 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Risk Minimization for High-Dimensional Treatments
May 26, 2026Predicting the effect of interventions with many possible variations, e.g., therapeutic content that affects mental health outcomes or an earnings call transcript that drives movement in share price, is useful across several domains. However, classical causal estimators tend to assume that all possible interventions are observed, which is infeasible when interventions vary widely, for instance, in the space of all text strings. We adapt a well-known approach of recasting causal inference as a learning problem, to address high-dimensional treatment spaces. Specifically, under standard assumptions like no unobserved confounding, we show that causal error decomposes into a series of moment-balancing errors of increasing order, and design objectives that directly improve causal estimation. We also show how to project the effect of a high-dimensional treatment onto lower-dimensional treatment attributes, which allows a single model to answer several causal questions without additional attribute-specific training. We empirically evaluate our estimators in settings with high-dimensional continuous, discrete, and text treatments, the last of which used a semi-synthetic dataset of Amazon Reviews. Our experiments demonstrate the benefit of higher-order balance error optimization and competitive performance of projected causal estimates with attribute-specific estimators.
Consistency in Language Models: Current Landscape, Challenges, and Future Directions
May 01, 2025The hallmark of effective language use lies in consistency -- expressing similar meanings in similar contexts and avoiding contradictions. While human communication naturally demonstrates this principle, state-of-the-art language models struggle to maintain reliable consistency across different scenarios. This paper examines the landscape of consistency research in AI language systems, exploring both formal consistency (including logical rule adherence) and informal consistency (such as moral and factual coherence). We analyze current approaches to measure aspects of consistency, identify critical research gaps in standardization of definitions, multilingual assessment, and methods to improve consistency. Our findings point to an urgent need for robust benchmarks to measure and interdisciplinary approaches to ensure consistency in the application of language models on domain-specific tasks while preserving the utility and adaptability.
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Zero-Shot Multi-Lingual Speaker Verification in Clinical Trials
Apr 05, 2024Due to the substantial number of clinicians, patients, and data collection environments involved in clinical trials, gathering data of superior quality poses a significant challenge. In clinical trials, patients are assessed based on their speech data to detect and monitor cognitive and mental health disorders. We propose using these speech recordings to verify the identities of enrolled patients and identify and exclude the individuals who try to enroll multiple times in the same trial. Since clinical studies are often conducted across different countries, creating a system that can perform speaker verification in diverse languages without additional development effort is imperative. We evaluate pre-trained TitaNet, ECAPA-TDNN, and SpeakerNet models by enrolling and testing with speech-impaired patients speaking English, German, Danish, Spanish, and Arabic languages. Our results demonstrate that tested models can effectively generalize to clinical speakers, with less than 2.7% EER for European Languages and 8.26% EER for Arabic. This represents a significant step in developing more versatile and efficient speaker verification systems for cognitive and mental health clinical trials that can be used across a wide range of languages and dialects, substantially reducing the effort required to develop speaker verification systems for multiple languages. We also evaluate how speech tasks and number of speakers involved in the trial influence the performance and show that the type of speech tasks impacts the model performance.
DEPAC: a Corpus for Depression and Anxiety Detection from Speech
Jun 20, 2023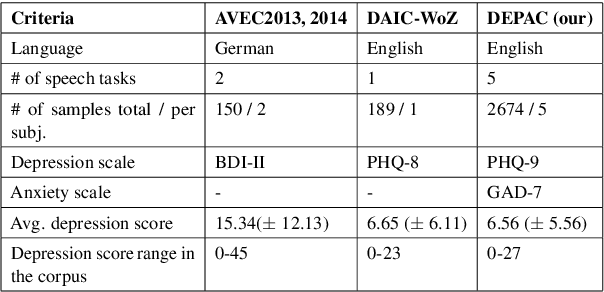

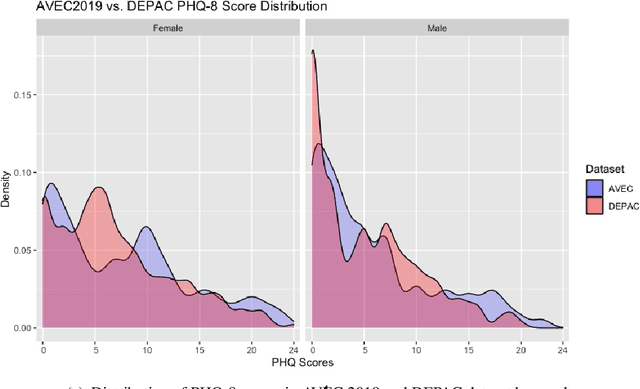
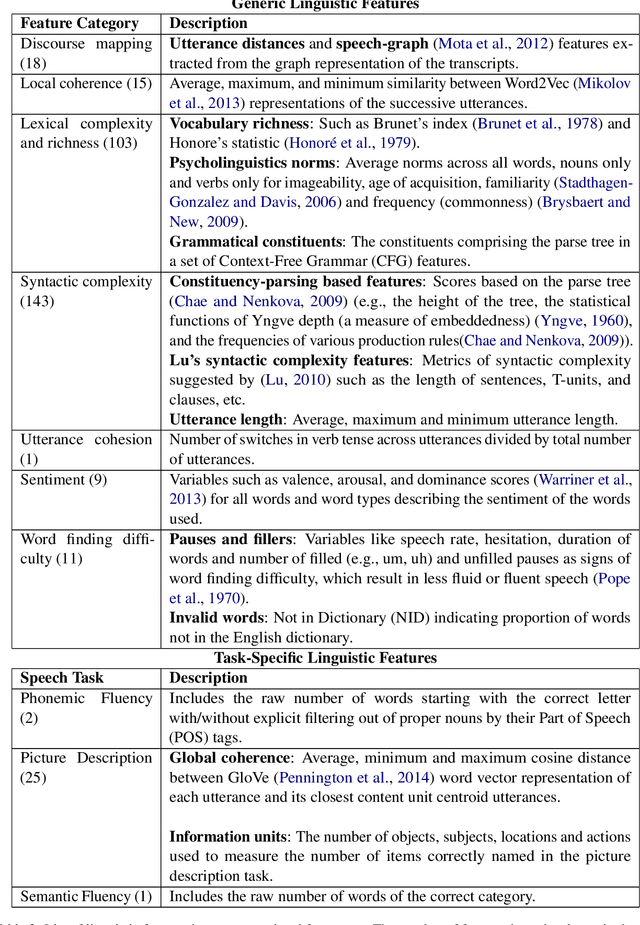
Mental distress like depression and anxiety contribute to the largest proportion of the global burden of diseases. Automated diagnosis systems of such disorders, empowered by recent innovations in Artificial Intelligence, can pave the way to reduce the sufferings of the affected individuals. Development of such systems requires information-rich and balanced corpora. In this work, we introduce a novel mental distress analysis audio dataset DEPAC, labeled based on established thresholds on depression and anxiety standard screening tools. This large dataset comprises multiple speech tasks per individual, as well as relevant demographic information. Alongside, we present a feature set consisting of hand-curated acoustic and linguistic features, which were found effective in identifying signs of mental illnesses in human speech. Finally, we justify the quality and effectiveness of our proposed audio corpus and feature set in predicting depression severity by comparing the performance of baseline machine learning models built on this dataset with baseline models trained on other well-known depression corpora.
Factors Affecting the Performance of Automated Speaker Verification in Alzheimer's Disease Clinical Trials
Jun 20, 2023

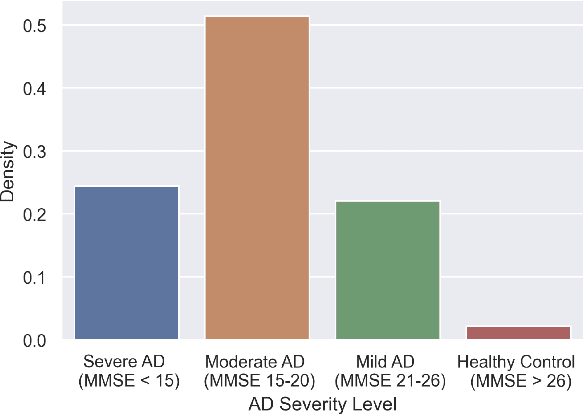

Detecting duplicate patient participation in clinical trials is a major challenge because repeated patients can undermine the credibility and accuracy of the trial's findings and result in significant health and financial risks. Developing accurate automated speaker verification (ASV) models is crucial to verify the identity of enrolled individuals and remove duplicates, but the size and quality of data influence ASV performance. However, there has been limited investigation into the factors that can affect ASV capabilities in clinical environments. In this paper, we bridge the gap by conducting analysis of how participant demographic characteristics, audio quality criteria, and severity level of Alzheimer's disease (AD) impact the performance of ASV utilizing a dataset of speech recordings from 659 participants with varying levels of AD, obtained through multiple speech tasks. Our results indicate that ASV performance: 1) is slightly better on male speakers than on female speakers; 2) degrades for individuals who are above 70 years old; 3) is comparatively better for non-native English speakers than for native English speakers; 4) is negatively affected by clinician interference, noisy background, and unclear participant speech; 5) tends to decrease with an increase in the severity level of AD. Our study finds that voice biometrics raise fairness concerns as certain subgroups exhibit different ASV performances owing to their inherent voice characteristics. Moreover, the performance of ASV is influenced by the quality of speech recordings, which underscores the importance of improving the data collection settings in clinical trials.
Cost-effective Models for Detecting Depression from Speech
Feb 18, 2023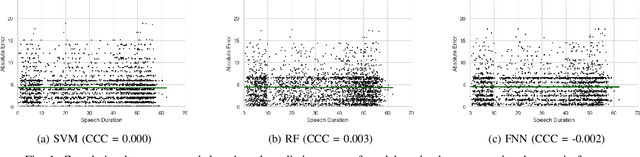
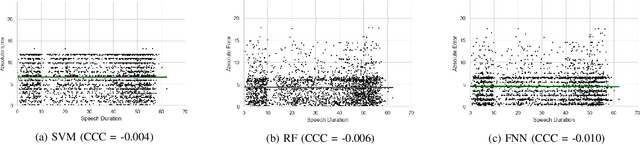
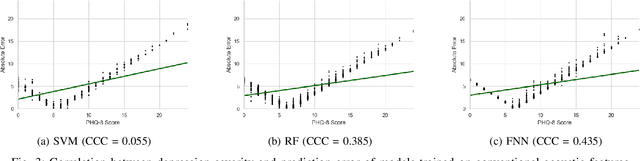
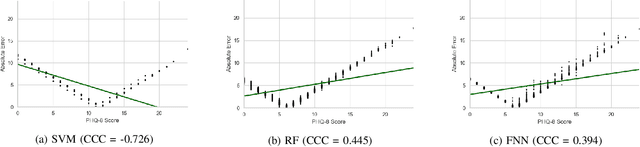
Depression is the most common psychological disorder and is considered as a leading cause of disability and suicide worldwide. An automated system capable of detecting signs of depression in human speech can contribute to ensuring timely and effective mental health care for individuals suffering from the disorder. Developing such automated system requires accurate machine learning models, capable of capturing signs of depression. However, state-of-the-art models based on deep acoustic representations require abundant data, meticulous selection of features, and rigorous training; the procedure involves enormous computational resources. In this work, we explore the effectiveness of two different acoustic feature groups - conventional hand-curated and deep representation features, for predicting the severity of depression from speech. We explore the relevance of possible contributing factors to the models' performance, including gender of the individual, severity of the disorder, content and length of speech. Our findings suggest that models trained on conventional acoustic features perform equally well or better than the ones trained on deep representation features at significantly lower computational cost, irrespective of other factors, e.g. content and length of speech, gender of the speaker and severity of the disorder. This makes such models a better fit for deployment where availability of computational resources is restricted, such as real time depression monitoring applications in smart devices.
Multi-modal deep learning system for depression and anxiety detection
Dec 30, 2022

Traditional screening practices for anxiety and depression pose an impediment to monitoring and treating these conditions effectively. However, recent advances in NLP and speech modelling allow textual, acoustic, and hand-crafted language-based features to jointly form the basis of future mental health screening and condition detection. Speech is a rich and readily available source of insight into an individual's cognitive state and by leveraging different aspects of speech, we can develop new digital biomarkers for depression and anxiety. To this end, we propose a multi-modal system for the screening of depression and anxiety from self-administered speech tasks. The proposed model integrates deep-learned features from audio and text, as well as hand-crafted features that are informed by clinically-validated domain knowledge. We find that augmenting hand-crafted features with deep-learned features improves our overall classification F1 score comparing to a baseline of hand-crafted features alone from 0.58 to 0.63 for depression and from 0.54 to 0.57 for anxiety. The findings of our work suggest that speech-based biomarkers for depression and anxiety hold significant promise in the future of digital health.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.