 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Multi-Lingual Speaker Verification in Clinical Trials
Apr 05, 2024Due to the substantial number of clinicians, patients, and data collection environments involved in clinical trials, gathering data of superior quality poses a significant challenge. In clinical trials, patients are assessed based on their speech data to detect and monitor cognitive and mental health disorders. We propose using these speech recordings to verify the identities of enrolled patients and identify and exclude the individuals who try to enroll multiple times in the same trial. Since clinical studies are often conducted across different countries, creating a system that can perform speaker verification in diverse languages without additional development effort is imperative. We evaluate pre-trained TitaNet, ECAPA-TDNN, and SpeakerNet models by enrolling and testing with speech-impaired patients speaking English, German, Danish, Spanish, and Arabic languages. Our results demonstrate that tested models can effectively generalize to clinical speakers, with less than 2.7% EER for European Languages and 8.26% EER for Arabic. This represents a significant step in developing more versatile and efficient speaker verification systems for cognitive and mental health clinical trials that can be used across a wide range of languages and dialects, substantially reducing the effort required to develop speaker verification systems for multiple languages. We also evaluate how speech tasks and number of speakers involved in the trial influence the performance and show that the type of speech tasks impacts the model performance.
Factors Affecting the Performance of Automated Speaker Verification in Alzheimer's Disease Clinical Trials
Jun 20, 2023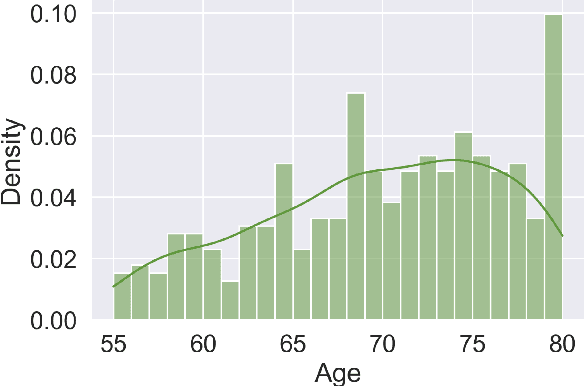

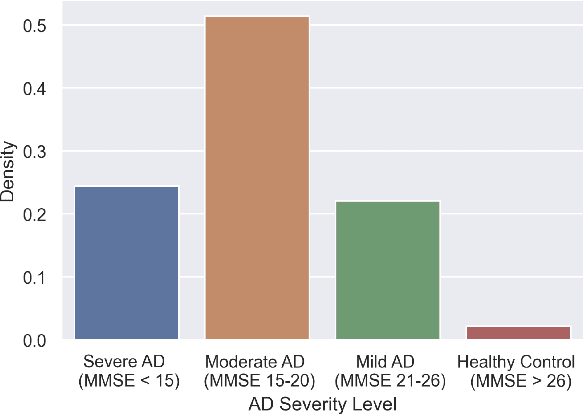

Detecting duplicate patient participation in clinical trials is a major challenge because repeated patients can undermine the credibility and accuracy of the trial's findings and result in significant health and financial risks. Developing accurate automated speaker verification (ASV) models is crucial to verify the identity of enrolled individuals and remove duplicates, but the size and quality of data influence ASV performance. However, there has been limited investigation into the factors that can affect ASV capabilities in clinical environments. In this paper, we bridge the gap by conducting analysis of how participant demographic characteristics, audio quality criteria, and severity level of Alzheimer's disease (AD) impact the performance of ASV utilizing a dataset of speech recordings from 659 participants with varying levels of AD, obtained through multiple speech tasks. Our results indicate that ASV performance: 1) is slightly better on male speakers than on female speakers; 2) degrades for individuals who are above 70 years old; 3) is comparatively better for non-native English speakers than for native English speakers; 4) is negatively affected by clinician interference, noisy background, and unclear participant speech; 5) tends to decrease with an increase in the severity level of AD. Our study finds that voice biometrics raise fairness concerns as certain subgroups exhibit different ASV performances owing to their inherent voice characteristics. Moreover, the performance of ASV is influenced by the quality of speech recordings, which underscores the importance of improving the data collection settings in clinical trials.
Multi-modal deep learning system for depression and anxiety detection
Dec 30, 2022

Traditional screening practices for anxiety and depression pose an impediment to monitoring and treating these conditions effectively. However, recent advances in NLP and speech modelling allow textual, acoustic, and hand-crafted language-based features to jointly form the basis of future mental health screening and condition detection. Speech is a rich and readily available source of insight into an individual's cognitive state and by leveraging different aspects of speech, we can develop new digital biomarkers for depression and anxiety. To this end, we propose a multi-modal system for the screening of depression and anxiety from self-administered speech tasks. The proposed model integrates deep-learned features from audio and text, as well as hand-crafted features that are informed by clinically-validated domain knowledge. We find that augmenting hand-crafted features with deep-learned features improves our overall classification F1 score comparing to a baseline of hand-crafted features alone from 0.58 to 0.63 for depression and from 0.54 to 0.57 for anxiety. The findings of our work suggest that speech-based biomarkers for depression and anxiety hold significant promise in the future of digital health.
Stay on Topic, Please: Aligning User Comments to the Content of a News Article
Mar 03, 2021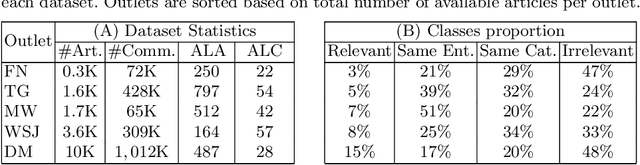

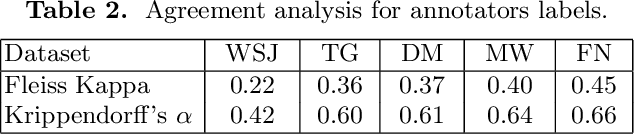
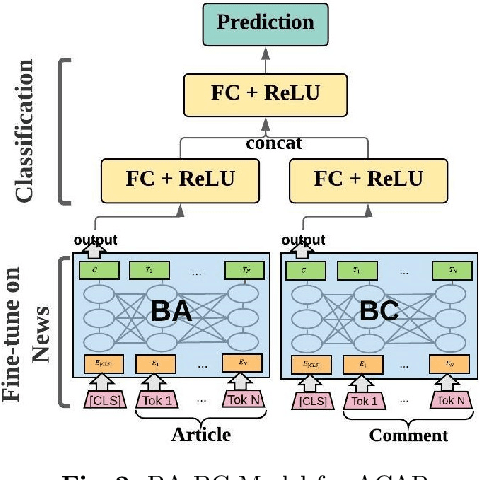
Social scientists have shown that up to 50% if the content posted to a news article have no relation to its journalistic content. In this study we propose a classification algorithm to categorize user comments posted to a new article base don their alignment to its content. The alignment seek to match user comments to an article based on similarity off content, entities in discussion, and topic. We proposed a BERTAC, BAERT-based approach that learn jointly article-comment embeddings and infers the relevance class of comments. We introduce an ordinal classification loss that penalizes the difference between the predicted and true label. We conduct a thorough study to show influence of the proposed loss on the learning process. The results on five representative news outlets show that our approach can learn the comment class with up to 36% average accuracy improvement compering to the baselines, and up to 25% compering to the BA-BC model. BA-BC is out approach that consists of two models aimed to capture dis-jointly the formal language of news articles and the informal language of comments. We also conduct a user study to evaluate human labeling performance to understand the difficulty of the classification task. The user agreement on comment-article alignment is "moderate" per Krippendorff's alpha score, which suggests that the classification task is difficult.
Extracting Entities and Topics from News and Connecting Criminal Records
May 03, 2020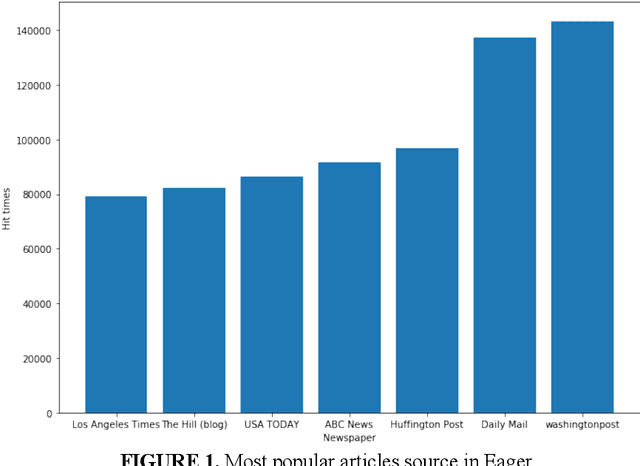
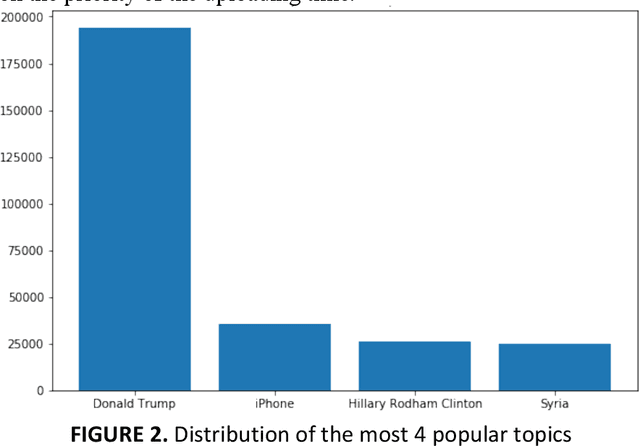
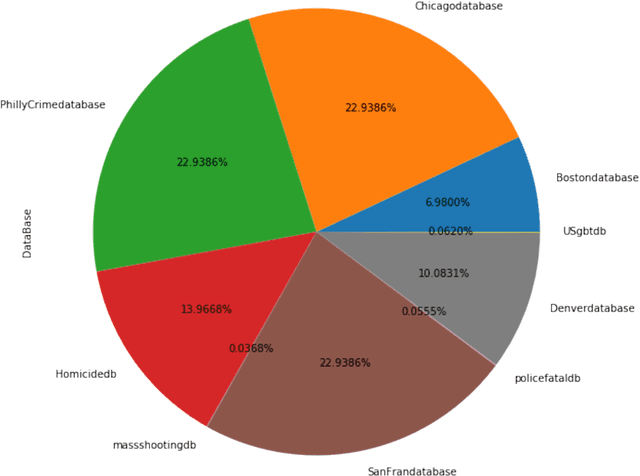
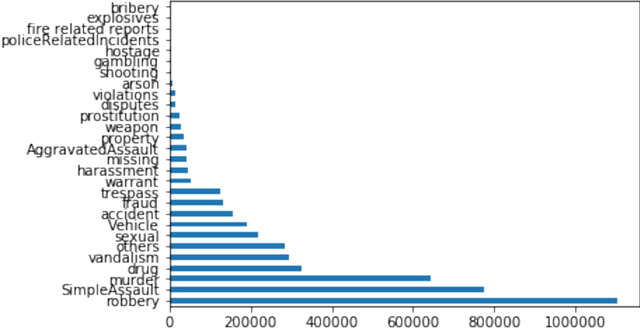
The goal of this paper is to summarize methodologies used in extracting entities and topics from a database of criminal records and from a database of newspapers. Statistical models had successfully been used in studying the topics of roughly 300,000 New York Times articles. In addition, these models had also been used to successfully analyze entities related to people, organizations, and places (D Newman, 2006). Additionally, analytical approaches, especially in hotspot mapping, were used in some researches with an aim to predict crime locations and circumstances in the future, and those approaches had been tested quite successfully (S Chainey, 2008). Based on the two above notions, this research was performed with the intention to apply data science techniques in analyzing a big amount of data, selecting valuable intelligence, clustering violations depending on their types of crime, and creating a crime graph that changes through time. In this research, the task was to download criminal datasets from Kaggle and a collection of news articles from Kaggle and EAGER project databases, and then to merge these datasets into one general dataset. The most important goal of this project was performing statistical and natural language processing methods to extract entities and topics as well as to group similar data points into correct clusters, in order to understand public data about U.S related crimes better.