 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Way Representation Alignment
Feb 05, 2026The Platonic Representation Hypothesis suggests that independently trained neural networks converge to increasingly similar latent spaces. However, current strategies for mapping these representations are inherently pairwise, scaling quadratically with the number of models and failing to yield a consistent global reference. In this paper, we study the alignment of $M \ge 3$ models. We first adapt Generalized Procrustes Analysis (GPA) to construct a shared orthogonal universe that preserves the internal geometry essential for tasks like model stitching. We then show that strict isometric alignment is suboptimal for retrieval, where agreement-maximizing methods like Canonical Correlation Analysis (CCA) typically prevail. To bridge this gap, we finally propose Geometry-Corrected Procrustes Alignment (GCPA), which establishes a robust GPA-based universe followed by a post-hoc correction for directional mismatch. Extensive experiments demonstrate that GCPA consistently improves any-to-any retrieval while retaining a practical shared reference space.
Improving Interpretability and Robustness for the Detection of AI-Generated Images
Jun 21, 2024



With growing abilities of generative models, artificial content detection becomes an increasingly important and difficult task. However, all popular approaches to this problem suffer from poor generalization across domains and generative models. In this work, we focus on the robustness of AI-generated image (AIGI) detectors. We analyze existing state-of-the-art AIGI detection methods based on frozen CLIP embeddings and show how to interpret them, shedding light on how images produced by various AI generators differ from real ones. Next we propose two ways to improve robustness: based on removing harmful components of the embedding vector and based on selecting the best performing attention heads in the image encoder model. Our methods increase the mean out-of-distribution (OOD) classification score by up to 6% for cross-model transfer. We also propose a new dataset for AIGI detection and use it in our evaluation; we believe this dataset will help boost further research. The dataset and code are provided as a supplement.
RAVE: Residual Vector Embedding for CLIP-Guided Backlit Image Enhancement
Apr 03, 2024In this paper we propose a novel modification of Contrastive Language-Image Pre-Training (CLIP) guidance for the task of unsupervised backlit image enhancement. Our work builds on the state-of-the-art CLIP-LIT approach, which learns a prompt pair by constraining the text-image similarity between a prompt (negative/positive sample) and a corresponding image (backlit image/well-lit image) in the CLIP embedding space. Learned prompts then guide an image enhancement network. Based on the CLIP-LIT framework, we propose two novel methods for CLIP guidance. First, we show that instead of tuning prompts in the space of text embeddings, it is possible to directly tune their embeddings in the latent space without any loss in quality. This accelerates training and potentially enables the use of additional encoders that do not have a text encoder. Second, we propose a novel approach that does not require any prompt tuning. Instead, based on CLIP embeddings of backlit and well-lit images from training data, we compute the residual vector in the embedding space as a simple difference between the mean embeddings of the well-lit and backlit images. This vector then guides the enhancement network during training, pushing a backlit image towards the space of well-lit images. This approach further dramatically reduces training time, stabilizes training and produces high quality enhanced images without artifacts, both in supervised and unsupervised training regimes. Additionally, we show that residual vectors can be interpreted, revealing biases in training data, and thereby enabling potential bias correction.
Artificial Text Boundary Detection with Topological Data Analysis and Sliding Window Techniques
Nov 14, 2023
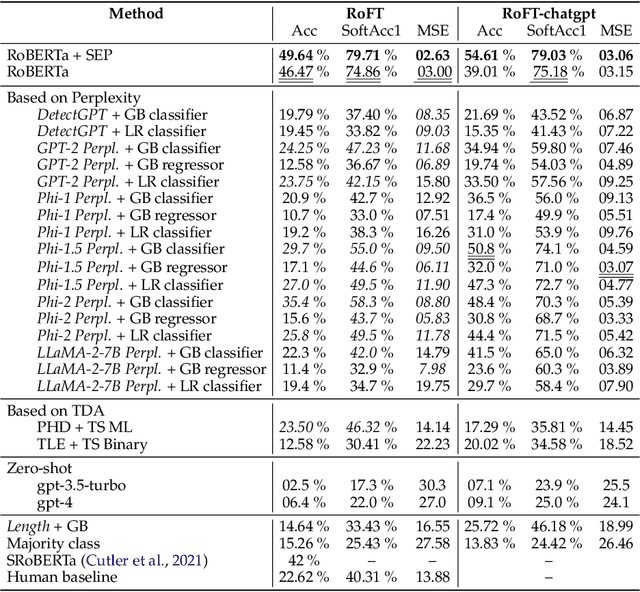
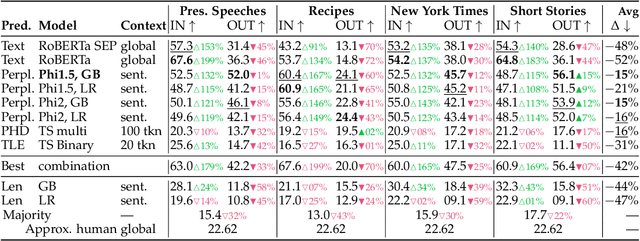
Due to the rapid development of text generation models, people increasingly often encounter texts that may start out as written by a human but then continue as machine-generated results of large language models. Detecting the boundary between human-written and machine-generated parts of such texts is a very challenging problem that has not received much attention in literature. In this work, we consider and compare a number of different approaches for this artificial text boundary detection problem, comparing several predictors over features of different nature. We show that supervised fine-tuning of the RoBERTa model works well for this task in general but fails to generalize in important cross-domain and cross-generator settings, demonstrating a tendency to overfit to spurious properties of the data. Then, we propose novel approaches based on features extracted from a frozen language model's embeddings that are able to outperform both the human accuracy level and previously considered baselines on the Real or Fake Text benchmark. Moreover, we adapt perplexity-based approaches for the boundary detection task and analyze their behaviour. We analyze the robustness of all proposed classifiers in cross-domain and cross-model settings, discovering important properties of the data that can negatively influence the performance of artificial text boundary detection algorithms.
Adaptive Divergence for Rapid Adversarial Optimization
Dec 01, 2019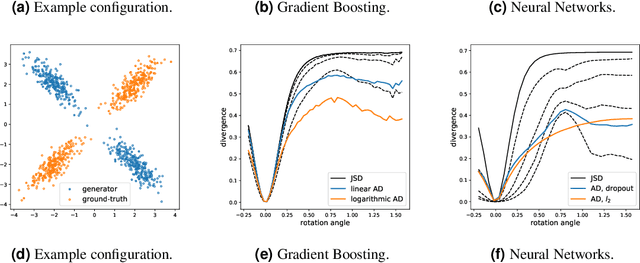
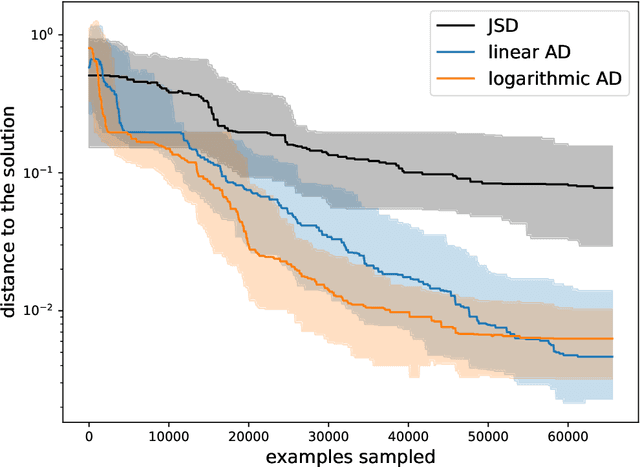
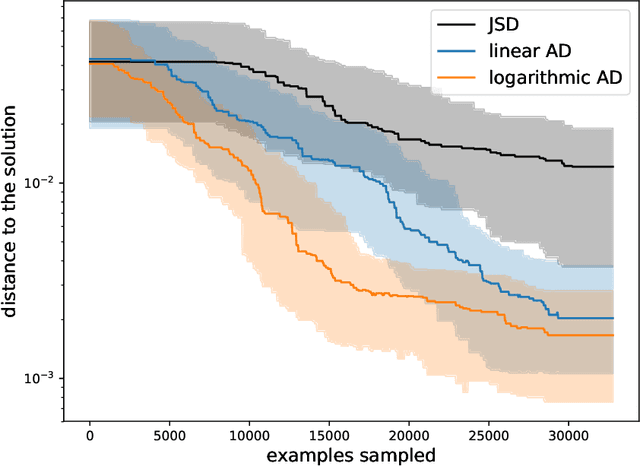
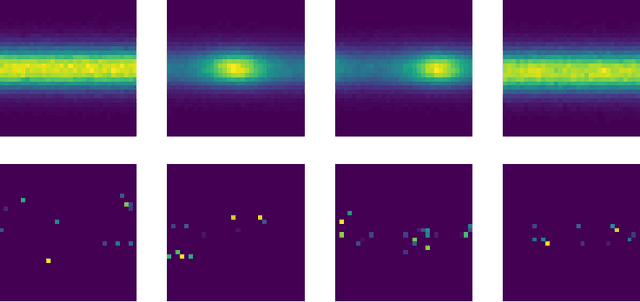
Adversarial Optimization (AO) provides a reliable, practical way to match two implicitly defined distributions, one of which is usually represented by a sample of real data, and the other is defined by a generator. Typically, AO involves training of a high-capacity model on each step of the optimization. In this work, we consider computationally heavy generators, for which training of high-capacity models is associated with substantial computational costs. To address this problem, we introduce a novel family of divergences, which varies the capacity of the underlying model, and allows for a significant acceleration with respect to the number of samples drawn from the generator. We demonstrate the performance of the proposed divergences on several tasks, including tuning parameters of a physics simulator, namely, Pythia event generator.