 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Multi-Lingual Speaker Verification in Clinical Trials
Apr 05, 2024Due to the substantial number of clinicians, patients, and data collection environments involved in clinical trials, gathering data of superior quality poses a significant challenge. In clinical trials, patients are assessed based on their speech data to detect and monitor cognitive and mental health disorders. We propose using these speech recordings to verify the identities of enrolled patients and identify and exclude the individuals who try to enroll multiple times in the same trial. Since clinical studies are often conducted across different countries, creating a system that can perform speaker verification in diverse languages without additional development effort is imperative. We evaluate pre-trained TitaNet, ECAPA-TDNN, and SpeakerNet models by enrolling and testing with speech-impaired patients speaking English, German, Danish, Spanish, and Arabic languages. Our results demonstrate that tested models can effectively generalize to clinical speakers, with less than 2.7% EER for European Languages and 8.26% EER for Arabic. This represents a significant step in developing more versatile and efficient speaker verification systems for cognitive and mental health clinical trials that can be used across a wide range of languages and dialects, substantially reducing the effort required to develop speaker verification systems for multiple languages. We also evaluate how speech tasks and number of speakers involved in the trial influence the performance and show that the type of speech tasks impacts the model performance.
Factors Affecting the Performance of Automated Speaker Verification in Alzheimer's Disease Clinical Trials
Jun 20, 2023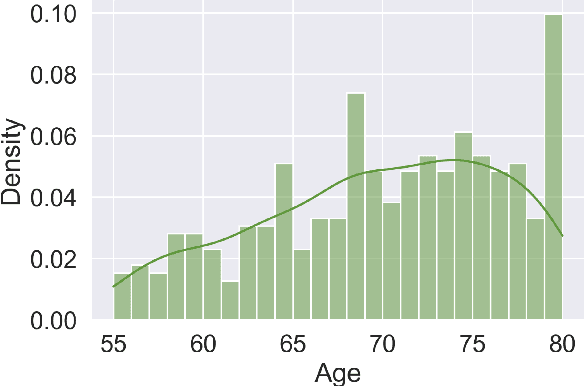

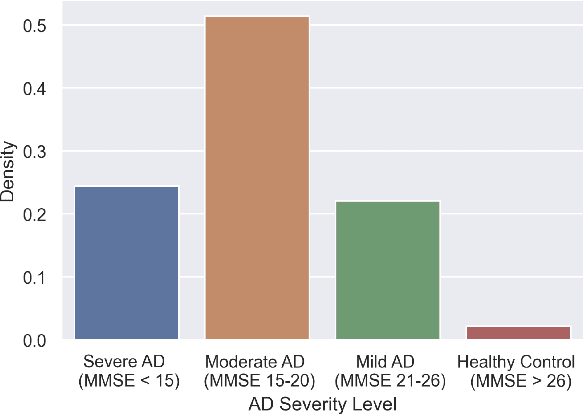

Detecting duplicate patient participation in clinical trials is a major challenge because repeated patients can undermine the credibility and accuracy of the trial's findings and result in significant health and financial risks. Developing accurate automated speaker verification (ASV) models is crucial to verify the identity of enrolled individuals and remove duplicates, but the size and quality of data influence ASV performance. However, there has been limited investigation into the factors that can affect ASV capabilities in clinical environments. In this paper, we bridge the gap by conducting analysis of how participant demographic characteristics, audio quality criteria, and severity level of Alzheimer's disease (AD) impact the performance of ASV utilizing a dataset of speech recordings from 659 participants with varying levels of AD, obtained through multiple speech tasks. Our results indicate that ASV performance: 1) is slightly better on male speakers than on female speakers; 2) degrades for individuals who are above 70 years old; 3) is comparatively better for non-native English speakers than for native English speakers; 4) is negatively affected by clinician interference, noisy background, and unclear participant speech; 5) tends to decrease with an increase in the severity level of AD. Our study finds that voice biometrics raise fairness concerns as certain subgroups exhibit different ASV performances owing to their inherent voice characteristics. Moreover, the performance of ASV is influenced by the quality of speech recordings, which underscores the importance of improving the data collection settings in clinical trials.