 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Limits of Selective AI Prediction: A Case Study in Clinical Decision Making
Aug 11, 2025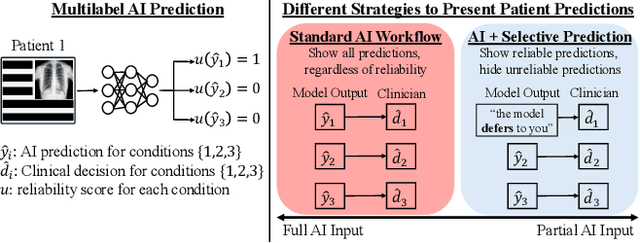
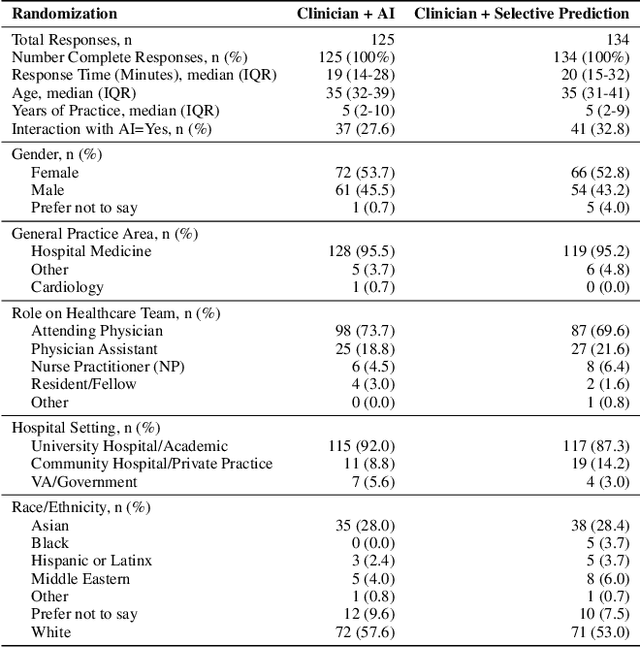
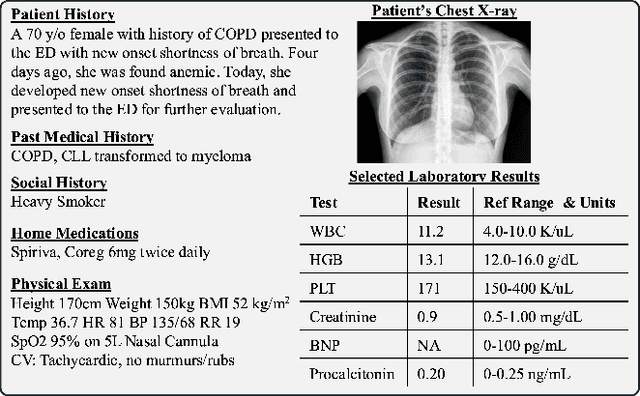
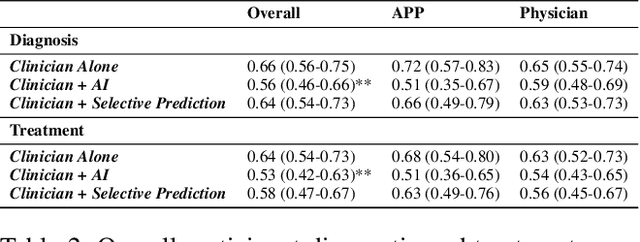
AI has the potential to augment human decision making. However, even high-performing models can produce inaccurate predictions when deployed. These inaccuracies, combined with automation bias, where humans overrely on AI predictions, can result in worse decisions. Selective prediction, in which potentially unreliable model predictions are hidden from users, has been proposed as a solution. This approach assumes that when AI abstains and informs the user so, humans make decisions as they would without AI involvement. To test this assumption, we study the effects of selective prediction on human decisions in a clinical context. We conducted a user study of 259 clinicians tasked with diagnosing and treating hospitalized patients. We compared their baseline performance without any AI involvement to their AI-assisted accuracy with and without selective prediction. Our findings indicate that selective prediction mitigates the negative effects of inaccurate AI in terms of decision accuracy. Compared to no AI assistance, clinician accuracy declined when shown inaccurate AI predictions (66% [95% CI: 56%-75%] vs. 56% [95% CI: 46%-66%]), but recovered under selective prediction (64% [95% CI: 54%-73%]). However, while selective prediction nearly maintains overall accuracy, our results suggest that it alters patterns of mistakes: when informed the AI abstains, clinicians underdiagnose (18% increase in missed diagnoses) and undertreat (35% increase in missed treatments) compared to no AI input at all. Our findings underscore the importance of empirically validating assumptions about how humans engage with AI within human-AI systems.
Evaluation Framework for AI Systems in "the Wild"
Apr 23, 2025Generative AI (GenAI) models have become vital across industries, yet current evaluation methods have not adapted to their widespread use. Traditional evaluations often rely on benchmarks and fixed datasets, frequently failing to reflect real-world performance, which creates a gap between lab-tested outcomes and practical applications. This white paper proposes a comprehensive framework for how we should evaluate real-world GenAI systems, emphasizing diverse, evolving inputs and holistic, dynamic, and ongoing assessment approaches. The paper offers guidance for practitioners on how to design evaluation methods that accurately reflect real-time capabilities, and provides policymakers with recommendations for crafting GenAI policies focused on societal impacts, rather than fixed performance numbers or parameter sizes. We advocate for holistic frameworks that integrate performance, fairness, and ethics and the use of continuous, outcome-oriented methods that combine human and automated assessments while also being transparent to foster trust among stakeholders. Implementing these strategies ensures GenAI models are not only technically proficient but also ethically responsible and impactful.
DEPICT: Diffusion-Enabled Permutation Importance for Image Classification Tasks
Jul 19, 2024



We propose a permutation-based explanation method for image classifiers. Current image-model explanations like activation maps are limited to instance-based explanations in the pixel space, making it difficult to understand global model behavior. In contrast, permutation based explanations for tabular data classifiers measure feature importance by comparing model performance on data before and after permuting a feature. We propose an explanation method for image-based models that permutes interpretable concepts across dataset images. Given a dataset of images labeled with specific concepts like captions, we permute a concept across examples in the text space and then generate images via a text-conditioned diffusion model. Feature importance is then reflected by the change in model performance relative to unpermuted data. When applied to a set of concepts, the method generates a ranking of feature importance. We show this approach recovers underlying model feature importance on synthetic and real-world image classification tasks.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
Combining chest X-rays and EHR data using machine learning to diagnose acute respiratory failure
Aug 27, 2021
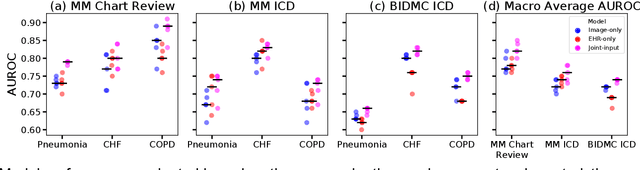
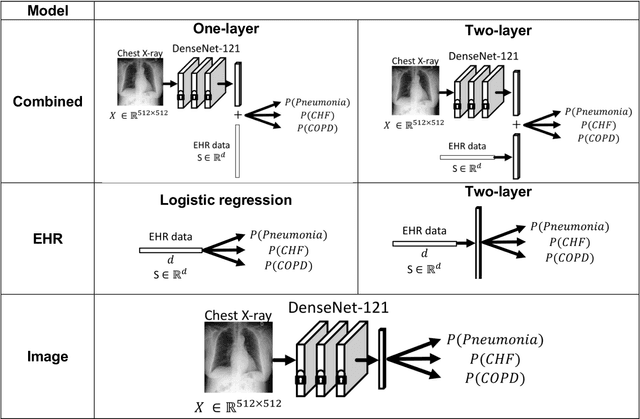

When patients develop acute respiratory failure, accurately identifying the underlying etiology is essential for determining the best treatment, but it can be challenging to differentiate between common diagnoses in clinical practice. Machine learning models could improve medical diagnosis by augmenting clinical decision making and play a role in the diagnostic evaluation of patients with acute respiratory failure. While machine learning models have been developed to identify common findings on chest radiographs (e.g. pneumonia), augmenting these approaches by also analyzing clinically relevant data from the electronic health record (EHR) could aid in the diagnosis of acute respiratory failure. Machine learning models were trained to predict the cause of acute respiratory failure (pneumonia, heart failure, and/or COPD) using chest radiographs and EHR data from patients within an internal cohort using diagnoses based on physician chart review. Models were also tested on patients in an external cohort using discharge diagnosis codes. A model combining chest radiographs and EHR data outperformed models based on each modality alone for pneumonia and COPD. For pneumonia, the combined model AUROC was 0.79 (0.78-0.79), image model AUROC was 0.73 (0.72-0.75), and EHR model AUROC was 0.73 (0.70-0.76); for COPD, combined: 0.89 (0.83-0.91), image: 0.85 (0.77-0.89), and EHR: 0.80 (0.76-0.84); for heart failure, combined: 0.80 (0.77-0.84), image: 0.77 (0.71-0.81), and EHR: 0.80 (0.75-0.82). In the external cohort, performance was consistent for heart failure and COPD, but declined slightly for pneumonia. Overall, machine learning models combing chest radiographs and EHR data can accurately differentiate between common causes of acute respiratory failure. Further work is needed to determine whether these models could aid clinicians in the diagnosis of acute respiratory failure in clinical settings.
Deep Learning Applied to Chest X-Rays: Exploiting and Preventing Shortcuts
Sep 21, 2020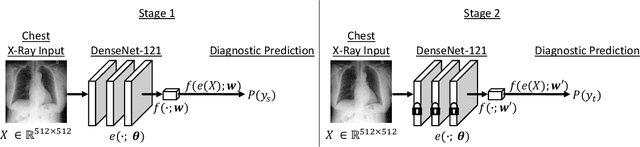
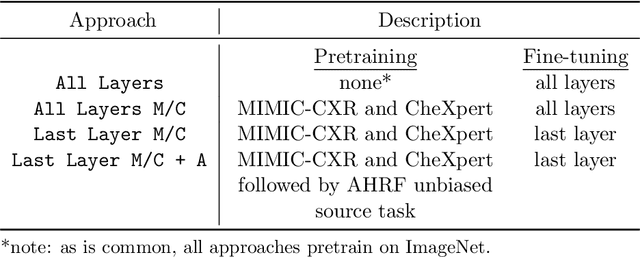
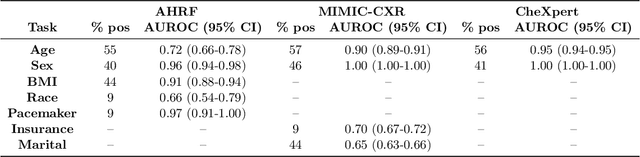
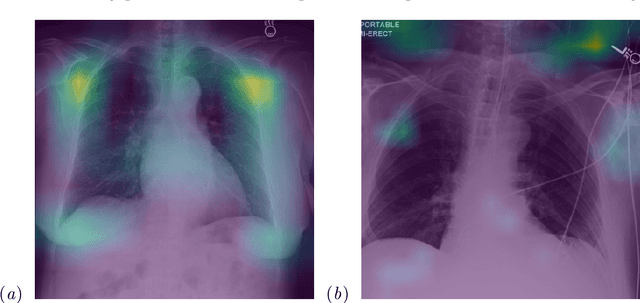
While deep learning has shown promise in improving the automated diagnosis of disease based on chest X-rays, deep networks may exhibit undesirable behavior related to shortcuts. This paper studies the case of spurious class skew in which patients with a particular attribute are spuriously more likely to have the outcome of interest. For instance, clinical protocols might lead to a dataset in which patients with pacemakers are disproportionately likely to have congestive heart failure. This skew can lead to models that take shortcuts by heavily relying on the biased attribute. We explore this problem across a number of attributes in the context of diagnosing the cause of acute hypoxemic respiratory failure. Applied to chest X-rays, we show that i) deep nets can accurately identify many patient attributes including sex (AUROC = 0.96) and age (AUROC >= 0.90), ii) they tend to exploit correlations between such attributes and the outcome label when learning to predict a diagnosis, leading to poor performance when such correlations do not hold in the test population (e.g., everyone in the test set is male), and iii) a simple transfer learning approach is surprisingly effective at preventing the shortcut and promoting good generalization performance. On the task of diagnosing congestive heart failure based on a set of chest X-rays skewed towards older patients (age >= 63), the proposed approach improves generalization over standard training from 0.66 (95% CI: 0.54-0.77) to 0.84 (95% CI: 0.73-0.92) AUROC. While simple, the proposed approach has the potential to improve the performance of models across populations by encouraging reliance on clinically relevant manifestations of disease, i.e., those that a clinician would use to make a diagnosis.