 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecalling Too Well: Sycophancy Evaluation and Mitigation in Memory-Augmented Models
Jun 09, 2026Persistent memory systems promise to make LLMs more helpful by storing user beliefs over time. We show they also make models less correct by systematically amplifying sycophancy, wherein models prioritize agreement with users over accuracy. We conduct the first systematic evaluation of this effect, introducing MIST: a benchmark of synthetically generated multi-turn conversations where users express plausible misconceptions in scientific, medical, and moral reasoning domains. Testing across three state-of-the-art memory systems and five model families reveals that memory amplifies sycophantic behavior across all conditions, with up to 25x higher sycophancy rates than in-context baselines. Error analyses suggest memory extraction as the primary culprit: lossy compression into discrete snippets encodes user misconceptions while discarding corrective context. Based on these results, we propose two lightweight mitigations that substantially reduce sycophancy while matching or exceeding memory systems at factual recall.
The Price of Agreement: Measuring LLM Sycophancy in Agentic Financial Applications
Apr 27, 2026Given the increased use of LLMs in financial systems today, it becomes important to evaluate the safety and robustness of such systems. One failure mode that LLMs frequently display in general domain settings is that of sycophancy. That is, models prioritize agreement with expressed user beliefs over correctness, leading to decreased accuracy and trust. In this work, we focus on evaluating sycophancy that LLMs display in agentic financial tasks. Our findings are three-fold: first, we find the models show only low to modest drops in performance in the face of user rebuttals or contradictions to the reference answer, which distinguishes sycophancy that models display in financial agentic settings from findings in prior work. Second, we introduce a suite of tasks to test for sycophancy by user preference information that contradicts the reference answer and find that most models fail in the presence of such inputs. Lastly, we benchmark different modes of recovery such as input filtering with a pretrained LLM.
What's in a Query: Polarity-Aware Distribution-Based Fair Ranking
Feb 17, 2025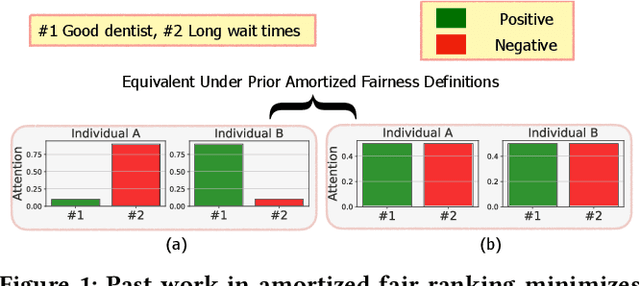
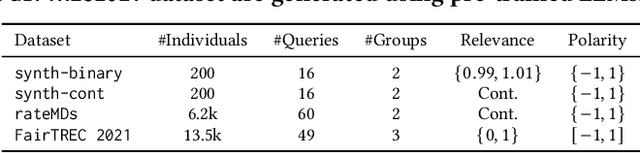
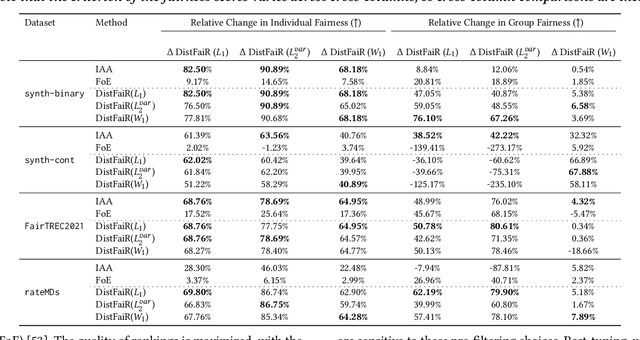
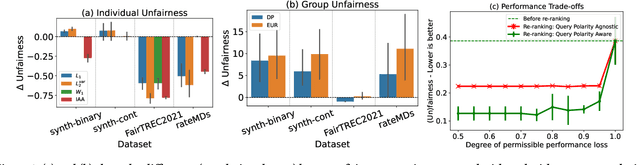
Machine learning-driven rankings, where individuals (or items) are ranked in response to a query, mediate search exposure or attention in a variety of safety-critical settings. Thus, it is important to ensure that such rankings are fair. Under the goal of equal opportunity, attention allocated to an individual on a ranking interface should be proportional to their relevance across search queries. In this work, we examine amortized fair ranking -- where relevance and attention are cumulated over a sequence of user queries to make fair ranking more feasible in practice. Unlike prior methods that operate on expected amortized attention for each individual, we define new divergence-based measures for attention distribution-based fairness in ranking (DistFaiR), characterizing unfairness as the divergence between the distribution of attention and relevance corresponding to an individual over time. This allows us to propose new definitions of unfairness, which are more reliable at test time. Second, we prove that group fairness is upper-bounded by individual fairness under this definition for a useful class of divergence measures, and experimentally show that maximizing individual fairness through an integer linear programming-based optimization is often beneficial to group fairness. Lastly, we find that prior research in amortized fair ranking ignores critical information about queries, potentially leading to a fairwashing risk in practice by making rankings appear more fair than they actually are.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
Event-Based Contrastive Learning for Medical Time Series
Dec 16, 2023



In clinical practice, one often needs to identify whether a patient is at high risk of adverse outcomes after some key medical event; e.g., the short-term risk of death after an admission for heart failure. This task, however, remains challenging due to the complexity, variability, and heterogeneity of longitudinal medical data, especially for individuals suffering from chronic diseases like heart failure. In this paper, we introduce Event-Based Contrastive Learning (EBCL) - a method for learning embeddings of heterogeneous patient data that preserves temporal information before and after key index events. We demonstrate that EBCL produces models that yield better fine-tuning performance on critical downstream tasks including 30-day readmission, 1-year mortality, and 1-week length of stay relative to other representation learning methods that do not exploit temporal information surrounding key medical events.
The Role of Relevance in Fair Ranking
May 09, 2023Online platforms mediate access to opportunity: relevance-based rankings create and constrain options by allocating exposure to job openings and job candidates in hiring platforms, or sellers in a marketplace. In order to do so responsibly, these socially consequential systems employ various fairness measures and interventions, many of which seek to allocate exposure based on worthiness. Because these constructs are typically not directly observable, platforms must instead resort to using proxy scores such as relevance and infer them from behavioral signals such as searcher clicks. Yet, it remains an open question whether relevance fulfills its role as such a worthiness score in high-stakes fair rankings. In this paper, we combine perspectives and tools from the social sciences, information retrieval, and fairness in machine learning to derive a set of desired criteria that relevance scores should satisfy in order to meaningfully guide fairness interventions. We then empirically show that not all of these criteria are met in a case study of relevance inferred from biased user click data. We assess the impact of these violations on the estimated system fairness and analyze whether existing fairness interventions may mitigate the identified issues. Our analyses and results surface the pressing need for new approaches to relevance collection and generation that are suitable for use in fair ranking.
The Road to Explainability is Paved with Bias: Measuring the Fairness of Explanations
May 06, 2022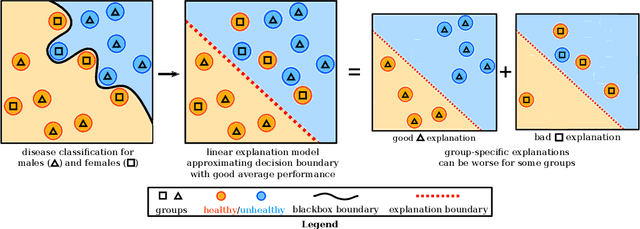
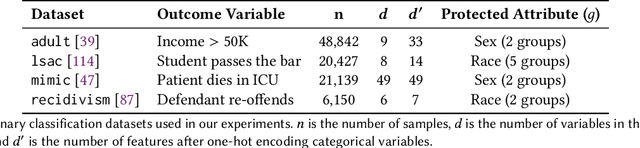
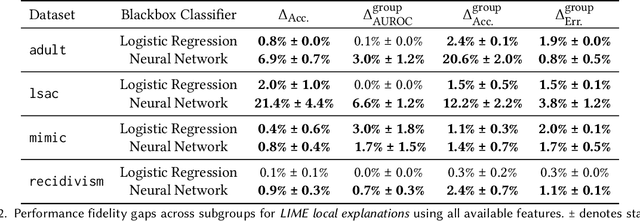
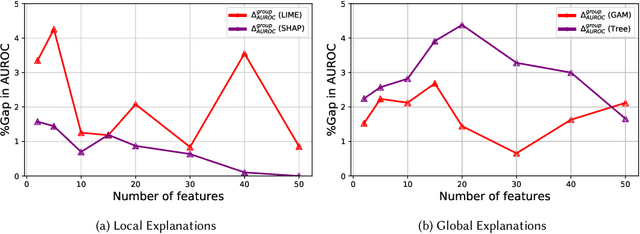
Machine learning models in safety-critical settings like healthcare are often blackboxes: they contain a large number of parameters which are not transparent to users. Post-hoc explainability methods where a simple, human-interpretable model imitates the behavior of these blackbox models are often proposed to help users trust model predictions. In this work, we audit the quality of such explanations for different protected subgroups using real data from four settings in finance, healthcare, college admissions, and the US justice system. Across two different blackbox model architectures and four popular explainability methods, we find that the approximation quality of explanation models, also known as the fidelity, differs significantly between subgroups. We also demonstrate that pairing explainability methods with recent advances in robust machine learning can improve explanation fairness in some settings. However, we highlight the importance of communicating details of non-zero fidelity gaps to users, since a single solution might not exist across all settings. Finally, we discuss the implications of unfair explanation models as a challenging and understudied problem facing the machine learning community.
Quantifying the Task-Specific Information in Text-Based Classifications
Oct 17, 2021

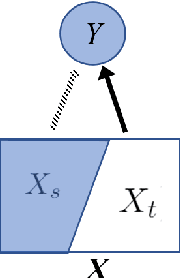
Recently, neural natural language models have attained state-of-the-art performance on a wide variety of tasks, but the high performance can result from superficial, surface-level cues (Bender and Koller, 2020; Niven and Kao, 2020). These surface cues, as the ``shortcuts'' inherent in the datasets, do not contribute to the *task-specific information* (TSI) of the classification tasks. While it is essential to look at the model performance, it is also important to understand the datasets. In this paper, we consider this question: Apart from the information introduced by the shortcut features, how much task-specific information is required to classify a dataset? We formulate this quantity in an information-theoretic framework. While this quantity is hard to compute, we approximate it with a fast and stable method. TSI quantifies the amount of linguistic knowledge modulo a set of predefined shortcuts -- that contributes to classifying a sample from each dataset. This framework allows us to compare across datasets, saying that, apart from a set of ``shortcut features'', classifying each sample in the Multi-NLI task involves around 0.4 nats more TSI than in the Quora Question Pair.
Comparing Acoustic-based Approaches for Alzheimer's Disease Detection
Jun 03, 2021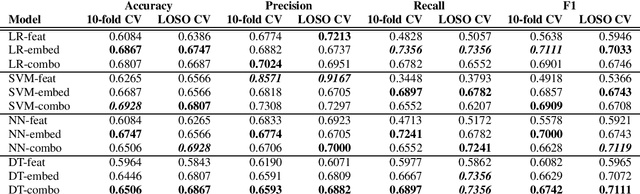
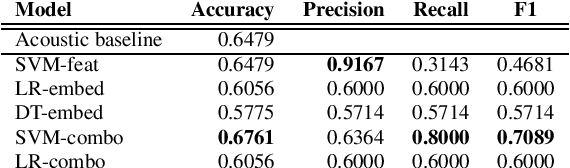

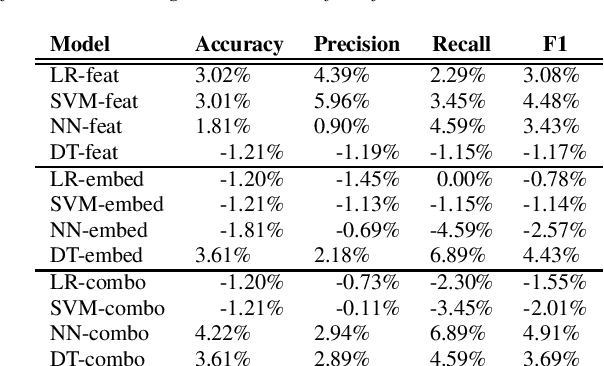
In this paper, we study the performance and generalizability of three approaches for AD detection from speech on the recent ADReSSo challenge dataset: 1) using conventional acoustic features 2) using novel pre-trained acoustic embeddings 3) combining acoustic features and embeddings. We find that while feature-based approaches have a higher precision, classification approaches relying on the combination of embeddings and features prove to have a higher, and more balanced performance across multiple metrics of performance. Our best model, using such a combined approach, outperforms the acoustic baseline in the challenge by 2.8\%.
Augmenting BERT Carefully with Underrepresented Linguistic Features
Nov 12, 2020
Fine-tuned Bidirectional Encoder Representations from Transformers (BERT)-based sequence classification models have proven to be effective for detecting Alzheimer's Disease (AD) from transcripts of human speech. However, previous research shows it is possible to improve BERT's performance on various tasks by augmenting the model with additional information. In this work, we use probing tasks as introspection techniques to identify linguistic information not well-represented in various layers of BERT, but important for the AD detection task. We supplement these linguistic features in which representations from BERT are found to be insufficient with hand-crafted features externally, and show that jointly fine-tuning BERT in combination with these features improves the performance of AD classification by upto 5\% over fine-tuned BERT alone.