 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding challenges to the interpretation of disaggregated evaluations of algorithmic fairness
Jun 04, 2025Disaggregated evaluation across subgroups is critical for assessing the fairness of machine learning models, but its uncritical use can mislead practitioners. We show that equal performance across subgroups is an unreliable measure of fairness when data are representative of the relevant populations but reflective of real-world disparities. Furthermore, when data are not representative due to selection bias, both disaggregated evaluation and alternative approaches based on conditional independence testing may be invalid without explicit assumptions regarding the bias mechanism. We use causal graphical models to predict metric stability across subgroups under different data generating processes. Our framework suggests complementing disaggregated evaluations with explicit causal assumptions and analysis to control for confounding and distribution shift, including conditional independence testing and weighted performance estimation. These findings have broad implications for how practitioners design and interpret model assessments given the ubiquity of disaggregated evaluation.
Machine Learning for Health symposium 2024 -- Findings track
Mar 02, 2025A collection of the accepted Findings papers that were presented at the 4th Machine Learning for Health symposium (ML4H 2024), which was held on December 15-16, 2024, in Vancouver, BC, Canada. ML4H 2024 invited high-quality submissions describing innovative research in a variety of health-related disciplines including healthcare, biomedicine, and public health. Works could be submitted to either the archival Proceedings track, or the non-archival Findings track. The Proceedings track targeted mature, cohesive works with technical sophistication and high-impact relevance to health. The Findings track promoted works that would spark new insights, collaborations, and discussions at ML4H. Both tracks were given the opportunity to share their work through the in-person poster session. All the manuscripts submitted to ML4H Symposium underwent a double-blind peer-review process.
Disparate Effect Of Missing Mediators On Transportability of Causal Effects
Mar 13, 2024



Transported mediation effects provide an avenue to understand how upstream interventions (such as improved neighborhood conditions like green spaces) would work differently when applied to different populations as a result of factors that mediate the effects. However, when mediators are missing in the population where the effect is to be transported, these estimates could be biased. We study this issue of missing mediators, motivated by challenges in public health, wherein mediators can be missing, not at random. We propose a sensitivity analysis framework that quantifies the impact of missing mediator data on transported mediation effects. This framework enables us to identify the settings under which the conditional transported mediation effect is rendered insignificant for the subgroup with missing mediator data. Specifically, we provide the bounds on the transported mediation effect as a function of missingness. We then apply the framework to longitudinal data from the Moving to Opportunity Study, a large-scale housing voucher experiment, to quantify the effect of missing mediators on transport effect estimates of voucher receipt, an upstream intervention on living location, in childhood on subsequent risk of mental health or substance use disorder mediated through parental health across sites. Our findings provide a tangible understanding of how much missing data can be withstood for unbiased effect estimates.
Impact on Public Health Decision Making by Utilizing Big Data Without Domain Knowledge
Feb 08, 2024New data sources, and artificial intelligence (AI) methods to extract information from them are becoming plentiful, and relevant to decision making in many societal applications. An important example is street view imagery, available in over 100 countries, and considered for applications such as assessing built environment aspects in relation to community health outcomes. Relevant to such uses, important examples of bias in the use of AI are evident when decision-making based on data fails to account for the robustness of the data, or predictions are based on spurious correlations. To study this risk, we utilize 2.02 million GSV images along with health, demographic, and socioeconomic data from New York City. Initially, we demonstrate that built environment characteristics inferred from GSV labels at the intra-city level may exhibit inadequate alignment with the ground truth. We also find that the average individual-level behavior of physical inactivity significantly mediates the impact of built environment features by census tract, as measured through GSV. Finally, using a causal framework which accounts for these mediators of environmental impacts on health, we find that altering 10% of samples in the two lowest tertiles would result in a 4.17 (95% CI 3.84 to 4.55) or 17.2 (95% CI 14.4 to 21.3) times bigger decrease on the prevalence of obesity or diabetes, than the same proportional intervention on the number of crosswalks by census tract. This work illustrates important issues of robustness and model specification for informing effective allocation of interventions using new data sources.
Understanding Disparities in Post Hoc Machine Learning Explanation
Jan 25, 2024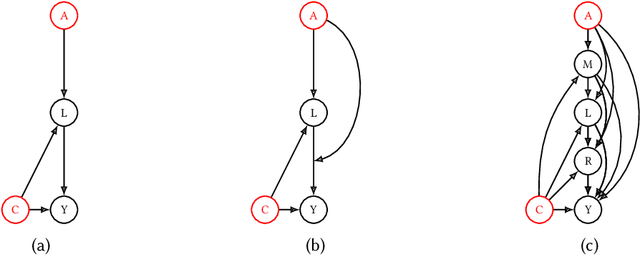
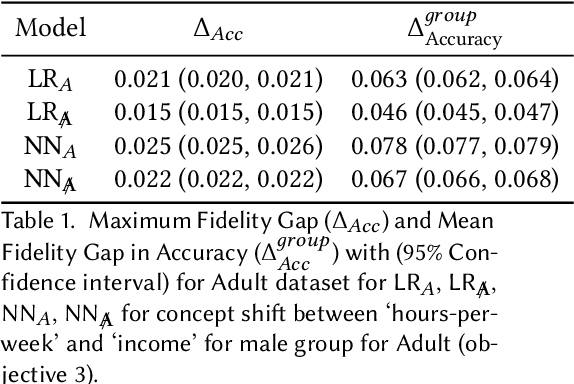
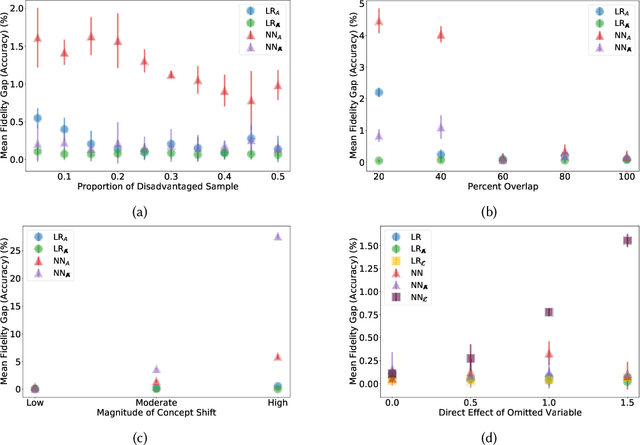
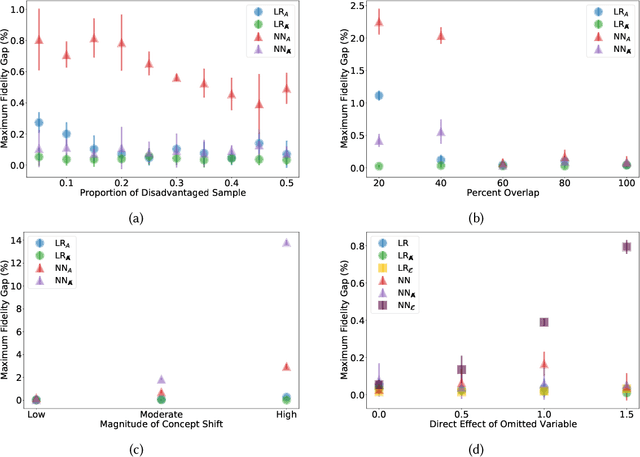
Previous work has highlighted that existing post-hoc explanation methods exhibit disparities in explanation fidelity (across 'race' and 'gender' as sensitive attributes), and while a large body of work focuses on mitigating these issues at the explanation metric level, the role of the data generating process and black box model in relation to explanation disparities remains largely unexplored. Accordingly, through both simulations as well as experiments on a real-world dataset, we specifically assess challenges to explanation disparities that originate from properties of the data: limited sample size, covariate shift, concept shift, omitted variable bias, and challenges based on model properties: inclusion of the sensitive attribute and appropriate functional form. Through controlled simulation analyses, our study demonstrates that increased covariate shift, concept shift, and omission of covariates increase explanation disparities, with the effect pronounced higher for neural network models that are better able to capture the underlying functional form in comparison to linear models. We also observe consistent findings regarding the effect of concept shift and omitted variable bias on explanation disparities in the Adult income dataset. Overall, results indicate that disparities in model explanations can also depend on data and model properties. Based on this systematic investigation, we provide recommendations for the design of explanation methods that mitigate undesirable disparities.
Causal Multi-Level Fairness
Oct 14, 2020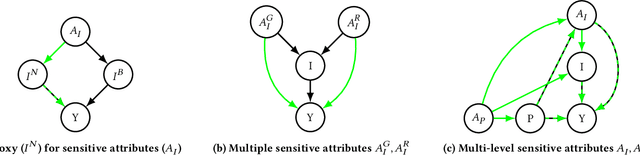
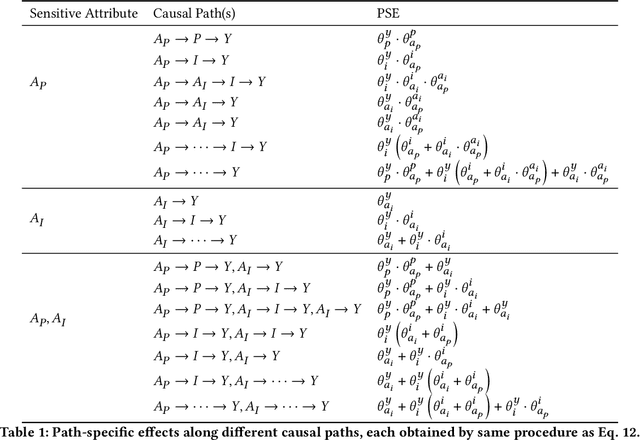

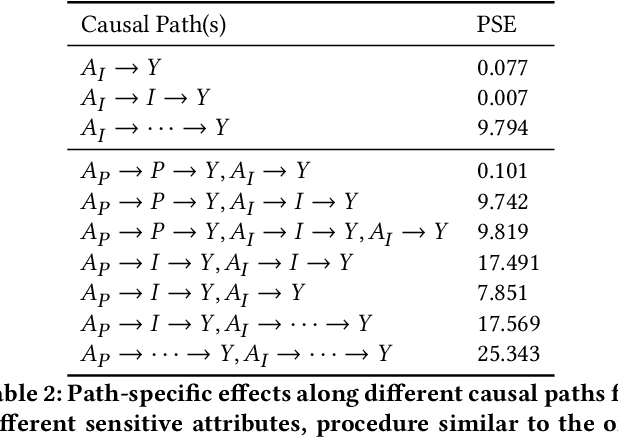
Algorithmic systems are known to impact marginalized groups severely, and more so, if all sources of bias are not considered. While work in algorithmic fairness to-date has primarily focused on addressing discrimination due to individually linked attributes, social science research elucidates how some properties we link to individuals can be conceptualized as having causes at population (e.g. structural/social) levels and it may be important to be fair to attributes at multiple levels. For example, instead of simply considering race as a protected attribute of an individual, it can be thought of as the perceived race of an individual which in turn may be affected by neighborhood-level factors. This multi-level conceptualization is relevant to questions of fairness, as it may not only be important to take into account if the individual belonged to another demographic group, but also if the individual received advantaged treatment at the population-level. In this paper, we formalize the problem of multi-level fairness using tools from causal inference in a manner that allows one to assess and account for effects of sensitive attributes at multiple levels. We show importance of the problem by illustrating residual unfairness if population-level sensitive attributes are not accounted for. Further, in the context of a real-world task of predicting income based on population and individual-level attributes, we demonstrate an approach for mitigating unfairness due to multi-level sensitive attributes.
Machine Learning in Population and Public Health
Jul 21, 2020
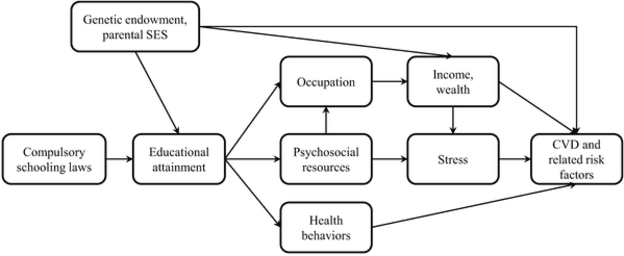
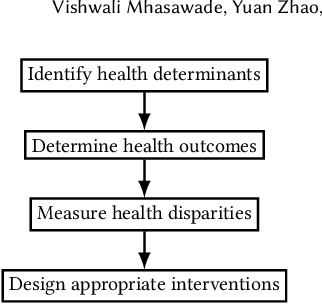
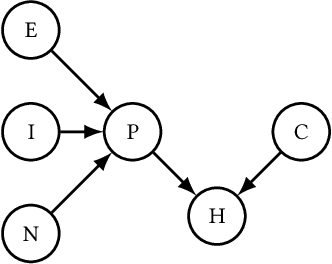
Research in population and public health focuses on the mechanisms between different cultural, social, and environmental factors and their effect on the health, of not just individuals, but communities as a whole. We present here a very brief introduction into research in these fields, as well as connections to existing machine learning work to help activate the machine learning community on such topics and highlight specific opportunities where machine learning, public and population health may synergize to better achieve health equity.
Fair Predictors under Distribution Shift
Nov 02, 2019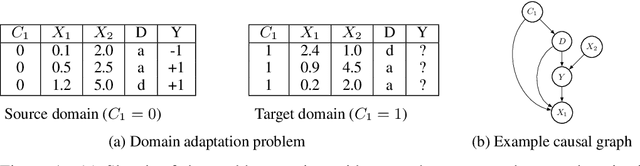


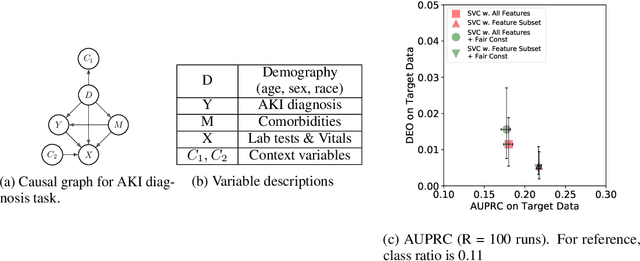
Recent work on fair machine learning adds to a growing set of algorithmic safeguards required for deployment in high societal impact areas. A fundamental concern with model deployment is to guarantee stable performance under changes in data distribution. Extensive work in domain adaptation addresses this concern, albeit with the notion of stability limited to that of predictive performance. We provide conditions under which a stable model both in terms of prediction and fairness performance can be trained. Building on the problem setup of causal domain adaptation, we select a subset of features for training predictors with fairness constraints such that risk with respect to an unseen target data distribution is minimized. Advantages of the approach are demonstrated on synthetic datasets and on the task of diagnosing acute kidney injury in a real-world dataset under an instance of measurement policy shift and selection bias.
Population-aware Hierarchical Bayesian Domain Adaptation via Multiple-component Invariant Learning
Sep 13, 2019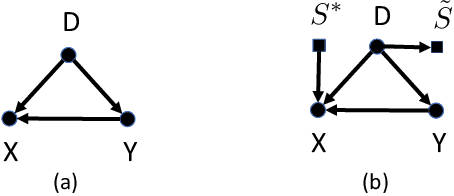
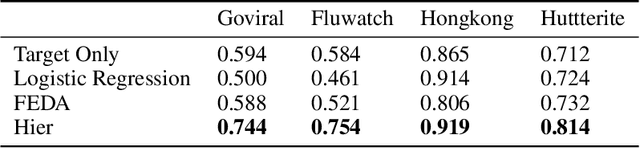
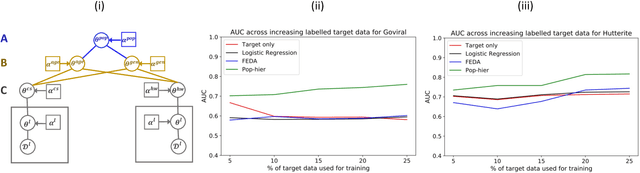
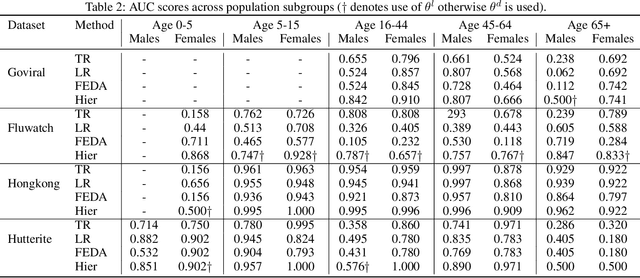
While machine learning is rapidly being developed and deployed in health settings such as influenza prediction, there are critical challenges in using data from one environment in another due to variability in features; even within disease labels there can be differences (e.g. "fever" may mean something different reported in a doctor's office versus in an online app). Moreover, models are often built on passive, observational data which contain different distributions of population subgroups (e.g. men or women). Thus, there are two forms of instability between environments in this observational transport problem. We first harness knowledge from health to conceptualize the underlying causal structure of this problem in a health outcome prediction task. Based on sources of stability in the model, we posit that for human-sourced data and health prediction tasks we can combine environment and population information in a novel population-aware hierarchical Bayesian domain adaptation framework that harnesses multiple invariant components through population attributes when needed. We study the conditions under which invariant learning fails, leading to reliance on the environment-specific attributes. Experimental results for an influenza prediction task on four datasets gathered from different contexts show the model can improve prediction in the case of largely unlabelled target data from a new environment and different constituent population, by harnessing both environment and population invariant information. This work represents a novel, principled way to address a critical challenge by blending domain (health) knowledge and algorithmic innovation. The proposed approach will have a significant impact in many social settings wherein who and where the data comes from matters.
Population-aware Hierarchical Bayesian Domain Adaptation
Nov 21, 2018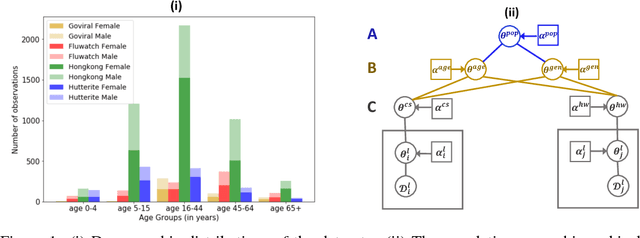
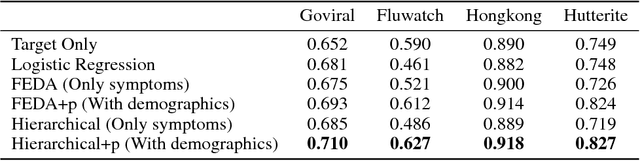
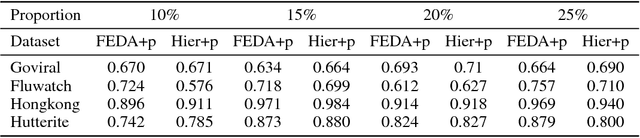
Population attributes are essential in health for understanding who the data represents and precision medicine efforts. Even within disease infection labels, patients can exhibit significant variability; "fever" may mean something different when reported in a doctor's office versus from an online app, precluding directly learning across different datasets for the same prediction task. This problem falls into the domain adaptation paradigm. However, research in this area has to-date not considered who generates the data; symptoms reported by a woman versus a man, for example, could also have different implications. We propose a novel population-aware domain adaptation approach by formulating the domain adaptation task as a multi-source hierarchical Bayesian framework. The model improves prediction in the case of largely unlabelled target data by harnessing both domain and population invariant information.