 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioSAE: Towards Understanding of Audio-Processing Models with Sparse AutoEncoders
Feb 04, 2026Sparse Autoencoders (SAEs) are powerful tools for interpreting neural representations, yet their use in audio remains underexplored. We train SAEs across all encoder layers of Whisper and HuBERT, provide an extensive evaluation of their stability, interpretability, and show their practical utility. Over 50% of the features remain consistent across random seeds, and reconstruction quality is preserved. SAE features capture general acoustic and semantic information as well as specific events, including environmental noises and paralinguistic sounds (e.g. laughter, whispering) and disentangle them effectively, requiring removal of only 19-27% of features to erase a concept. Feature steering reduces Whisper's false speech detections by 70% with negligible WER increase, demonstrating real-world applicability. Finally, we find SAE features correlated with human EEG activity during speech perception, indicating alignment with human neural processing. The code and checkpoints are available at https://github.com/audiosae/audiosae_demo.
Unveiling Intrinsic Dimension of Texts: from Academic Abstract to Creative Story
Nov 19, 2025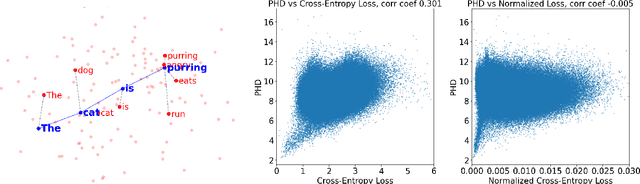
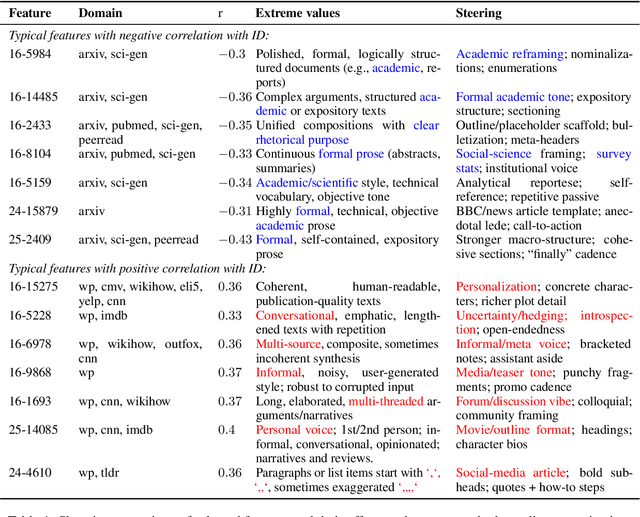
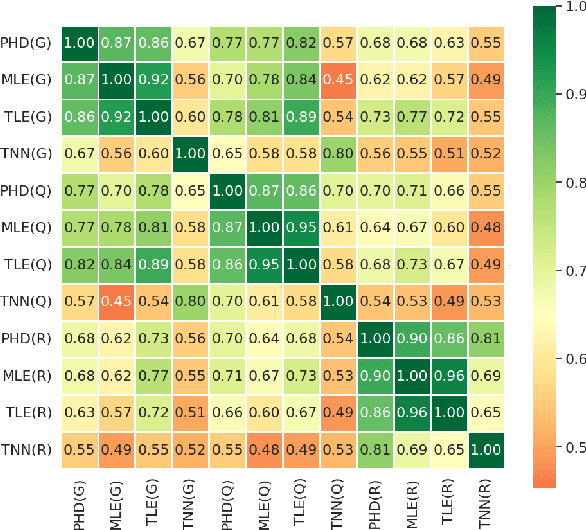

Intrinsic dimension (ID) is an important tool in modern LLM analysis, informing studies of training dynamics, scaling behavior, and dataset structure, yet its textual determinants remain underexplored. We provide the first comprehensive study grounding ID in interpretable text properties through cross-encoder analysis, linguistic features, and sparse autoencoders (SAEs). In this work, we establish three key findings. First, ID is complementary to entropy-based metrics: after controlling for length, the two are uncorrelated, with ID capturing geometric complexity orthogonal to prediction quality. Second, ID exhibits robust genre stratification: scientific prose shows low ID (~8), encyclopedic content medium ID (~9), and creative/opinion writing high ID (~10.5) across all models tested. This reveals that contemporary LLMs find scientific text "representationally simple" while fiction requires additional degrees of freedom. Third, using SAEs, we identify causal features: scientific signals (formal tone, report templates, statistics) reduce ID; humanized signals (personalization, emotion, narrative) increase it. Steering experiments confirm these effects are causal. Thus, for contemporary models, scientific writing appears comparatively "easy", whereas fiction, opinion, and affect add representational degrees of freedom. Our multi-faceted analysis provides practical guidance for the proper use of ID and the sound interpretation of ID-based results.
Feature-Level Insights into Artificial Text Detection with Sparse Autoencoders
Mar 05, 2025Artificial Text Detection (ATD) is becoming increasingly important with the rise of advanced Large Language Models (LLMs). Despite numerous efforts, no single algorithm performs consistently well across different types of unseen text or guarantees effective generalization to new LLMs. Interpretability plays a crucial role in achieving this goal. In this study, we enhance ATD interpretability by using Sparse Autoencoders (SAE) to extract features from Gemma-2-2b residual stream. We identify both interpretable and efficient features, analyzing their semantics and relevance through domain- and model-specific statistics, a steering approach, and manual or LLM-based interpretation. Our methods offer valuable insights into how texts from various models differ from human-written content. We show that modern LLMs have a distinct writing style, especially in information-dense domains, even though they can produce human-like outputs with personalized prompts.
Quantifying Logical Consistency in Transformers via Query-Key Alignment
Feb 24, 2025Large language models (LLMs) have demonstrated impressive performance in various natural language processing tasks, yet their ability to perform multi-step logical reasoning remains an open challenge. Although Chain-of-Thought prompting has improved logical reasoning by enabling models to generate intermediate steps, it lacks mechanisms to assess the coherence of these logical transitions. In this paper, we propose a novel, lightweight evaluation strategy for logical reasoning that uses query-key alignments inside transformer attention heads. By computing a single forward pass and extracting a "QK-score" from carefully chosen heads, our method reveals latent representations that reliably separate valid from invalid inferences, offering a scalable alternative to traditional ablation-based techniques. We also provide an empirical validation on multiple logical reasoning benchmarks, demonstrating improved robustness of our evaluation method against distractors and increased reasoning depth. The experiments were conducted on a diverse set of models, ranging from 1.5B to 70B parameters.
Robust AI-Generated Text Detection by Restricted Embeddings
Oct 10, 2024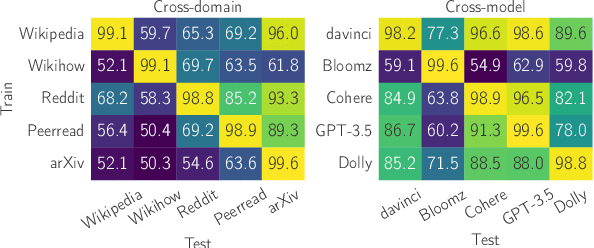
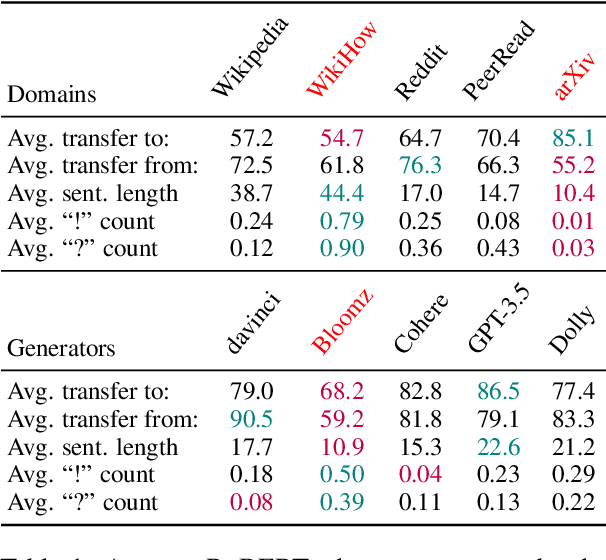
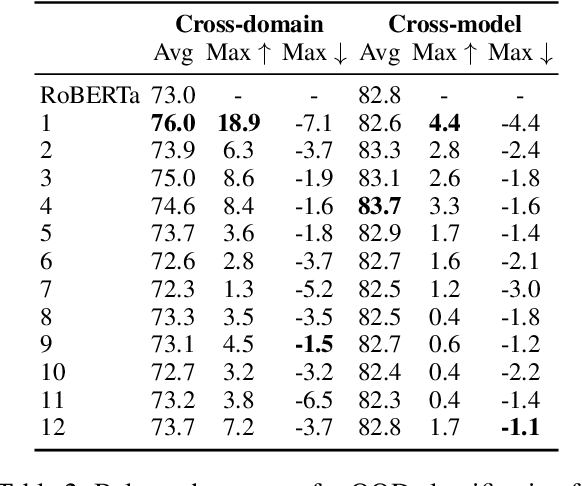
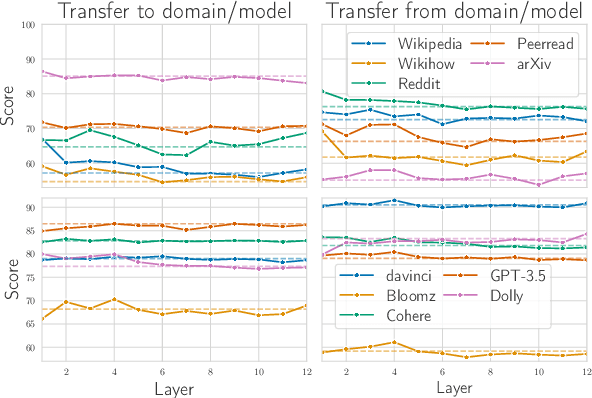
Growing amount and quality of AI-generated texts makes detecting such content more difficult. In most real-world scenarios, the domain (style and topic) of generated data and the generator model are not known in advance. In this work, we focus on the robustness of classifier-based detectors of AI-generated text, namely their ability to transfer to unseen generators or semantic domains. We investigate the geometry of the embedding space of Transformer-based text encoders and show that clearing out harmful linear subspaces helps to train a robust classifier, ignoring domain-specific spurious features. We investigate several subspace decomposition and feature selection strategies and achieve significant improvements over state of the art methods in cross-domain and cross-generator transfer. Our best approaches for head-wise and coordinate-based subspace removal increase the mean out-of-distribution (OOD) classification score by up to 9% and 14% in particular setups for RoBERTa and BERT embeddings respectively. We release our code and data: https://github.com/SilverSolver/RobustATD
Listening to the Wise Few: Select-and-Copy Attention Heads for Multiple-Choice QA
Oct 03, 2024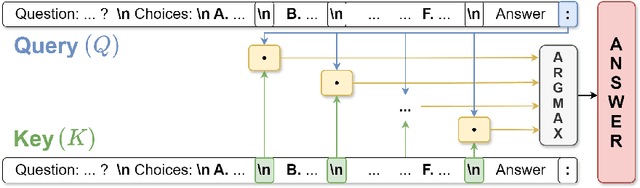
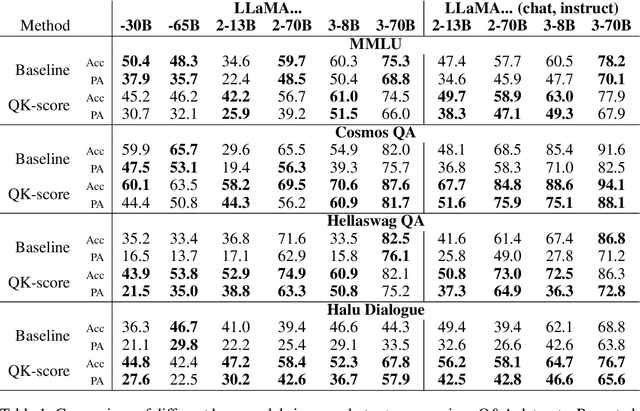
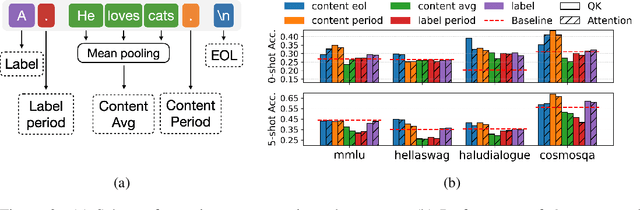
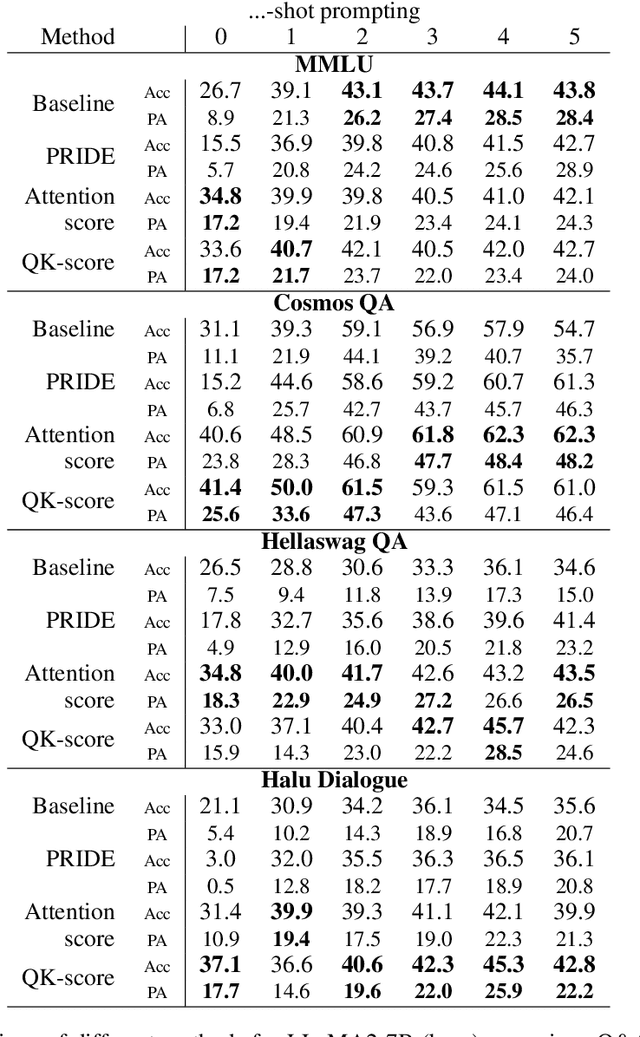
A standard way to evaluate the abilities of LLM involves presenting a multiple-choice question and selecting the option with the highest logit as the model's predicted answer. However, such a format for evaluating LLMs has limitations, since even if the model knows the correct answer, it may struggle to select the corresponding letter simply due to difficulties in following this rigid format. To address this, we introduce new scores that better capture and reveal model's underlying knowledge: the Query-Key Score (QK-score), derived from the interaction between query and key representations in attention heads, and the Attention Score, based on attention weights. These scores are extracted from specific \textit{select-and-copy} heads, which show consistent performance across popular Multi-Choice Question Answering (MCQA) datasets. Based on these scores, our method improves knowledge extraction, yielding up to 16\% gain for LLaMA2-7B and up to 10\% for larger models on popular MCQA benchmarks. At the same time, the accuracy on a simple synthetic dataset, where the model explicitly knows the right answer, increases by almost 60\%, achieving nearly perfect accuracy, therefore demonstrating the method's efficiency in mitigating MCQA format limitations. To support our claims, we conduct experiments on models ranging from 7 billion to 70 billion parameters in both zero- and few-shot setups.
Improving Interpretability and Robustness for the Detection of AI-Generated Images
Jun 21, 2024



With growing abilities of generative models, artificial content detection becomes an increasingly important and difficult task. However, all popular approaches to this problem suffer from poor generalization across domains and generative models. In this work, we focus on the robustness of AI-generated image (AIGI) detectors. We analyze existing state-of-the-art AIGI detection methods based on frozen CLIP embeddings and show how to interpret them, shedding light on how images produced by various AI generators differ from real ones. Next we propose two ways to improve robustness: based on removing harmful components of the embedding vector and based on selecting the best performing attention heads in the image encoder model. Our methods increase the mean out-of-distribution (OOD) classification score by up to 6% for cross-model transfer. We also propose a new dataset for AIGI detection and use it in our evaluation; we believe this dataset will help boost further research. The dataset and code are provided as a supplement.
Artificial Text Boundary Detection with Topological Data Analysis and Sliding Window Techniques
Nov 14, 2023
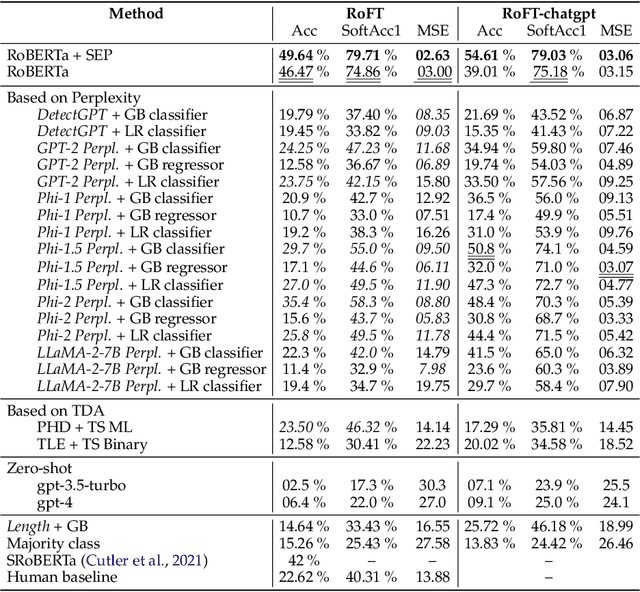
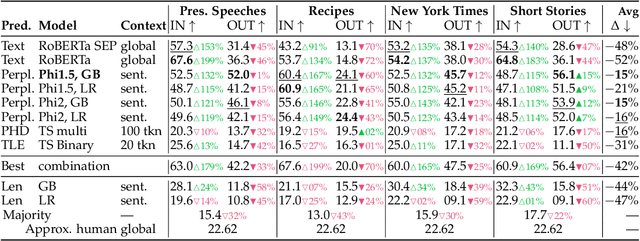
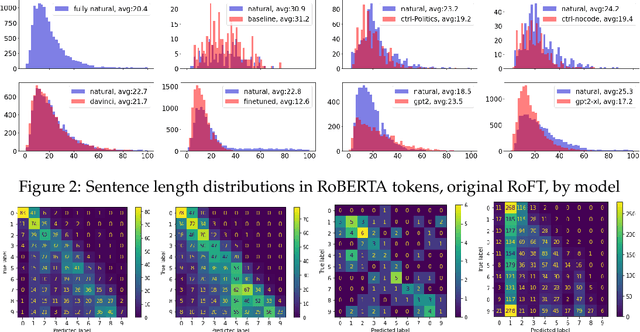
Due to the rapid development of text generation models, people increasingly often encounter texts that may start out as written by a human but then continue as machine-generated results of large language models. Detecting the boundary between human-written and machine-generated parts of such texts is a very challenging problem that has not received much attention in literature. In this work, we consider and compare a number of different approaches for this artificial text boundary detection problem, comparing several predictors over features of different nature. We show that supervised fine-tuning of the RoBERTa model works well for this task in general but fails to generalize in important cross-domain and cross-generator settings, demonstrating a tendency to overfit to spurious properties of the data. Then, we propose novel approaches based on features extracted from a frozen language model's embeddings that are able to outperform both the human accuracy level and previously considered baselines on the Real or Fake Text benchmark. Moreover, we adapt perplexity-based approaches for the boundary detection task and analyze their behaviour. We analyze the robustness of all proposed classifiers in cross-domain and cross-model settings, discovering important properties of the data that can negatively influence the performance of artificial text boundary detection algorithms.
Intrinsic Dimension Estimation for Robust Detection of AI-Generated Texts
Jun 07, 2023



Rapidly increasing quality of AI-generated content makes it difficult to distinguish between human and AI-generated texts, which may lead to undesirable consequences for society. Therefore, it becomes increasingly important to study the properties of human texts that are invariant over text domains and various proficiency of human writers, can be easily calculated for any language, and can robustly separate natural and AI-generated texts regardless of the generation model and sampling method. In this work, we propose such an invariant of human texts, namely the intrinsic dimensionality of the manifold underlying the set of embeddings of a given text sample. We show that the average intrinsic dimensionality of fluent texts in natural language is hovering around the value $9$ for several alphabet-based languages and around $7$ for Chinese, while the average intrinsic dimensionality of AI-generated texts for each language is $\approx 1.5$ lower, with a clear statistical separation between human-generated and AI-generated distributions. This property allows us to build a score-based artificial text detector. The proposed detector's accuracy is stable over text domains, generator models, and human writer proficiency levels, outperforming SOTA detectors in model-agnostic and cross-domain scenarios by a significant margin.
Topological Data Analysis for Speech Processing
Dec 02, 2022



We apply topological data analysis (TDA) to speech classification problems and to the introspection of a pretrained speech model, HuBERT. To this end, we introduce a number of topological and algebraic features derived from Transformer attention maps and embeddings. We show that a simple linear classifier built on top of such features outperforms a fine-tuned classification head. In particular, we achieve an improvement of about $9\%$ accuracy and $5\%$ ERR on four common datasets; on CREMA-D, the proposed feature set reaches a new state of the art performance with accuracy $80.155$. We also show that topological features are able to reveal functional roles of speech Transformer heads; e.g., we find the heads capable to distinguish between pairs of sample sources (natural/synthetic) or voices without any downstream fine-tuning. Our results demonstrate that TDA is a promising new approach for speech analysis, especially for tasks that require structural prediction. Appendices, an introduction to TDA, and other additional materials are available here - https://topohubert.github.io/speech-topology-webpages/