 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
May 04, 2026Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
Learning Representations from Incomplete EHR Data with Dual-Masked Autoencoding
Feb 16, 2026Learning from electronic health records (EHRs) time series is challenging due to irregular sam- pling, heterogeneous missingness, and the resulting sparsity of observations. Prior self-supervised meth- ods either impute before learning, represent missingness through a dedicated input signal, or optimize solely for imputation, reducing their capacity to efficiently learn representations that support clinical downstream tasks. We propose the Augmented-Intrinsic Dual-Masked Autoencoder (AID-MAE), which learns directly from incomplete time series by applying an intrinsic missing mask to represent naturally missing values and an augmented mask that hides a subset of observed values for reconstruction during training. AID-MAE processes only the unmasked subset of tokens and consistently outperforms strong baselines, including XGBoost and DuETT, across multiple clinical tasks on two datasets. In addition, the learned embeddings naturally stratify patient cohorts in the representation space.
Robustness Beyond Known Groups with Low-rank Adaptation
Feb 09, 2026Deep learning models trained to optimize average accuracy often exhibit systematic failures on particular subpopulations. In real world settings, the subpopulations most affected by such disparities are frequently unlabeled or unknown, thereby motivating the development of methods that are performant on sensitive subgroups without being pre-specified. However, existing group-robust methods typically assume prior knowledge of relevant subgroups, using group annotations for training or model selection. We propose Low-rank Error Informed Adaptation (LEIA), a simple two-stage method that improves group robustness by identifying a low-dimensional subspace in the representation space where model errors concentrate. LEIA restricts adaptation to this error-informed subspace via a low-rank adjustment to the classifier logits, directly targeting latent failure modes without modifying the backbone or requiring group labels. Using five real-world datasets, we analyze group robustness under three settings: (1) truly no knowledge of subgroup relevance, (2) partial knowledge of subgroup relevance, and (3) full knowledge of subgroup relevance. Across all settings, LEIA consistently improves worst-group performance while remaining fast, parameter-efficient, and robust to hyperparameter choice.
Tiered Agentic Oversight: A Hierarchical Multi-Agent System for AI Safety in Healthcare
Jun 14, 2025Current large language models (LLMs), despite their power, can introduce safety risks in clinical settings due to limitations such as poor error detection and single point of failure. To address this, we propose Tiered Agentic Oversight (TAO), a hierarchical multi-agent framework that enhances AI safety through layered, automated supervision. Inspired by clinical hierarchies (e.g., nurse, physician, specialist), TAO conducts agent routing based on task complexity and agent roles. Leveraging automated inter- and intra-tier collaboration and role-playing, TAO creates a robust safety framework. Ablation studies reveal that TAO's superior performance is driven by its adaptive tiered architecture, which improves safety by over 3.2% compared to static single-tier configurations; the critical role of its lower tiers, particularly tier 1, whose removal most significantly impacts safety; and the strategic assignment of more advanced LLM to these initial tiers, which boosts performance by over 2% compared to less optimal allocations while achieving near-peak safety efficiently. These mechanisms enable TAO to outperform single-agent and multi-agent frameworks in 4 out of 5 healthcare safety benchmarks, showing up to an 8.2% improvement over the next-best methods in these evaluations. Finally, we validate TAO via an auxiliary clinician-in-the-loop study where integrating expert feedback improved TAO's accuracy in medical triage from 40% to 60%.
MedPAIR: Measuring Physicians and AI Relevance Alignment in Medical Question Answering
May 29, 2025Large Language Models (LLMs) have demonstrated remarkable performance on various medical question-answering (QA) benchmarks, including standardized medical exams. However, correct answers alone do not ensure correct logic, and models may reach accurate conclusions through flawed processes. In this study, we introduce the MedPAIR (Medical Dataset Comparing Physicians and AI Relevance Estimation and Question Answering) dataset to evaluate how physician trainees and LLMs prioritize relevant information when answering QA questions. We obtain annotations on 1,300 QA pairs from 36 physician trainees, labeling each sentence within the question components for relevance. We compare these relevance estimates to those for LLMs, and further evaluate the impact of these "relevant" subsets on downstream task performance for both physician trainees and LLMs. We find that LLMs are frequently not aligned with the content relevance estimates of physician trainees. After filtering out physician trainee-labeled irrelevant sentences, accuracy improves for both the trainees and the LLMs. All LLM and physician trainee-labeled data are available at: http://medpair.csail.mit.edu/.
BehaviorSFT: Behavioral Token Conditioning for Clinical Agents Across the Proactivity Spectrum
May 27, 2025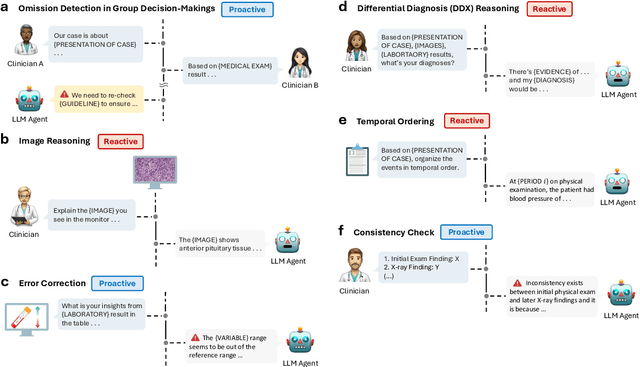
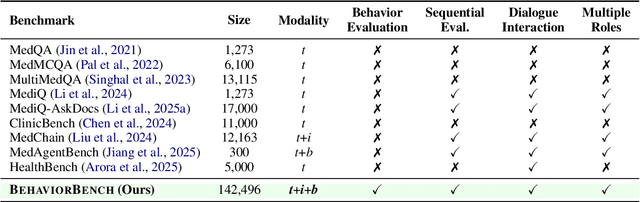
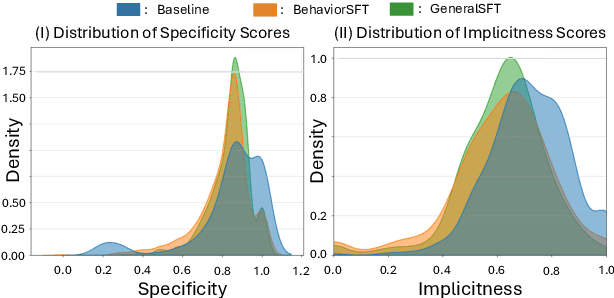
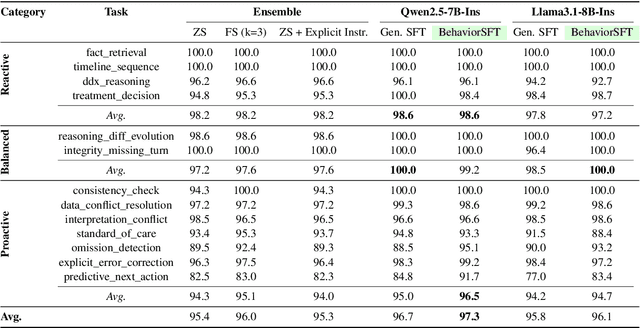
Large Language Models (LLMs) as clinical agents require careful behavioral adaptation. While adept at reactive tasks (e.g., diagnosis reasoning), LLMs often struggle with proactive engagement, like unprompted identification of critical missing information or risks. We introduce BehaviorBench, a comprehensive dataset to evaluate agent behaviors across a clinical assistance spectrum, ranging from reactive query responses to proactive interventions (e.g., clarifying ambiguities, flagging overlooked critical data). Our BehaviorBench experiments reveal LLMs' inconsistent proactivity. To address this, we propose BehaviorSFT, a novel training strategy using behavioral tokens to explicitly condition LLMs for dynamic behavioral selection along this spectrum. BehaviorSFT boosts performance, achieving up to 97.3% overall Macro F1 on BehaviorBench and improving proactive task scores (e.g., from 95.0% to 96.5% for Qwen2.5-7B-Ins). Crucially, blind clinician evaluations confirmed BehaviorSFT-trained agents exhibit more realistic clinical behavior, striking a superior balance between helpful proactivity (e.g., timely, relevant suggestions) and necessary restraint (e.g., avoiding over-intervention) versus standard fine-tuning or explicit instructed agents.
RelCon: Relative Contrastive Learning for a Motion Foundation Model for Wearable Data
Nov 27, 2024



We present RelCon, a novel self-supervised \textit{Rel}ative \textit{Con}trastive learning approach that uses a learnable distance measure in combination with a softened contrastive loss for training an motion foundation model from wearable sensors. The learnable distance measure captures motif similarity and domain-specific semantic information such as rotation invariance. The learned distance provides a measurement of semantic similarity between a pair of accelerometer time-series segments, which is used to measure the distance between an anchor and various other sampled candidate segments. The self-supervised model is trained on 1 billion segments from 87,376 participants from a large wearables dataset. The model achieves strong performance across multiple downstream tasks, encompassing both classification and regression. To our knowledge, we are the first to show the generalizability of a self-supervised learning model with motion data from wearables across distinct evaluation tasks.
Identifying Differential Patient Care Through Inverse Intent Inference
Nov 11, 2024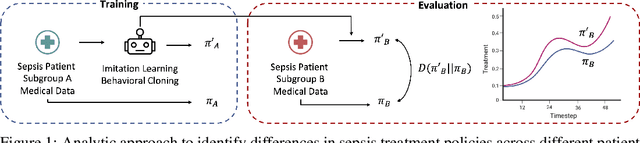


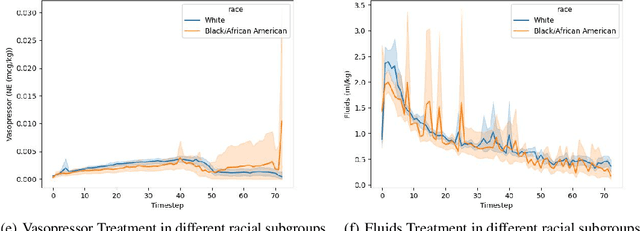
Sepsis is a life-threatening condition defined by end-organ dysfunction due to a dysregulated host response to infection. Although the Surviving Sepsis Campaign has launched and has been releasing sepsis treatment guidelines to unify and normalize the care for sepsis patients, it has been reported in numerous studies that disparities in care exist across the trajectory of patient stay in the emergency department and intensive care unit. Here, we apply a number of reinforcement learning techniques including behavioral cloning, imitation learning, and inverse reinforcement learning, to learn the optimal policy in the management of septic patient subgroups using expert demonstrations. Then we estimate the counterfactual optimal policies by applying the model to another subset of unseen medical populations and identify the difference in cure by comparing it to the real policy. Our data comes from the sepsis cohort of MIMIC-IV and the clinical data warehouses of the Mass General Brigham healthcare system. The ultimate objective of this work is to use the optimal learned policy function to estimate the counterfactual treatment policy and identify deviations across sub-populations of interest. We hope this approach would help us identify any disparities in care and also changes in cure in response to the publication of national sepsis treatment guidelines.
A Demonstration of Adaptive Collaboration of Large Language Models for Medical Decision-Making
Oct 31, 2024



Medical Decision-Making (MDM) is a multi-faceted process that requires clinicians to assess complex multi-modal patient data patient, often collaboratively. Large Language Models (LLMs) promise to streamline this process by synthesizing vast medical knowledge and multi-modal health data. However, single-agent are often ill-suited for nuanced medical contexts requiring adaptable, collaborative problem-solving. Our MDAgents addresses this need by dynamically assigning collaboration structures to LLMs based on task complexity, mimicking real-world clinical collaboration and decision-making. This framework improves diagnostic accuracy and supports adaptive responses in complex, real-world medical scenarios, making it a valuable tool for clinicians in various healthcare settings, and at the same time, being more efficient in terms of computing cost than static multi-agent decision making methods.
MEDS-Tab: Automated tabularization and baseline methods for MEDS datasets
Oct 31, 2024



Effective, reliable, and scalable development of machine learning (ML) solutions for structured electronic health record (EHR) data requires the ability to reliably generate high-quality baseline models for diverse supervised learning tasks in an efficient and performant manner. Historically, producing such baseline models has been a largely manual effort--individual researchers would need to decide on the particular featurization and tabularization processes to apply to their individual raw, longitudinal data; and then train a supervised model over those data to produce a baseline result to compare novel methods against, all for just one task and one dataset. In this work, powered by complementary advances in core data standardization through the MEDS framework, we dramatically simplify and accelerate this process of tabularizing irregularly sampled time-series data, providing researchers the ability to automatically and scalably featurize and tabularize their longitudinal EHR data across tens of thousands of individual features, hundreds of millions of clinical events, and diverse windowing horizons and aggregation strategies, all before ultimately leveraging these tabular data to automatically produce high-caliber XGBoost baselines in a highly computationally efficient manner. This system scales to dramatically larger datasets than tabularization tools currently available to the community and enables researchers with any MEDS format dataset to immediately begin producing reliable and performant baseline prediction results on various tasks, with minimal human effort required. This system will greatly enhance the reliability, reproducibility, and ease of development of powerful ML solutions for health problems across diverse datasets and clinical settings.