning in item recommendation tasks. The proposed model utilizes items' image features extracted by a calibrated ResNet50 component. We present an ablation study to compare incorporating the image features using three different techniques into the recommender system component that can seamlessly leverage any available items' attributes. Experiments on two image-based real-world recommender systems datasets show that the proposed model significantly outperforms all state-of-the-art image-based models.
Few-Shot Forecasting of Time-Series with Heterogeneous Channels
Apr 07, 2022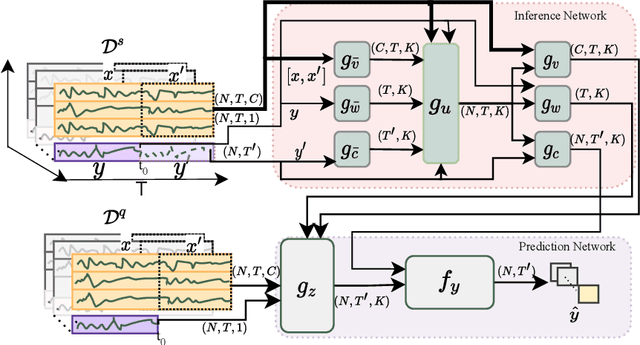
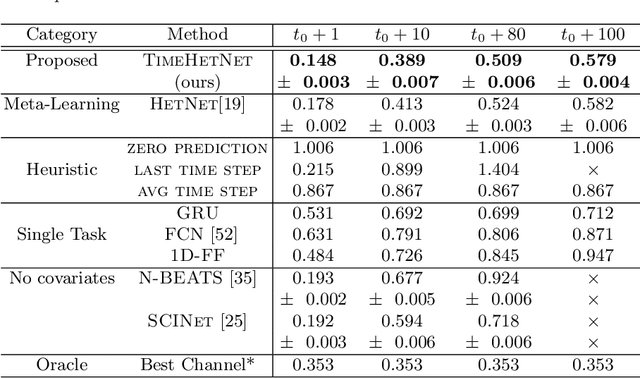
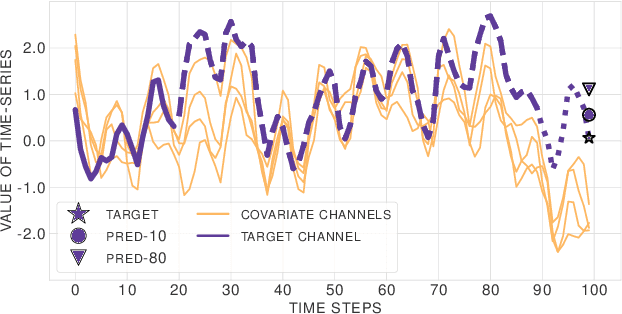

Learning complex time series forecasting models usually requires a large amount of data, as each model is trained from scratch for each task/data set. Leveraging learning experience with similar datasets is a well-established technique for classification problems called few-shot classification. However, existing approaches cannot be applied to time-series forecasting because i) multivariate time-series datasets have different channels and ii) forecasting is principally different from classification. In this paper we formalize the problem of few-shot forecasting of time-series with heterogeneous channels for the first time. Extending recent work on heterogeneous attributes in vector data, we develop a model composed of permutation-invariant deep set-blocks which incorporate a temporal embedding. We assemble the first meta-dataset of 40 multivariate time-series datasets and show through experiments that our model provides a good generalization, outperforming baselines carried over from simpler scenarios that either fail to learn across tasks or miss temporal information.
HIDRA: Head Initialization across Dynamic targets for Robust Architectures
Oct 28, 2019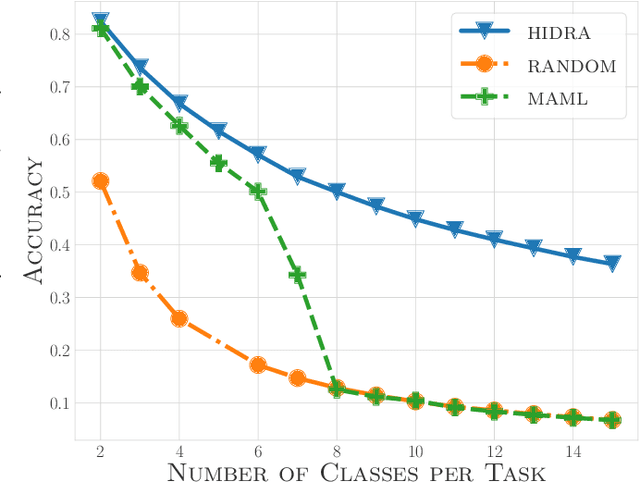
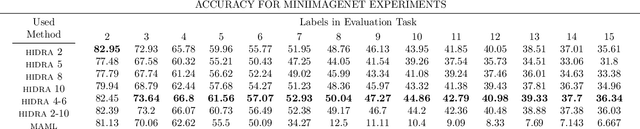
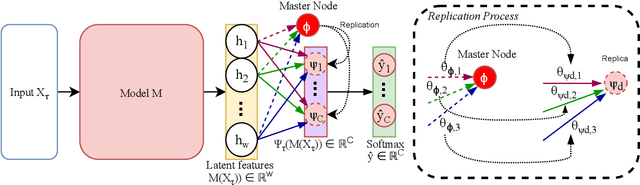
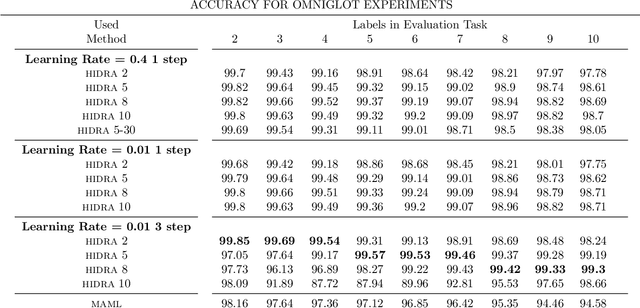
The performance of gradient-based optimization strategies depends heavily on the initial weights of the parametric model. Recent works show that there exist weight initializations from which optimization procedures can find the task-specific parameters faster than from uniformly random initializations, and that such a weight initialization can be learned by optimizing a specific model architecture across similar tasks via MAML (Model-Agnostic Meta-Learning). Current methods are limited to populations of classification tasks that share the same number of classes due to the static model architectures used during meta-learning. In this paper, we present HIDRA, a meta-learning approach that enables training and evaluating across tasks with any number of target variables. We show that Model-Agnostic Meta-Learning trains a distribution for all the neurons in the output layer and a specific weight initialization for the ones in the hidden layers. HIDRA explores this by learning one master neuron which is used to initialize any number of output neurons for a new task. Extensive experiments on the Miniimagenet and Omniglot data sets demonstrate that HIDRA improves over standard approaches while generalizing to tasks with any number of target variables. Moreover, our approach is shown to robustify low-capacity models in learning across complex tasks with a high number of classes for which regular MAML fails to learn any feasible initialization.
Chameleon: Learning Model Initializations Across Tasks With Different Schemas
Oct 01, 2019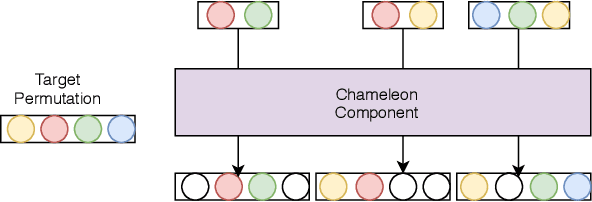
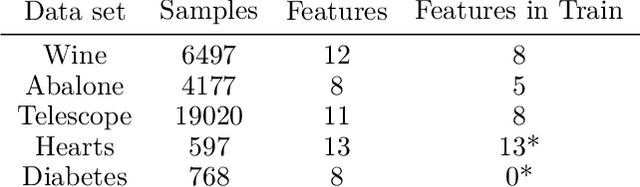
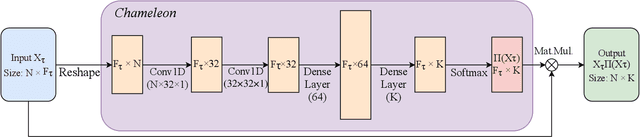
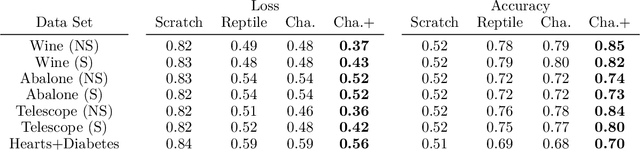
Parametric models, and particularly neural networks, require weight initialization as a starting point for gradient-based optimization. In most current practices, this is accomplished by using some form of random initialization. Instead, recent work shows that a specific initial parameter set can be learned from a population of tasks, i.e., dataset and target variable for supervised learning tasks. Using this initial parameter set leads to faster convergence for new tasks (model-agnostic meta-learning). Currently, methods for learning model initializations are limited to a population of tasks sharing the same schema, i.e., the same number, order, type and semantics of predictor and target variables. In this paper, we address the problem of meta-learning parameter initialization across tasks with different schemas, i.e., if the number of predictors varies across tasks, while they still share some variables. We propose Chameleon, a model that learns to align different predictor schemas to a common representation. We use permutations and masks of the predictors of the training tasks at hand. In experiments on real-life data sets, we show that Chameleon successfully can learn parameter initializations across tasks with different schemas providing a 26% lift on accuracy on average over random initialization and of 5% over a state-of-the-art method for fixed-schema learning model initializations. To the best of our knowledge, our paper is the first work on the problem of learning model initialization across tasks with different schemas.