 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemmBERT: A Modern Multilingual Encoder with Annealed Language Learning
Sep 08, 2025Encoder-only languages models are frequently used for a variety of standard machine learning tasks, including classification and retrieval. However, there has been a lack of recent research for encoder models, especially with respect to multilingual models. We introduce mmBERT, an encoder-only language model pretrained on 3T tokens of multilingual text in over 1800 languages. To build mmBERT we introduce several novel elements, including an inverse mask ratio schedule and an inverse temperature sampling ratio. We add over 1700 low-resource languages to the data mix only during the decay phase, showing that it boosts performance dramatically and maximizes the gains from the relatively small amount of training data. Despite only including these low-resource languages in the short decay phase we achieve similar classification performance to models like OpenAI's o3 and Google's Gemini 2.5 Pro. Overall, we show that mmBERT significantly outperforms the previous generation of models on classification and retrieval tasks -- on both high and low-resource languages.
Seq vs Seq: An Open Suite of Paired Encoders and Decoders
Jul 15, 2025The large language model (LLM) community focuses almost exclusively on decoder-only language models, since they are easier to use for text generation. However, a large subset of the community still uses encoder-only models for tasks such as classification or retrieval. Previous work has attempted to compare these architectures, but is forced to make comparisons with models that have different numbers of parameters, training techniques, and datasets. We introduce the SOTA open-data Ettin suite of models: paired encoder-only and decoder-only models ranging from 17 million parameters to 1 billion, trained on up to 2 trillion tokens. Using the same recipe for both encoder-only and decoder-only models produces SOTA recipes in both categories for their respective sizes, beating ModernBERT as an encoder and Llama 3.2 and SmolLM2 as decoders. Like previous work, we find that encoder-only models excel at classification and retrieval tasks while decoders excel at generative tasks. However, we show that adapting a decoder model to encoder tasks (and vice versa) through continued training is subpar compared to using only the reverse objective (i.e. a 400M encoder outperforms a 1B decoder on MNLI, and vice versa for generative tasks). We open-source all artifacts of this study including training data, training order segmented by checkpoint, and 200+ checkpoints to allow future work to analyze or extend all aspects of training.
Certified Mitigation of Worst-Case LLM Copyright Infringement
Apr 22, 2025

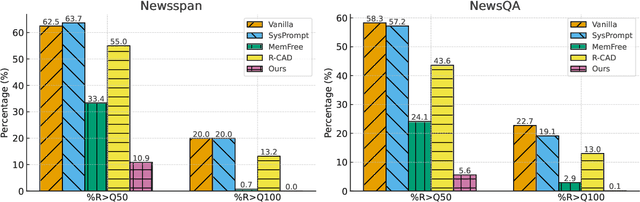
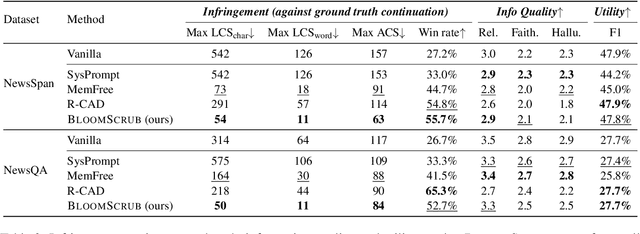
The exposure of large language models (LLMs) to copyrighted material during pre-training raises concerns about unintentional copyright infringement post deployment. This has driven the development of "copyright takedown" methods, post-training approaches aimed at preventing models from generating content substantially similar to copyrighted ones. While current mitigation approaches are somewhat effective for average-case risks, we demonstrate that they overlook worst-case copyright risks exhibits by the existence of long, verbatim quotes from copyrighted sources. We propose BloomScrub, a remarkably simple yet highly effective inference-time approach that provides certified copyright takedown. Our method repeatedly interleaves quote detection with rewriting techniques to transform potentially infringing segments. By leveraging efficient data sketches (Bloom filters), our approach enables scalable copyright screening even for large-scale real-world corpora. When quotes beyond a length threshold cannot be removed, the system can abstain from responding, offering certified risk reduction. Experimental results show that BloomScrub reduces infringement risk, preserves utility, and accommodates different levels of enforcement stringency with adaptive abstention. Our results suggest that lightweight, inference-time methods can be surprisingly effective for copyright prevention.
AdapterSwap: Continuous Training of LLMs with Data Removal and Access-Control Guarantees
Apr 12, 2024Large language models (LLMs) are increasingly capable of completing knowledge intensive tasks by recalling information from a static pretraining corpus. Here we are concerned with LLMs in the context of evolving data requirements. For instance: batches of new data that are introduced periodically; subsets of data with user-based access controls; or requirements on dynamic removal of documents with guarantees that associated knowledge cannot be recalled. We wish to satisfy these requirements while at the same time ensuring a model does not forget old information when new data becomes available. To address these issues, we introduce AdapterSwap, a training and inference scheme that organizes knowledge from a data collection into a set of low-rank adapters, which are dynamically composed during inference. Our experiments demonstrate AdapterSwap's ability to support efficient continual learning, while also enabling organizations to have fine-grained control over data access and deletion.
Verifiable by Design: Aligning Language Models to Quote from Pre-Training Data
Apr 05, 2024For humans to trust the fluent generations of large language models (LLMs), they must be able to verify their correctness against trusted, external sources. Recent efforts aim to increase verifiability through citations of retrieved documents or post-hoc provenance. However, such citations are prone to mistakes that further complicate their verifiability. To address these limitations, we tackle the verifiability goal with a different philosophy: we trivialize the verification process by developing models that quote verbatim statements from trusted sources in pre-training data. We propose Quote-Tuning, which demonstrates the feasibility of aligning LLMs to leverage memorized information and quote from pre-training data. Quote-Tuning quantifies quoting against large corpora with efficient membership inference tools, and uses the amount of quotes as an implicit reward signal to construct a synthetic preference dataset for quoting, without any human annotation. Next, the target model is aligned to quote using preference optimization algorithms. Experimental results show that Quote-Tuning significantly increases the percentage of LLM generation quoted verbatim from high-quality pre-training documents by 55% to 130% relative to untuned models while maintaining response quality. Further experiments demonstrate that Quote-Tuning generalizes quoting to out-of-domain data, is applicable in different tasks, and provides additional benefits to truthfulness. Quote-Tuning not only serves as a hassle-free method to increase quoting but also opens up avenues for improving LLM trustworthiness through better verifiability.
Dated Data: Tracing Knowledge Cutoffs in Large Language Models
Mar 19, 2024Released Large Language Models (LLMs) are often paired with a claimed knowledge cutoff date, or the dates at which training data was gathered. Such information is crucial for applications where the LLM must provide up to date information. However, this statement only scratches the surface: do all resources in the training data share the same knowledge cutoff date? Does the model's demonstrated knowledge for these subsets closely align to their cutoff dates? In this work, we define the notion of an effective cutoff. This is distinct from the LLM designer reported cutoff and applies separately to sub-resources and topics. We propose a simple approach to estimate effective cutoffs on the resource-level temporal alignment of an LLM by probing across versions of the data. Using this analysis, we find that effective cutoffs often differ from reported cutoffs. To understand the root cause of this observation, we conduct a direct large-scale analysis on open pre-training datasets. Our analysis reveals two reasons for these inconsistencies: (1) temporal biases of CommonCrawl data due to non-trivial amounts of old data in new dumps and (2) complications in LLM deduplication schemes involving semantic duplicates and lexical near-duplicates. Overall, our results show that knowledge cutoffs are not as simple as they have seemed and that care must be taken both by LLM dataset curators as well as practitioners who seek to use information from these models.
StarCoder 2 and The Stack v2: The Next Generation
Feb 29, 2024



The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
"According to ..." Prompting Language Models Improves Quoting from Pre-Training Data
May 22, 2023Large Language Models (LLMs) may hallucinate and generate fake information, despite pre-training on factual data. Inspired by the journalistic device of "according to sources", we propose according-to prompting: directing LLMs to ground responses against previously observed text. To quantify this grounding, we propose a novel evaluation metric (QUIP-Score) that measures the extent to which model-produced answers are directly found in underlying text corpora. We illustrate with experiments on Wikipedia that these prompts improve grounding under our metrics, with the additional benefit of often improving end-task performance. Furthermore, prompts that ask the model to decrease grounding (or to ground to other corpora) decrease grounding, indicating the ability of language models to increase or decrease grounded generations on request.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
Data Portraits: Recording Foundation Model Training Data
Mar 06, 2023Foundation models are trained on increasingly immense and opaque datasets. Even while these models are now key in AI system building, it can be difficult to answer the straightforward question: has the model already encountered a given example during training? We therefore propose a widespread adoption of Data Portraits: artifacts that record training data and allow for downstream inspection. First we outline the properties of such an artifact and discuss how existing solutions can be used to increase transparency. We then propose and implement a solution based on data sketching, stressing fast and space efficient querying. Using our tool, we document a popular large language modeling corpus (the Pile) and show that our solution enables answering questions about test set leakage and model plagiarism. Our tool is lightweight and fast, costing only 3% of the dataset size in overhead. We release a demo of our tools at dataportraits.org and call on dataset and model creators to release Data Portraits as a complement to current documentation practices.