 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Understanding challenges to the interpretation of disaggregated evaluations of algorithmic fairness
Jun 04, 2025Disaggregated evaluation across subgroups is critical for assessing the fairness of machine learning models, but its uncritical use can mislead practitioners. We show that equal performance across subgroups is an unreliable measure of fairness when data are representative of the relevant populations but reflective of real-world disparities. Furthermore, when data are not representative due to selection bias, both disaggregated evaluation and alternative approaches based on conditional independence testing may be invalid without explicit assumptions regarding the bias mechanism. We use causal graphical models to predict metric stability across subgroups under different data generating processes. Our framework suggests complementing disaggregated evaluations with explicit causal assumptions and analysis to control for confounding and distribution shift, including conditional independence testing and weighted performance estimation. These findings have broad implications for how practitioners design and interpret model assessments given the ubiquity of disaggregated evaluation.
Utility-inspired Reward Transformations Improve Reinforcement Learning Training of Language Models
Jan 08, 2025Current methods that train large language models (LLMs) with reinforcement learning feedback, often resort to averaging outputs of multiple rewards functions during training. This overlooks crucial aspects of individual reward dimensions and inter-reward dependencies that can lead to sub-optimal outcomes in generations. In this work, we show how linear aggregation of rewards exhibits some vulnerabilities that can lead to undesired properties of generated text. We then propose a transformation of reward functions inspired by economic theory of utility functions (specifically Inada conditions), that enhances sensitivity to low reward values while diminishing sensitivity to already high values. We compare our approach to the existing baseline methods that linearly aggregate rewards and show how the Inada-inspired reward feedback is superior to traditional weighted averaging. We quantitatively and qualitatively analyse the difference in the methods, and see that models trained with Inada-transformations score as more helpful while being less harmful.
InfAlign: Inference-aware language model alignment
Dec 27, 2024Language model alignment has become a critical step in training modern generative language models. The goal of alignment is to finetune a reference model such that the win rate of a sample from the aligned model over a sample from the reference model is high, subject to a KL divergence constraint. Today, we are increasingly using inference-time algorithms (e.g., Best-of-N, controlled decoding, tree search) to decode from language models rather than standard sampling. However, the alignment objective does not capture such inference-time decoding procedures. We show that the existing alignment framework is sub-optimal in view of such inference-time methods. We then modify the alignment objective and propose a framework for inference-aware alignment (IAPO). We prove that for any inference-time decoding algorithm, the optimal solution that optimizes the inference-time win rate of the aligned policy against the reference policy is the solution to the typical RLHF problem with a transformation of the reward. This motivates us to provide the KL-regularized calibrate-and-transform RL (CTRL) algorithm to solve this problem, which involves a reward calibration step and a KL-regularized reward maximization step with a transformation of the calibrated reward. We particularize our study to two important inference-time strategies: best-of-N sampling and best-of-N jailbreaking, where N responses are sampled from the model and the one with the highest or lowest reward is selected. We propose specific transformations for these strategies and demonstrate that our framework offers significant improvements over existing state-of-the-art methods for language model alignment. Empirically, we outperform baselines that are designed without taking inference-time decoding into consideration by 8-12% and 4-9% on inference-time win rates over the Anthropic helpfulness and harmlessness dialog benchmark datasets.
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
Oct 10, 2024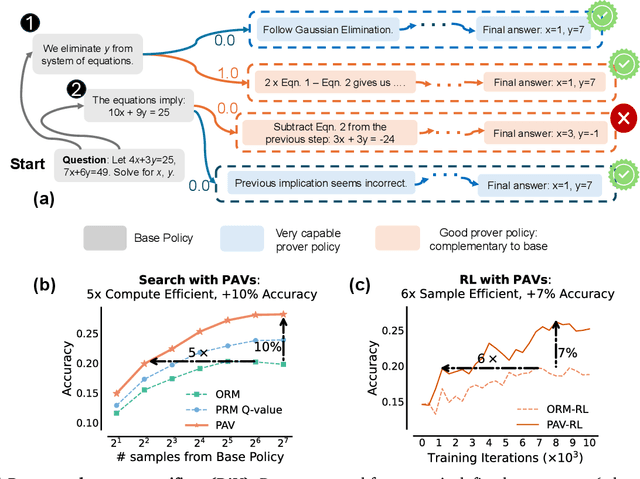
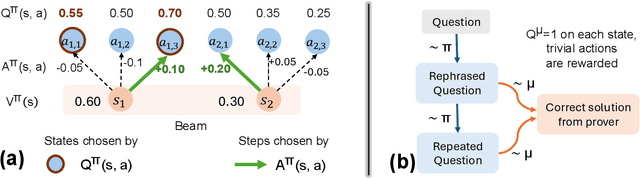
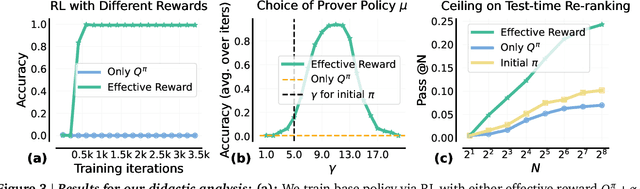
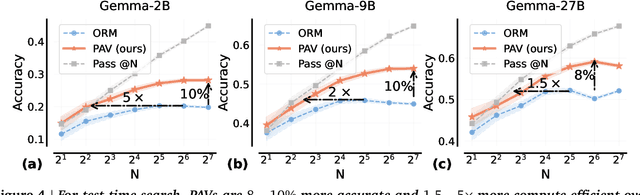
A promising approach for improving reasoning in large language models is to use process reward models (PRMs). PRMs provide feedback at each step of a multi-step reasoning trace, potentially improving credit assignment over outcome reward models (ORMs) that only provide feedback at the final step. However, collecting dense, per-step human labels is not scalable, and training PRMs from automatically-labeled data has thus far led to limited gains. To improve a base policy by running search against a PRM or using it as dense rewards for reinforcement learning (RL), we ask: "How should we design process rewards?". Our key insight is that, to be effective, the process reward for a step should measure progress: a change in the likelihood of producing a correct response in the future, before and after taking the step, corresponding to the notion of step-level advantages in RL. Crucially, this progress should be measured under a prover policy distinct from the base policy. We theoretically characterize the set of good provers and our results show that optimizing process rewards from such provers improves exploration during test-time search and online RL. In fact, our characterization shows that weak prover policies can substantially improve a stronger base policy, which we also observe empirically. We validate our claims by training process advantage verifiers (PAVs) to predict progress under such provers, and show that compared to ORMs, test-time search against PAVs is $>8\%$ more accurate, and $1.5-5\times$ more compute-efficient. Online RL with dense rewards from PAVs enables one of the first results with $5-6\times$ gain in sample efficiency, and $>6\%$ gain in accuracy, over ORMs.
Robust Preference Optimization through Reward Model Distillation
May 29, 2024Language model (LM) post-training (or alignment) involves maximizing a reward function that is derived from preference annotations. Direct Preference Optimization (DPO) is a popular offline alignment method that trains a policy directly on preference data without the need to train a reward model or apply reinforcement learning. However, typical preference datasets have only a single, or at most a few, annotation per preference pair, which causes DPO to overconfidently assign rewards that trend towards infinite magnitude. This frequently leads to degenerate policies, sometimes causing even the probabilities of the preferred generations to go to zero. In this work, we analyze this phenomenon and propose distillation to get a better proxy for the true preference distribution over generation pairs: we train the LM to produce probabilities that match the distribution induced by a reward model trained on the preference data. Moreover, to account for uncertainty in the reward model we are distilling from, we optimize against a family of reward models that, as a whole, is likely to include at least one reasonable proxy for the preference distribution. Our results show that distilling from such a family of reward models leads to improved robustness to distribution shift in preference annotations, while preserving the simple supervised nature of DPO.
A Toolbox for Surfacing Health Equity Harms and Biases in Large Language Models
Mar 18, 2024Large language models (LLMs) hold immense promise to serve complex health information needs but also have the potential to introduce harm and exacerbate health disparities. Reliably evaluating equity-related model failures is a critical step toward developing systems that promote health equity. In this work, we present resources and methodologies for surfacing biases with potential to precipitate equity-related harms in long-form, LLM-generated answers to medical questions and then conduct an empirical case study with Med-PaLM 2, resulting in the largest human evaluation study in this area to date. Our contributions include a multifactorial framework for human assessment of LLM-generated answers for biases, and EquityMedQA, a collection of seven newly-released datasets comprising both manually-curated and LLM-generated questions enriched for adversarial queries. Both our human assessment framework and dataset design process are grounded in an iterative participatory approach and review of possible biases in Med-PaLM 2 answers to adversarial queries. Through our empirical study, we find that the use of a collection of datasets curated through a variety of methodologies, coupled with a thorough evaluation protocol that leverages multiple assessment rubric designs and diverse rater groups, surfaces biases that may be missed via narrower evaluation approaches. Our experience underscores the importance of using diverse assessment methodologies and involving raters of varying backgrounds and expertise. We emphasize that while our framework can identify specific forms of bias, it is not sufficient to holistically assess whether the deployment of an AI system promotes equitable health outcomes. We hope the broader community leverages and builds on these tools and methods towards realizing a shared goal of LLMs that promote accessible and equitable healthcare for all.
The Case for Globalizing Fairness: A Mixed Methods Study on Colonialism, AI, and Health in Africa
Mar 11, 2024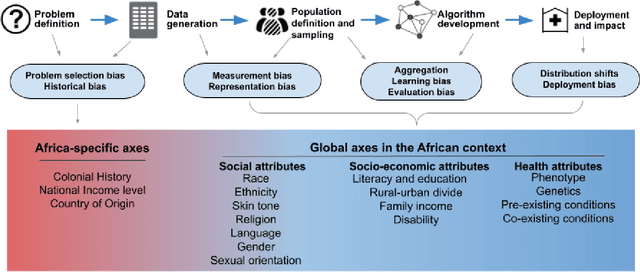
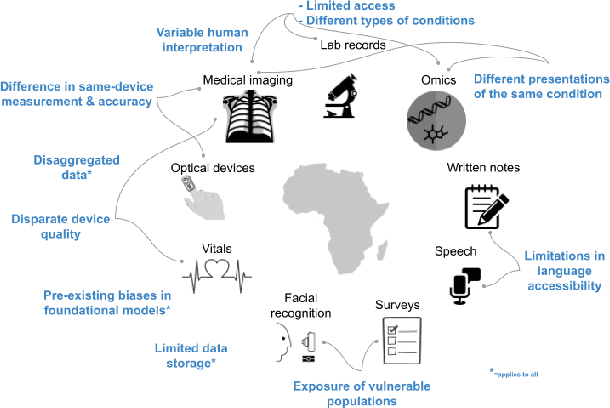
With growing application of machine learning (ML) technologies in healthcare, there have been calls for developing techniques to understand and mitigate biases these systems may exhibit. Fair-ness considerations in the development of ML-based solutions for health have particular implications for Africa, which already faces inequitable power imbalances between the Global North and South.This paper seeks to explore fairness for global health, with Africa as a case study. We conduct a scoping review to propose axes of disparities for fairness consideration in the African context and delineate where they may come into play in different ML-enabled medical modalities. We then conduct qualitative research studies with 672 general population study participants and 28 experts inML, health, and policy focused on Africa to obtain corroborative evidence on the proposed axes of disparities. Our analysis focuses on colonialism as the attribute of interest and examines the interplay between artificial intelligence (AI), health, and colonialism. Among the pre-identified attributes, we found that colonial history, country of origin, and national income level were specific axes of disparities that participants believed would cause an AI system to be biased.However, there was also divergence of opinion between experts and general population participants. Whereas experts generally expressed a shared view about the relevance of colonial history for the development and implementation of AI technologies in Africa, the majority of the general population participants surveyed did not think there was a direct link between AI and colonialism. Based on these findings, we provide practical recommendations for developing fairness-aware ML solutions for health in Africa.
Bias in Language Models: Beyond Trick Tests and Toward RUTEd Evaluation
Feb 20, 2024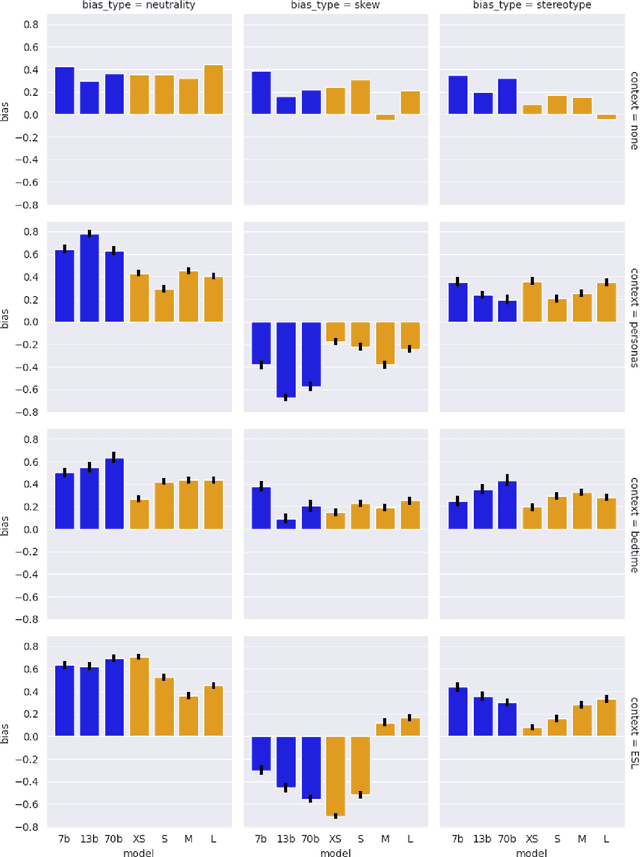
Bias benchmarks are a popular method for studying the negative impacts of bias in LLMs, yet there has been little empirical investigation of whether these benchmarks are actually indicative of how real world harm may manifest in the real world. In this work, we study the correspondence between such decontextualized "trick tests" and evaluations that are more grounded in Realistic Use and Tangible {Effects (i.e. RUTEd evaluations). We explore this correlation in the context of gender-occupation bias--a popular genre of bias evaluation. We compare three de-contextualized evaluations adapted from the current literature to three analogous RUTEd evaluations applied to long-form content generation. We conduct each evaluation for seven instruction-tuned LLMs. For the RUTEd evaluations, we conduct repeated trials of three text generation tasks: children's bedtime stories, user personas, and English language learning exercises. We found no correspondence between trick tests and RUTEd evaluations. Specifically, selecting the least biased model based on the de-contextualized results coincides with selecting the model with the best performance on RUTEd evaluations only as often as random chance. We conclude that evaluations that are not based in realistic use are likely insufficient to mitigate and assess bias and real-world harms.
Transforming and Combining Rewards for Aligning Large Language Models
Feb 01, 2024A common approach for aligning language models to human preferences is to first learn a reward model from preference data, and then use this reward model to update the language model. We study two closely related problems that arise in this approach. First, any monotone transformation of the reward model preserves preference ranking; is there a choice that is ``better'' than others? Second, we often wish to align language models to multiple properties: how should we combine multiple reward models? Using a probabilistic interpretation of the alignment procedure, we identify a natural choice for transformation for (the common case of) rewards learned from Bradley-Terry preference models. This derived transformation has two important properties. First, it emphasizes improving poorly-performing outputs, rather than outputs that already score well. This mitigates both underfitting (where some prompts are not improved) and reward hacking (where the model learns to exploit misspecification of the reward model). Second, it enables principled aggregation of rewards by linking summation to logical conjunction: the sum of transformed rewards corresponds to the probability that the output is ``good'' in all measured properties, in a sense we make precise. Experiments aligning language models to be both helpful and harmless using RLHF show substantial improvements over the baseline (non-transformed) approach.