 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Misreporting in the Presence of Genuine Modification: A Causal Perspective
May 29, 2025

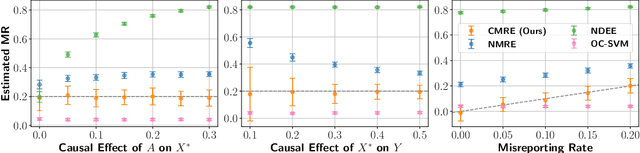
In settings where ML models are used to inform the allocation of resources, agents affected by the allocation decisions might have an incentive to strategically change their features to secure better outcomes. While prior work has studied strategic responses broadly, disentangling misreporting from genuine modification remains a fundamental challenge. In this paper, we propose a causally-motivated approach to identify and quantify how much an agent misreports on average by distinguishing deceptive changes in their features from genuine modification. Our key insight is that, unlike genuine modification, misreported features do not causally affect downstream variables (i.e., causal descendants). We exploit this asymmetry by comparing the causal effect of misreported features on their causal descendants as derived from manipulated datasets against those from unmanipulated datasets. We formally prove identifiability of the misreporting rate and characterize the variance of our estimator. We empirically validate our theoretical results using a semi-synthetic and real Medicare dataset with misreported data, demonstrating that our approach can be employed to identify misreporting in real-world scenarios.
A Course Correction in Steerability Evaluation: Revealing Miscalibration and Side Effects in LLMs
May 27, 2025


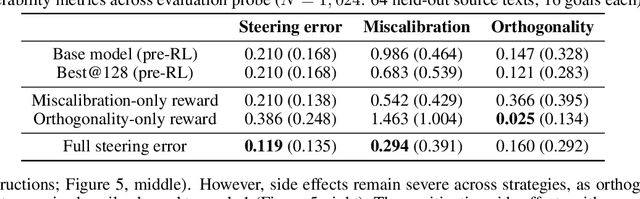
Despite advances in large language models (LLMs) on reasoning and instruction-following benchmarks, it remains unclear whether they can reliably produce outputs aligned with a broad variety of user goals, a concept we refer to as steerability. The abundance of methods proposed to modify LLM behavior makes it unclear whether current LLMs are already steerable, or require further intervention. In particular, LLMs may exhibit (i) poor coverage, where rare user goals are underrepresented; (ii) miscalibration, where models overshoot requests; and (iii) side effects, where changes to one dimension of text inadvertently affect others. To systematically evaluate these failures, we introduce a framework based on a multi-dimensional goal space that models user goals and LLM outputs as vectors with dimensions corresponding to text attributes (e.g., reading difficulty). Applied to a text-rewriting task, we find that current LLMs struggle with steerability, as side effects are persistent. Interventions to improve steerability, such as prompt engineering, best-of-$N$ sampling, and reinforcement learning fine-tuning, have varying effectiveness, yet side effects remain problematic. Our findings suggest that even strong LLMs struggle with steerability, and existing alignment strategies may be insufficient. We open-source our steerability evaluation framework at https://github.com/MLD3/steerability.
Conditional Front-door Adjustment for Heterogeneous Treatment Assignment Effect Estimation Under Non-adherence
May 08, 2025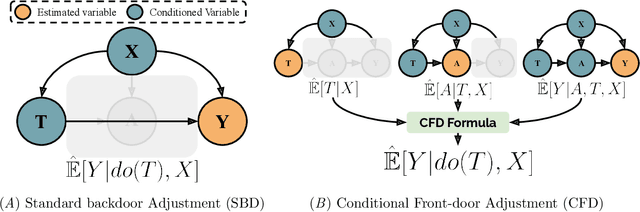
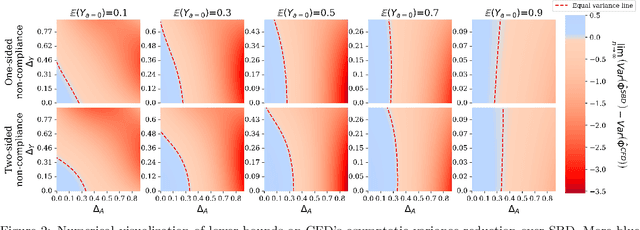
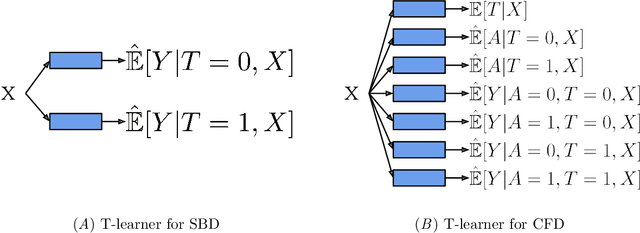
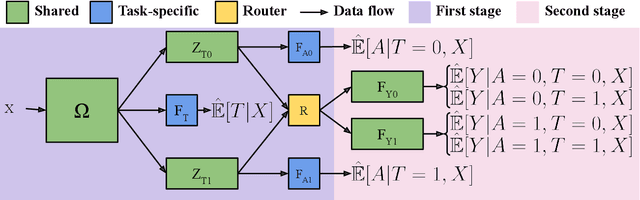
Estimates of heterogeneous treatment assignment effects can inform treatment decisions. Under the presence of non-adherence (e.g., patients do not adhere to their assigned treatment), both the standard backdoor adjustment (SBD) and the conditional front-door adjustment (CFD) can recover unbiased estimates of the treatment assignment effects. However, the estimation variance of these approaches may vary widely across settings, which remains underexplored in the literature. In this work, we demonstrate theoretically and empirically that CFD yields lower-variance estimates than SBD when the true effect of treatment assignment is small (i.e., assigning an intervention leads to small changes in patients' future outcome). Additionally, since CFD requires estimating multiple nuisance parameters, we introduce LobsterNet, a multi-task neural network that implements CFD with joint modeling of the nuisance parameters. Empirically, LobsterNet reduces estimation error across several semi-synthetic and real-world datasets compared to baselines. Our findings suggest CFD with shared nuisance parameter modeling can improve treatment assignment effect estimation under non-adherence.
Evaluation Framework for AI Systems in "the Wild"
Apr 23, 2025Generative AI (GenAI) models have become vital across industries, yet current evaluation methods have not adapted to their widespread use. Traditional evaluations often rely on benchmarks and fixed datasets, frequently failing to reflect real-world performance, which creates a gap between lab-tested outcomes and practical applications. This white paper proposes a comprehensive framework for how we should evaluate real-world GenAI systems, emphasizing diverse, evolving inputs and holistic, dynamic, and ongoing assessment approaches. The paper offers guidance for practitioners on how to design evaluation methods that accurately reflect real-time capabilities, and provides policymakers with recommendations for crafting GenAI policies focused on societal impacts, rather than fixed performance numbers or parameter sizes. We advocate for holistic frameworks that integrate performance, fairness, and ethics and the use of continuous, outcome-oriented methods that combine human and automated assessments while also being transparent to foster trust among stakeholders. Implementing these strategies ensures GenAI models are not only technically proficient but also ethically responsible and impactful.
Machine Learning for Health symposium 2024 -- Findings track
Mar 02, 2025A collection of the accepted Findings papers that were presented at the 4th Machine Learning for Health symposium (ML4H 2024), which was held on December 15-16, 2024, in Vancouver, BC, Canada. ML4H 2024 invited high-quality submissions describing innovative research in a variety of health-related disciplines including healthcare, biomedicine, and public health. Works could be submitted to either the archival Proceedings track, or the non-archival Findings track. The Proceedings track targeted mature, cohesive works with technical sophistication and high-impact relevance to health. The Findings track promoted works that would spark new insights, collaborations, and discussions at ML4H. Both tracks were given the opportunity to share their work through the in-person poster session. All the manuscripts submitted to ML4H Symposium underwent a double-blind peer-review process.
Who's Gaming the System? A Causally-Motivated Approach for Detecting Strategic Adaptation
Dec 02, 2024



In many settings, machine learning models may be used to inform decisions that impact individuals or entities who interact with the model. Such entities, or agents, may game model decisions by manipulating their inputs to the model to obtain better outcomes and maximize some utility. We consider a multi-agent setting where the goal is to identify the "worst offenders:" agents that are gaming most aggressively. However, identifying such agents is difficult without knowledge of their utility function. Thus, we introduce a framework in which each agent's tendency to game is parameterized via a scalar. We show that this gaming parameter is only partially identifiable. By recasting the problem as a causal effect estimation problem where different agents represent different "treatments," we prove that a ranking of all agents by their gaming parameters is identifiable. We present empirical results in a synthetic data study validating the usage of causal effect estimation for gaming detection and show in a case study of diagnosis coding behavior in the U.S. that our approach highlights features associated with gaming.
From Biased Selective Labels to Pseudo-Labels: An Expectation-Maximization Framework for Learning from Biased Decisions
Jun 27, 2024Selective labels occur when label observations are subject to a decision-making process; e.g., diagnoses that depend on the administration of laboratory tests. We study a clinically-inspired selective label problem called disparate censorship, where labeling biases vary across subgroups and unlabeled individuals are imputed as "negative" (i.e., no diagnostic test = no illness). Machine learning models naively trained on such labels could amplify labeling bias. Inspired by causal models of selective labels, we propose Disparate Censorship Expectation-Maximization (DCEM), an algorithm for learning in the presence of disparate censorship. We theoretically analyze how DCEM mitigates the effects of disparate censorship on model performance. We validate DCEM on synthetic data, showing that it improves bias mitigation (area between ROC curves) without sacrificing discriminative performance (AUC) compared to baselines. We achieve similar results in a sepsis classification task using clinical data.
Disparate Censorship & Undertesting: A Source of Label Bias in Clinical Machine Learning
Aug 01, 2022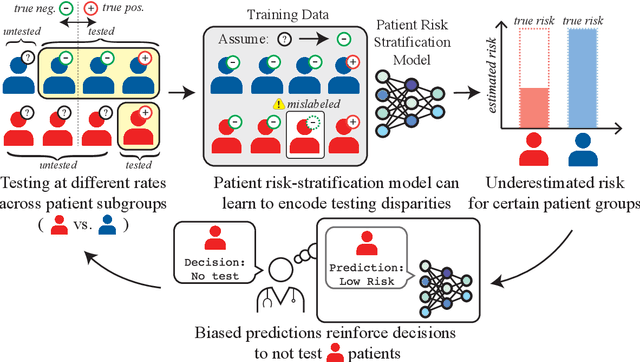
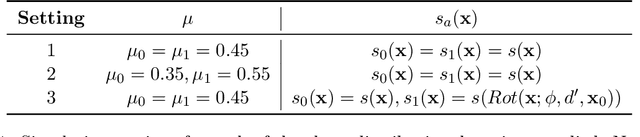
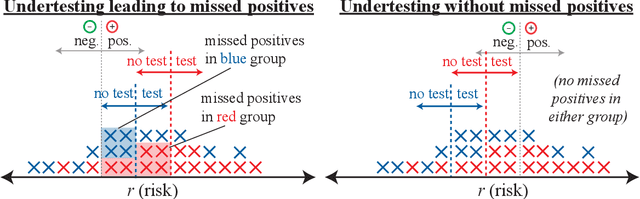
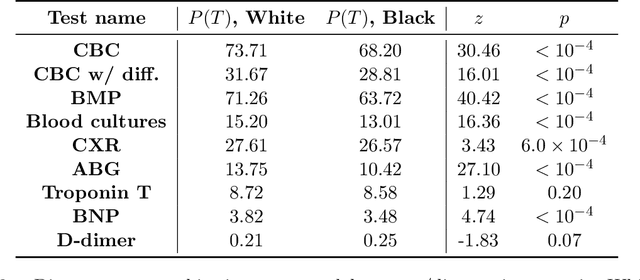
As machine learning (ML) models gain traction in clinical applications, understanding the impact of clinician and societal biases on ML models is increasingly important. While biases can arise in the labels used for model training, the many sources from which these biases arise are not yet well-studied. In this paper, we highlight disparate censorship (i.e., differences in testing rates across patient groups) as a source of label bias that clinical ML models may amplify, potentially causing harm. Many patient risk-stratification models are trained using the results of clinician-ordered diagnostic and laboratory tests of labels. Patients without test results are often assigned a negative label, which assumes that untested patients do not experience the outcome. Since orders are affected by clinical and resource considerations, testing may not be uniform in patient populations, giving rise to disparate censorship. Disparate censorship in patients of equivalent risk leads to undertesting in certain groups, and in turn, more biased labels for such groups. Using such biased labels in standard ML pipelines could contribute to gaps in model performance across patient groups. Here, we theoretically and empirically characterize conditions in which disparate censorship or undertesting affect model performance across subgroups. Our findings call attention to disparate censorship as a source of label bias in clinical ML models.
Lost in Transmission: On the Impact of Networking Corruptions on Video Machine Learning Models
Jun 10, 2022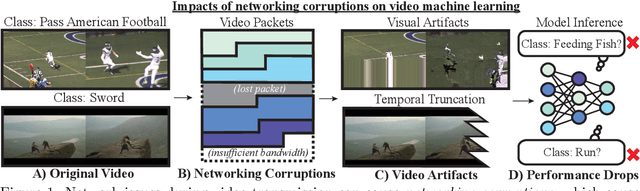



We study how networking corruptions--data corruptions caused by networking errors--affect video machine learning (ML) models. We discover apparent networking corruptions in Kinetics-400, a benchmark video ML dataset. In a simulation study, we investigate (1) what artifacts networking corruptions cause, (2) how such artifacts affect ML models, and (3) whether standard robustness methods can mitigate their negative effects. We find that networking corruptions cause visual and temporal artifacts (i.e., smeared colors or frame drops). These networking corruptions degrade performance on a variety of video ML tasks, but effects vary by task and dataset, depending on how much temporal context the tasks require. Lastly, we evaluate data augmentation--a standard defense for data corruptions--but find that it does not recover performance.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.