 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Framework for AI Systems in "the Wild"
Apr 23, 2025Generative AI (GenAI) models have become vital across industries, yet current evaluation methods have not adapted to their widespread use. Traditional evaluations often rely on benchmarks and fixed datasets, frequently failing to reflect real-world performance, which creates a gap between lab-tested outcomes and practical applications. This white paper proposes a comprehensive framework for how we should evaluate real-world GenAI systems, emphasizing diverse, evolving inputs and holistic, dynamic, and ongoing assessment approaches. The paper offers guidance for practitioners on how to design evaluation methods that accurately reflect real-time capabilities, and provides policymakers with recommendations for crafting GenAI policies focused on societal impacts, rather than fixed performance numbers or parameter sizes. We advocate for holistic frameworks that integrate performance, fairness, and ethics and the use of continuous, outcome-oriented methods that combine human and automated assessments while also being transparent to foster trust among stakeholders. Implementing these strategies ensures GenAI models are not only technically proficient but also ethically responsible and impactful.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Towards the Science of Security and Privacy in Machine Learning
Nov 11, 2016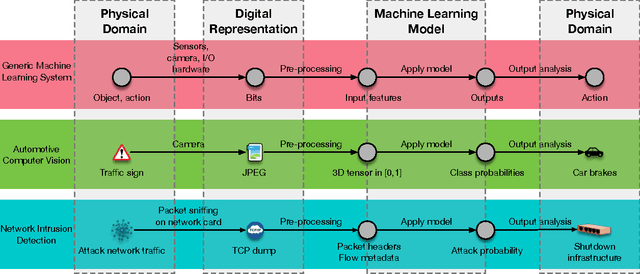
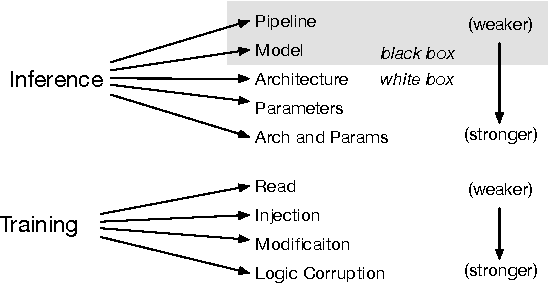

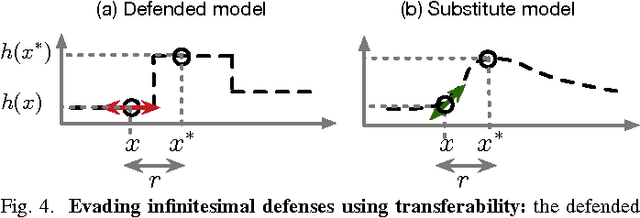
Advances in machine learning (ML) in recent years have enabled a dizzying array of applications such as data analytics, autonomous systems, and security diagnostics. ML is now pervasive---new systems and models are being deployed in every domain imaginable, leading to rapid and widespread deployment of software based inference and decision making. There is growing recognition that ML exposes new vulnerabilities in software systems, yet the technical community's understanding of the nature and extent of these vulnerabilities remains limited. We systematize recent findings on ML security and privacy, focusing on attacks identified on these systems and defenses crafted to date. We articulate a comprehensive threat model for ML, and categorize attacks and defenses within an adversarial framework. Key insights resulting from works both in the ML and security communities are identified and the effectiveness of approaches are related to structural elements of ML algorithms and the data used to train them. We conclude by formally exploring the opposing relationship between model accuracy and resilience to adversarial manipulation. Through these explorations, we show that there are (possibly unavoidable) tensions between model complexity, accuracy, and resilience that must be calibrated for the environments in which they will be used.
Proceedings of the Eighth Conference on Uncertainty in Artificial Intelligence (1992)
Apr 13, 2013This is the Proceedings of the Eighth Conference on Uncertainty in Artificial Intelligence, which was held in Stanford, CA, July 17-19, 1992