 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Text Boundary Detection with Topological Data Analysis and Sliding Window Techniques
Paper and Code

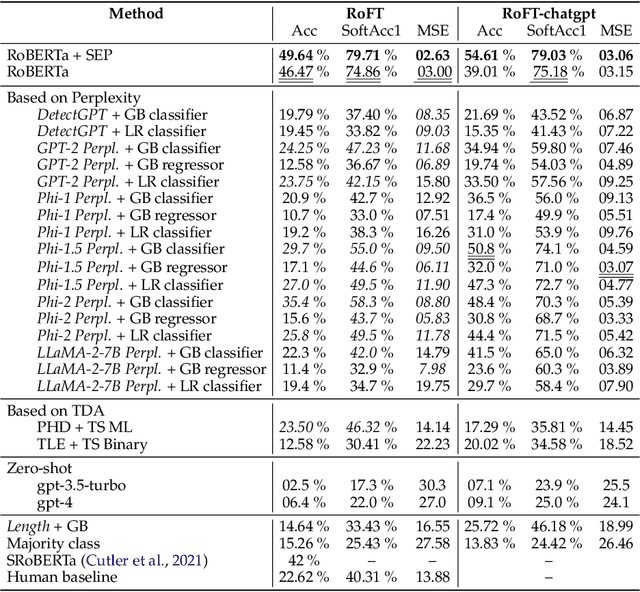
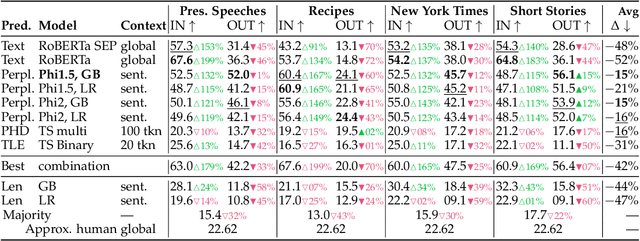
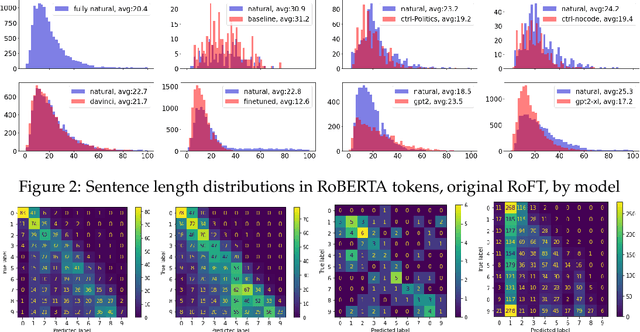
Due to the rapid development of text generation models, people increasingly often encounter texts that may start out as written by a human but then continue as machine-generated results of large language models. Detecting the boundary between human-written and machine-generated parts of such texts is a very challenging problem that has not received much attention in literature. In this work, we consider and compare a number of different approaches for this artificial text boundary detection problem, comparing several predictors over features of different nature. We show that supervised fine-tuning of the RoBERTa model works well for this task in general but fails to generalize in important cross-domain and cross-generator settings, demonstrating a tendency to overfit to spurious properties of the data. Then, we propose novel approaches based on features extracted from a frozen language model's embeddings that are able to outperform both the human accuracy level and previously considered baselines on the Real or Fake Text benchmark. Moreover, we adapt perplexity-based approaches for the boundary detection task and analyze their behaviour. We analyze the robustness of all proposed classifiers in cross-domain and cross-model settings, discovering important properties of the data that can negatively influence the performance of artificial text boundary detection algorithms.