 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT-PingEval: Evaluating Multi-Turn Collaboration with Private Information Games
Feb 27, 2026We present a scalable methodology for evaluating language models in multi-turn interactions, using a suite of collaborative games that require effective communication about private information. This enables an interactive scaling analysis, in which a fixed token budget is divided over a variable number of turns. We find that in many cases, language models are unable to use interactive collaboration to improve over the non-interactive baseline scenario in which one agent attempts to summarize its information and the other agent immediately acts -- despite substantial headroom. This suggests that state-of-the-art models still suffer from significant weaknesses in planning and executing multi-turn collaborative conversations. We analyze the linguistic features of these dialogues, assessing the roles of sycophancy, information density, and discourse coherence. While there is no single linguistic explanation for the collaborative weaknesses of contemporary language models, we note that humans achieve comparable task success at superior token efficiency by producing dialogues that are more coherent than those produced by most language models. The proactive management of private information is a defining feature of real-world communication, and we hope that MT-PingEval will drive further work towards improving this capability.
Bridging Kolmogorov Complexity and Deep Learning: Asymptotically Optimal Description Length Objectives for Transformers
Sep 26, 2025



The Minimum Description Length (MDL) principle offers a formal framework for applying Occam's razor in machine learning. However, its application to neural networks such as Transformers is challenging due to the lack of a principled, universal measure for model complexity. This paper introduces the theoretical notion of asymptotically optimal description length objectives, grounded in the theory of Kolmogorov complexity. We establish that a minimizer of such an objective achieves optimal compression, for any dataset, up to an additive constant, in the limit as model resource bounds increase. We prove that asymptotically optimal objectives exist for Transformers, building on a new demonstration of their computational universality. We further show that such objectives can be tractable and differentiable by constructing and analyzing a variational objective based on an adaptive Gaussian mixture prior. Our empirical analysis shows that this variational objective selects for a low-complexity solution with strong generalization on an algorithmic task, but standard optimizers fail to find such solutions from a random initialization, highlighting key optimization challenges. More broadly, by providing a theoretical framework for identifying description length objectives with strong asymptotic guarantees, we outline a potential path towards training neural networks that achieve greater compression and generalization.
Cost-Optimal Active AI Model Evaluation
Jun 09, 2025The development lifecycle of generative AI systems requires continual evaluation, data acquisition, and annotation, which is costly in both resources and time. In practice, rapid iteration often makes it necessary to rely on synthetic annotation data because of the low cost, despite the potential for substantial bias. In this paper, we develop novel, cost-aware methods for actively balancing the use of a cheap, but often inaccurate, weak rater -- such as a model-based autorater that is designed to automatically assess the quality of generated content -- with a more expensive, but also more accurate, strong rater alternative such as a human. More specifically, the goal of our approach is to produce a low variance, unbiased estimate of the mean of the target "strong" rating, subject to some total annotation budget. Building on recent work in active and prediction-powered statistical inference, we derive a family of cost-optimal policies for allocating a given annotation budget between weak and strong raters so as to maximize statistical efficiency. Using synthetic and real-world data, we empirically characterize the conditions under which these policies yield improvements over prior methods. We find that, especially in tasks where there is high variability in the difficulty of examples, our policies can achieve the same estimation precision at a far lower total annotation budget than standard evaluation methods.
Don't lie to your friends: Learning what you know from collaborative self-play
Mar 18, 2025To be helpful assistants, AI agents must be aware of their own capabilities and limitations. This includes knowing when to answer from parametric knowledge versus using tools, when to trust tool outputs, and when to abstain or hedge. Such capabilities are hard to teach through supervised fine-tuning because they require constructing examples that reflect the agent's specific capabilities. We therefore propose a radically new approach to teaching agents what they know: \emph{collaborative self-play}. We construct multi-agent collaborations in which the group is rewarded for collectively arriving at correct answers. The desired meta-knowledge emerges from the incentives built into the structure of the interaction. We focus on small societies of agents that have access to heterogeneous tools (corpus-specific retrieval), and therefore must collaborate to maximize their success while minimizing their effort. Experiments show that group-level rewards for multi-agent communities can induce policies that \emph{transfer} to improve tool use and selective prediction in settings where individual agents are deployed in isolation.
InfAlign: Inference-aware language model alignment
Dec 27, 2024Language model alignment has become a critical step in training modern generative language models. The goal of alignment is to finetune a reference model such that the win rate of a sample from the aligned model over a sample from the reference model is high, subject to a KL divergence constraint. Today, we are increasingly using inference-time algorithms (e.g., Best-of-N, controlled decoding, tree search) to decode from language models rather than standard sampling. However, the alignment objective does not capture such inference-time decoding procedures. We show that the existing alignment framework is sub-optimal in view of such inference-time methods. We then modify the alignment objective and propose a framework for inference-aware alignment (IAPO). We prove that for any inference-time decoding algorithm, the optimal solution that optimizes the inference-time win rate of the aligned policy against the reference policy is the solution to the typical RLHF problem with a transformation of the reward. This motivates us to provide the KL-regularized calibrate-and-transform RL (CTRL) algorithm to solve this problem, which involves a reward calibration step and a KL-regularized reward maximization step with a transformation of the calibrated reward. We particularize our study to two important inference-time strategies: best-of-N sampling and best-of-N jailbreaking, where N responses are sampled from the model and the one with the highest or lowest reward is selected. We propose specific transformations for these strategies and demonstrate that our framework offers significant improvements over existing state-of-the-art methods for language model alignment. Empirically, we outperform baselines that are designed without taking inference-time decoding into consideration by 8-12% and 4-9% on inference-time win rates over the Anthropic helpfulness and harmlessness dialog benchmark datasets.
ALTA: Compiler-Based Analysis of Transformers
Oct 23, 2024
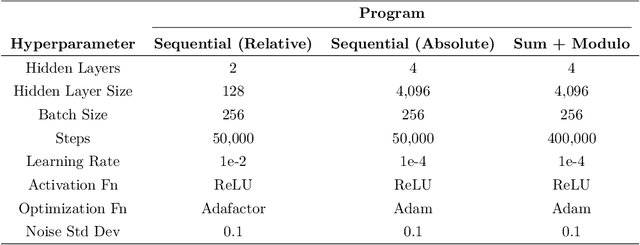

We propose a new programming language called ALTA and a compiler that can map ALTA programs to Transformer weights. ALTA is inspired by RASP, a language proposed by Weiss et al. (2021), and Tracr (Lindner et al., 2023), a compiler from RASP programs to Transformer weights. ALTA complements and extends this prior work, offering the ability to express loops and to compile programs to Universal Transformers, among other advantages. ALTA allows us to constructively show how Transformers can represent length-invariant algorithms for computing parity and addition, as well as a solution to the SCAN benchmark of compositional generalization tasks, without requiring intermediate scratchpad decoding steps. We also propose tools to analyze cases where the expressibility of an algorithm is established, but end-to-end training on a given training set fails to induce behavior consistent with the desired algorithm. To this end, we explore training from ALTA execution traces as a more fine-grained supervision signal. This enables additional experiments and theoretical analyses relating the learnability of various algorithms to data availability and modeling decisions, such as positional encodings. We make the ALTA framework -- language specification, symbolic interpreter, and weight compiler -- available to the community to enable further applications and insights.
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
Oct 10, 2024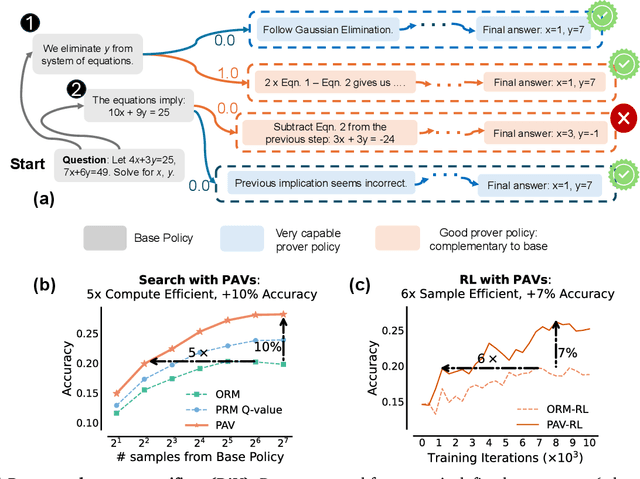
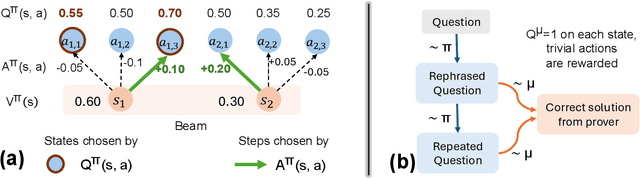
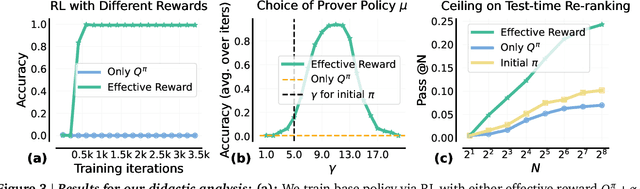
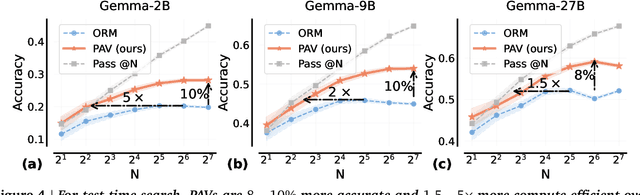
A promising approach for improving reasoning in large language models is to use process reward models (PRMs). PRMs provide feedback at each step of a multi-step reasoning trace, potentially improving credit assignment over outcome reward models (ORMs) that only provide feedback at the final step. However, collecting dense, per-step human labels is not scalable, and training PRMs from automatically-labeled data has thus far led to limited gains. To improve a base policy by running search against a PRM or using it as dense rewards for reinforcement learning (RL), we ask: "How should we design process rewards?". Our key insight is that, to be effective, the process reward for a step should measure progress: a change in the likelihood of producing a correct response in the future, before and after taking the step, corresponding to the notion of step-level advantages in RL. Crucially, this progress should be measured under a prover policy distinct from the base policy. We theoretically characterize the set of good provers and our results show that optimizing process rewards from such provers improves exploration during test-time search and online RL. In fact, our characterization shows that weak prover policies can substantially improve a stronger base policy, which we also observe empirically. We validate our claims by training process advantage verifiers (PAVs) to predict progress under such provers, and show that compared to ORMs, test-time search against PAVs is $>8\%$ more accurate, and $1.5-5\times$ more compute-efficient. Online RL with dense rewards from PAVs enables one of the first results with $5-6\times$ gain in sample efficiency, and $>6\%$ gain in accuracy, over ORMs.
Predicting the Target Word of Game-playing Conversations using a Low-Rank Dialect Adapter for Decoder Models
Aug 31, 2024



Dialect adapters that improve the performance of LLMs for NLU tasks on certain sociolects/dialects/national varieties ('dialects' for the sake of brevity) have been reported for encoder models. In this paper, we extend the idea of dialect adapters to decoder models in our architecture called LoRDD. Using MD-3, a publicly available dataset of word game-playing conversations between dialectal speakers, our task is Target Word Prediction (TWP) from a masked conversation. LoRDD combines task adapters and dialect adapters where the latter employ contrastive learning on pseudo-parallel conversations from MD-3. Our results for en-IN conversations on two models (Mistral and Gemma) show that LoRDD outperforms four baselines on TWP, while bridging the performance gap with en-US by 12% on word similarity and 25% on accuracy. The focused contribution of LoRDD is in its promise for dialect adaptation of decoder models.
Robust Preference Optimization through Reward Model Distillation
May 29, 2024Language model (LM) post-training (or alignment) involves maximizing a reward function that is derived from preference annotations. Direct Preference Optimization (DPO) is a popular offline alignment method that trains a policy directly on preference data without the need to train a reward model or apply reinforcement learning. However, typical preference datasets have only a single, or at most a few, annotation per preference pair, which causes DPO to overconfidently assign rewards that trend towards infinite magnitude. This frequently leads to degenerate policies, sometimes causing even the probabilities of the preferred generations to go to zero. In this work, we analyze this phenomenon and propose distillation to get a better proxy for the true preference distribution over generation pairs: we train the LM to produce probabilities that match the distribution induced by a reward model trained on the preference data. Moreover, to account for uncertainty in the reward model we are distilling from, we optimize against a family of reward models that, as a whole, is likely to include at least one reasonable proxy for the preference distribution. Our results show that distilling from such a family of reward models leads to improved robustness to distribution shift in preference annotations, while preserving the simple supervised nature of DPO.
Reuse Your Rewards: Reward Model Transfer for Zero-Shot Cross-Lingual Alignment
Apr 18, 2024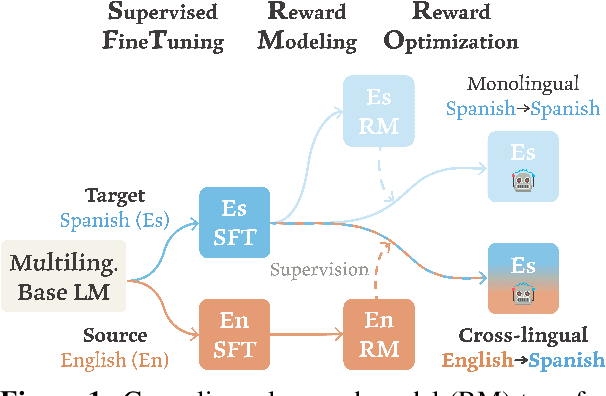
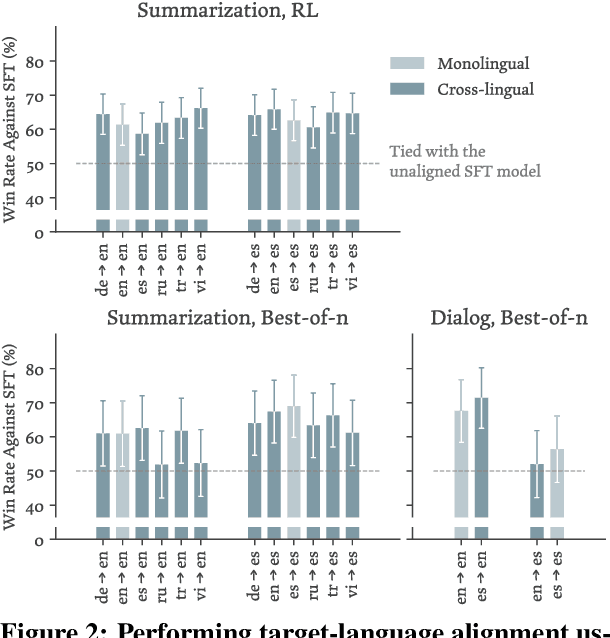
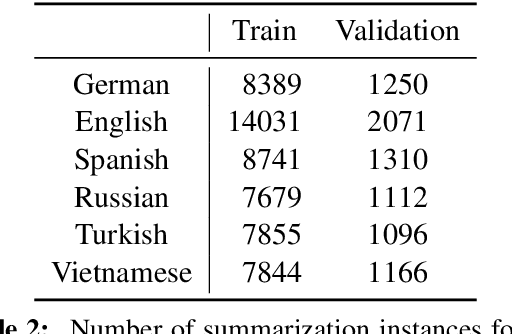
Aligning language models (LMs) based on human-annotated preference data is a crucial step in obtaining practical and performant LM-based systems. However, multilingual human preference data are difficult to obtain at scale, making it challenging to extend this framework to diverse languages. In this work, we evaluate a simple approach for zero-shot cross-lingual alignment, where a reward model is trained on preference data in one source language and directly applied to other target languages. On summarization and open-ended dialog generation, we show that this method is consistently successful under comprehensive evaluation settings, including human evaluation: cross-lingually aligned models are preferred by humans over unaligned models on up to >70% of evaluation instances. We moreover find that a different-language reward model sometimes yields better aligned models than a same-language reward model. We also identify best practices when there is no language-specific data for even supervised finetuning, another component in alignment.