 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Self-Training for Code Generation via Reinforced Re-Ranking
Apr 13, 2025Generating high-quality code that solves complex programming tasks is challenging, especially with current decoder-based models that produce highly stochastic outputs. In code generation, even minor errors can easily break the entire solution. Leveraging multiple sampled solutions can significantly improve the overall output quality. One effective way to enhance code generation is by pairing a code generation model with a reranker model, which selects the best solution from the generated samples. We propose a novel iterative self-training approach for self-training reranker models using Proximal Policy Optimization (PPO), aimed at improving both reranking accuracy and the overall code generation process. Unlike traditional PPO approaches, where the focus is on optimizing a generative model with a reward model, our approach emphasizes the development of a robust reward/reranking model. This model improves the quality of generated code through reranking and addresses problems and errors that the reward model might overlook during PPO alignment with the reranker. Our method iteratively refines the training dataset by re-evaluating outputs, identifying high-scoring negative examples, and incorporating them into the training loop, that boosting model performance. Our evaluation on the MultiPL-E dataset demonstrates that our 13.4B parameter model outperforms a 33B model in code generation quality while being three times faster. Moreover, it achieves performance comparable to GPT-4 and surpasses it in one programming language.
Searching by Code: a New SearchBySnippet Dataset and SnippeR Retrieval Model for Searching by Code Snippets
May 19, 2023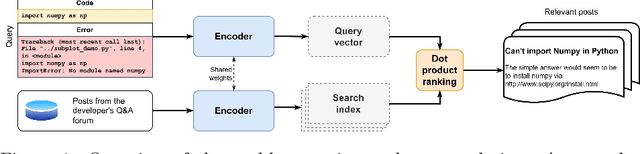
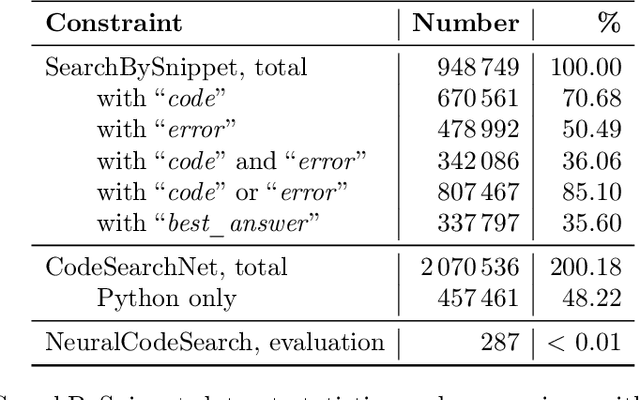
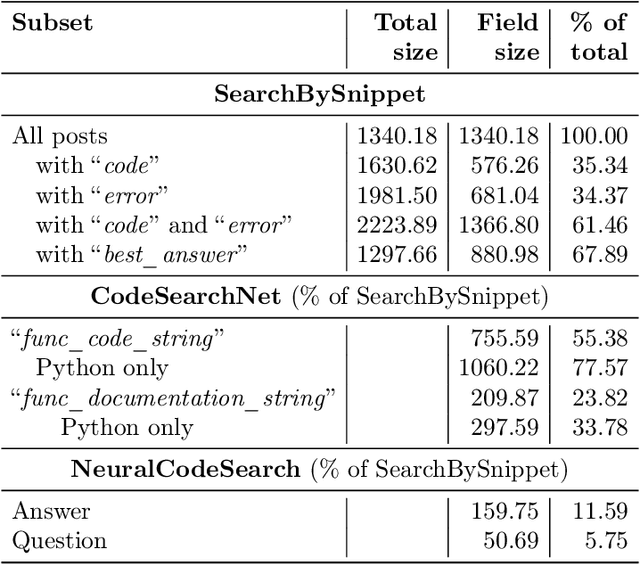
Code search is an important task that has seen many developments in recent years. However, previous attempts have mostly considered the problem of searching for code by a text query. We argue that using a code snippet (and possibly an associated traceback) as a query and looking for answers with bugfixing instructions and code samples is a natural use case that is not covered by existing approaches. Moreover, existing datasets use comments extracted from code rather than full-text descriptions as text, making them unsuitable for this use case. We present a new SearchBySnippet dataset implementing the search-by-code use case based on StackOverflow data; it turns out that in this setting, existing architectures fall short of the simplest BM25 baseline even after fine-tuning. We present a new single encoder model SnippeR that outperforms several strong baselines on the SearchBySnippet dataset with a result of 0.451 Recall@10; we propose the SearchBySnippet dataset and SnippeR as a new important benchmark for code search evaluation.
CCT-Code: Cross-Consistency Training for Multilingual Clone Detection and Code Search
May 19, 2023We consider the clone detection and information retrieval problems for source code, well-known tasks important for any programming language. Although it is also an important and interesting problem to find code snippets that operate identically but are written in different programming languages, to the best of our knowledge multilingual clone detection has not been studied in literature. In this work, we formulate the multilingual clone detection problem and present XCD, a new benchmark dataset produced from the CodeForces submissions dataset. Moreover, we present a novel training procedure, called cross-consistency training (CCT), that we apply to train language models on source code in different programming languages. The resulting CCT-LM model, initialized with GraphCodeBERT and fine-tuned with CCT, achieves new state of the art, outperforming existing approaches on the POJ-104 clone detection benchmark with 95.67\% MAP and AdvTest code search benchmark with 47.18\% MRR; it also shows the best results on the newly created multilingual clone detection benchmark XCD across all programming languages.