 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDLM: Inverse-distilled Diffusion Language Models
Feb 22, 2026Diffusion Language Models (DLMs) have recently achieved strong results in text generation. However, their multi-step sampling leads to slow inference, limiting practical use. To address this, we extend Inverse Distillation, a technique originally developed to accelerate continuous diffusion models, to the discrete setting. Nonetheless, this extension introduces both theoretical and practical challenges. From a theoretical perspective, the inverse distillation objective lacks uniqueness guarantees, which may lead to suboptimal solutions. From a practical standpoint, backpropagation in the discrete space is non-trivial and often unstable. To overcome these challenges, we first provide a theoretical result demonstrating that our inverse formulation admits a unique solution, thereby ensuring valid optimization. We then introduce gradient-stable relaxations to support effective training. As a result, experiments on multiple DLMs show that our method, Inverse-distilled Diffusion Language Models (IDLM), reduces the number of inference steps by 4x-64x, while preserving the teacher model's entropy and generative perplexity.
T-pro 2.0: An Efficient Russian Hybrid-Reasoning Model and Playground
Dec 11, 2025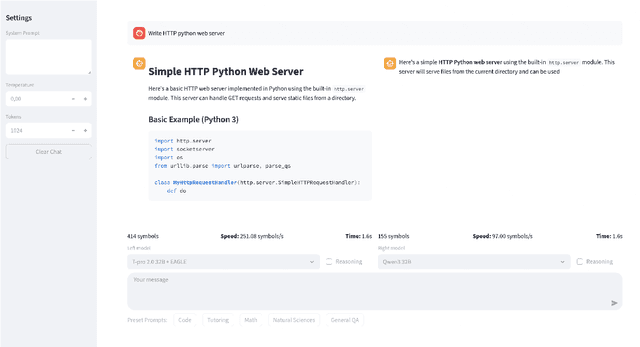

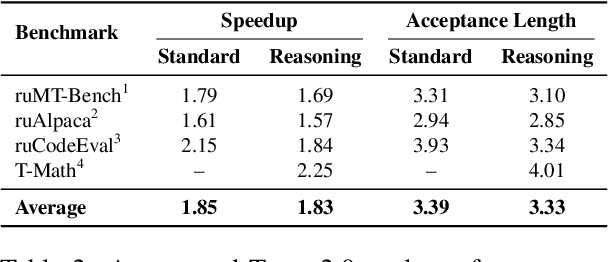

We introduce T-pro 2.0, an open-weight Russian LLM for hybrid reasoning and efficient inference. The model supports direct answering and reasoning-trace generation, using a Cyrillic-dense tokenizer and an adapted EAGLE speculative-decoding pipeline to reduce latency. To enable reproducible and extensible research, we release the model weights, the T-Wix 500k instruction corpus, the T-Math reasoning benchmark, and the EAGLE weights on Hugging Face. These resources allow users to study Russian-language reasoning and to extend or adapt both the model and the inference pipeline. A public web demo exposes reasoning and non-reasoning modes and illustrates the speedups achieved by our inference stack across domains. T-pro 2.0 thus serves as an accessible open system for building and evaluating efficient, practical Russian LLM applications.
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
StarCoder 2 and The Stack v2: The Next Generation
Feb 29, 2024



The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
Artificial Text Boundary Detection with Topological Data Analysis and Sliding Window Techniques
Nov 14, 2023
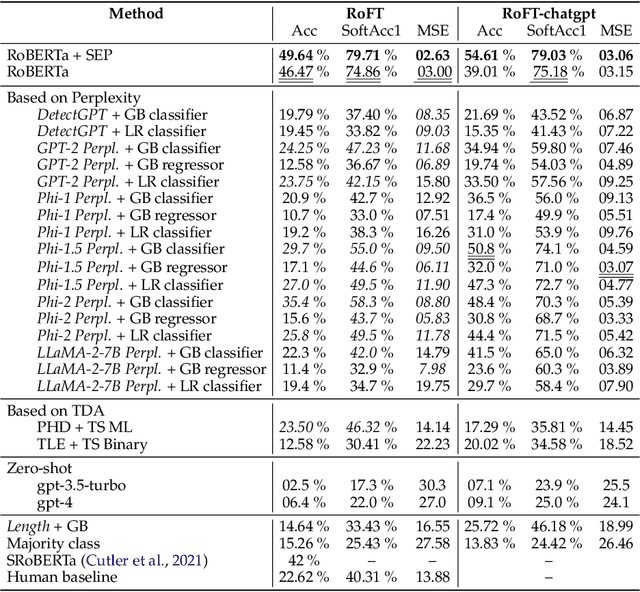
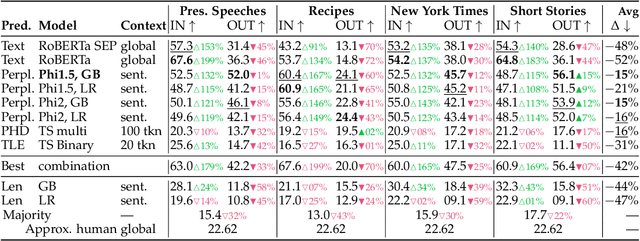
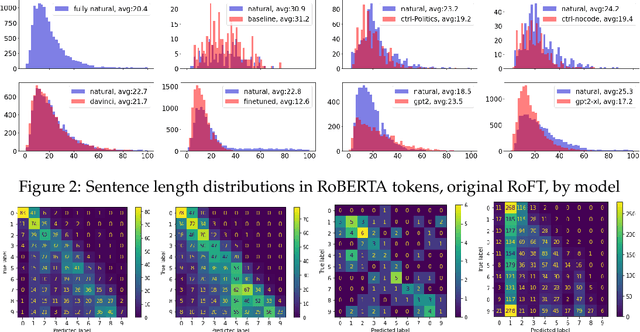
Due to the rapid development of text generation models, people increasingly often encounter texts that may start out as written by a human but then continue as machine-generated results of large language models. Detecting the boundary between human-written and machine-generated parts of such texts is a very challenging problem that has not received much attention in literature. In this work, we consider and compare a number of different approaches for this artificial text boundary detection problem, comparing several predictors over features of different nature. We show that supervised fine-tuning of the RoBERTa model works well for this task in general but fails to generalize in important cross-domain and cross-generator settings, demonstrating a tendency to overfit to spurious properties of the data. Then, we propose novel approaches based on features extracted from a frozen language model's embeddings that are able to outperform both the human accuracy level and previously considered baselines on the Real or Fake Text benchmark. Moreover, we adapt perplexity-based approaches for the boundary detection task and analyze their behaviour. We analyze the robustness of all proposed classifiers in cross-domain and cross-model settings, discovering important properties of the data that can negatively influence the performance of artificial text boundary detection algorithms.
CCT-Code: Cross-Consistency Training for Multilingual Clone Detection and Code Search
May 19, 2023We consider the clone detection and information retrieval problems for source code, well-known tasks important for any programming language. Although it is also an important and interesting problem to find code snippets that operate identically but are written in different programming languages, to the best of our knowledge multilingual clone detection has not been studied in literature. In this work, we formulate the multilingual clone detection problem and present XCD, a new benchmark dataset produced from the CodeForces submissions dataset. Moreover, we present a novel training procedure, called cross-consistency training (CCT), that we apply to train language models on source code in different programming languages. The resulting CCT-LM model, initialized with GraphCodeBERT and fine-tuned with CCT, achieves new state of the art, outperforming existing approaches on the POJ-104 clone detection benchmark with 95.67\% MAP and AdvTest code search benchmark with 47.18\% MRR; it also shows the best results on the newly created multilingual clone detection benchmark XCD across all programming languages.
Searching by Code: a New SearchBySnippet Dataset and SnippeR Retrieval Model for Searching by Code Snippets
May 19, 2023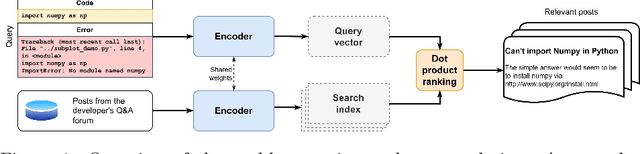
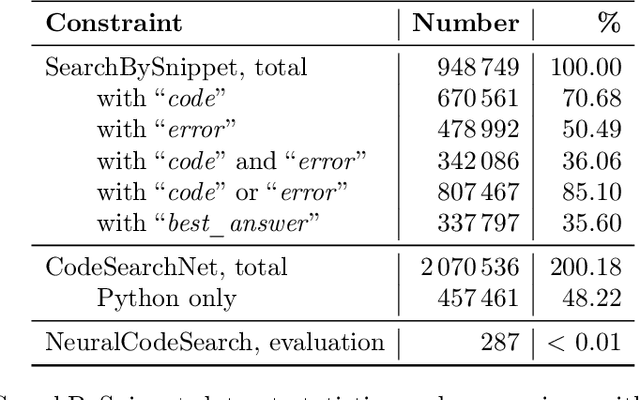
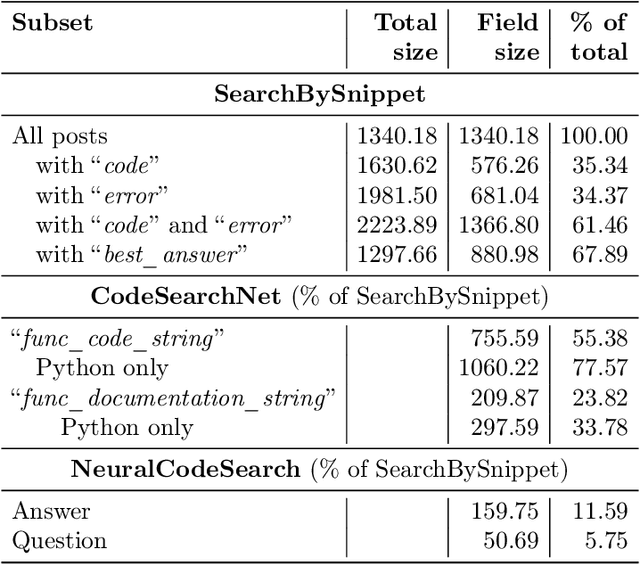
Code search is an important task that has seen many developments in recent years. However, previous attempts have mostly considered the problem of searching for code by a text query. We argue that using a code snippet (and possibly an associated traceback) as a query and looking for answers with bugfixing instructions and code samples is a natural use case that is not covered by existing approaches. Moreover, existing datasets use comments extracted from code rather than full-text descriptions as text, making them unsuitable for this use case. We present a new SearchBySnippet dataset implementing the search-by-code use case based on StackOverflow data; it turns out that in this setting, existing architectures fall short of the simplest BM25 baseline even after fine-tuning. We present a new single encoder model SnippeR that outperforms several strong baselines on the SearchBySnippet dataset with a result of 0.451 Recall@10; we propose the SearchBySnippet dataset and SnippeR as a new important benchmark for code search evaluation.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
SantaCoder: don't reach for the stars!
Jan 09, 2023



The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at https://hf.co/bigcode.