 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokSuite: Measuring the Impact of Tokenizer Choice on Language Model Behavior
Dec 23, 2025Tokenizers provide the fundamental basis through which text is represented and processed by language models (LMs). Despite the importance of tokenization, its role in LM performance and behavior is poorly understood due to the challenge of measuring the impact of tokenization in isolation. To address this need, we present TokSuite, a collection of models and a benchmark that supports research into tokenization's influence on LMs. Specifically, we train fourteen models that use different tokenizers but are otherwise identical using the same architecture, dataset, training budget, and initialization. Additionally, we curate and release a new benchmark that specifically measures model performance subject to real-world perturbations that are likely to influence tokenization. Together, TokSuite allows robust decoupling of the influence of a model's tokenizer, supporting a series of novel findings that elucidate the respective benefits and shortcomings of a wide range of popular tokenizers.
Merging in a Bottle: Differentiable Adaptive Merging (DAM) and the Path from Averaging to Automation
Oct 10, 2024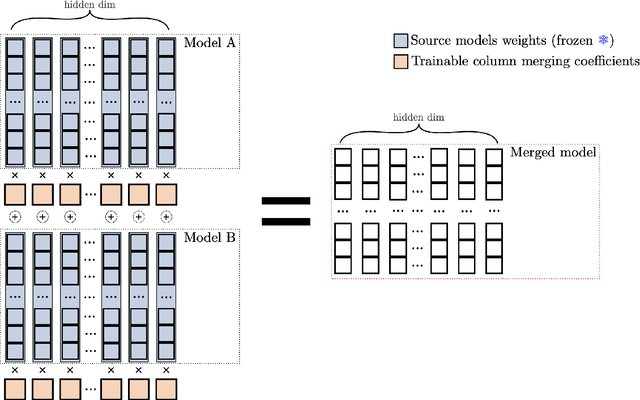

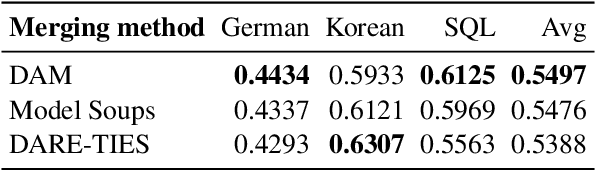
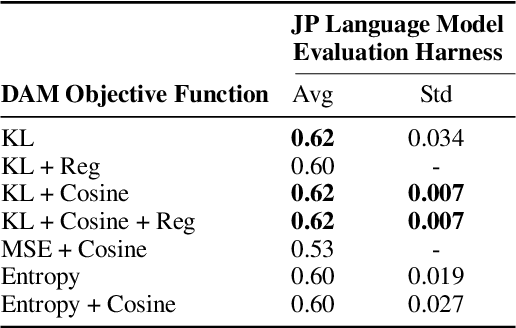
By merging models, AI systems can combine the distinct strengths of separate language models, achieving a balance between multiple capabilities without requiring substantial retraining. However, the integration process can be intricate due to differences in training methods and fine-tuning, typically necessitating specialized knowledge and repeated refinement. This paper explores model merging techniques across a spectrum of complexity, examining where automated methods like evolutionary strategies stand compared to hyperparameter-driven approaches such as DARE, TIES-Merging and simpler methods like Model Soups. In addition, we introduce Differentiable Adaptive Merging (DAM), an efficient, adaptive merging approach as an alternative to evolutionary merging that optimizes model integration through scaling coefficients, minimizing computational demands. Our findings reveal that even simple averaging methods, like Model Soups, perform competitively when model similarity is high, underscoring each technique's unique strengths and limitations. We open-sourced DAM, including the implementation code and experiment pipeline, on GitHub: https://github.com/arcee-ai/DAM.
Zero-Shot Multi-Lingual Speaker Verification in Clinical Trials
Apr 05, 2024Due to the substantial number of clinicians, patients, and data collection environments involved in clinical trials, gathering data of superior quality poses a significant challenge. In clinical trials, patients are assessed based on their speech data to detect and monitor cognitive and mental health disorders. We propose using these speech recordings to verify the identities of enrolled patients and identify and exclude the individuals who try to enroll multiple times in the same trial. Since clinical studies are often conducted across different countries, creating a system that can perform speaker verification in diverse languages without additional development effort is imperative. We evaluate pre-trained TitaNet, ECAPA-TDNN, and SpeakerNet models by enrolling and testing with speech-impaired patients speaking English, German, Danish, Spanish, and Arabic languages. Our results demonstrate that tested models can effectively generalize to clinical speakers, with less than 2.7% EER for European Languages and 8.26% EER for Arabic. This represents a significant step in developing more versatile and efficient speaker verification systems for cognitive and mental health clinical trials that can be used across a wide range of languages and dialects, substantially reducing the effort required to develop speaker verification systems for multiple languages. We also evaluate how speech tasks and number of speakers involved in the trial influence the performance and show that the type of speech tasks impacts the model performance.
Arcee's MergeKit: A Toolkit for Merging Large Language Models
Mar 21, 2024The rapid expansion of the open-source language model landscape presents an opportunity to merge the competencies of these model checkpoints by combining their parameters. Advances in transfer learning, the process of fine-tuning pretrained models for specific tasks, has resulted in the development of vast amounts of task-specific models, typically specialized in individual tasks and unable to utilize each other's strengths. Model merging facilitates the creation of multitask models without the need for additional training, offering a promising avenue for enhancing model performance and versatility. By preserving the intrinsic capabilities of the original models, model merging addresses complex challenges in AI - including the difficulties of catastrophic forgetting and multitask learning. To support this expanding area of research, we introduce MergeKit, a comprehensive, open-source library designed to facilitate the application of model merging strategies. MergeKit offers an extensible framework to efficiently merge models on any hardware, providing utility to researchers and practitioners. To date, thousands of models have been merged by the open-source community, leading to the creation of some of the worlds most powerful open-source model checkpoints, as assessed by the Open LLM Leaderboard. The library is accessible at https://github.com/arcee-ai/MergeKit.
Factors Affecting the Performance of Automated Speaker Verification in Alzheimer's Disease Clinical Trials
Jun 20, 2023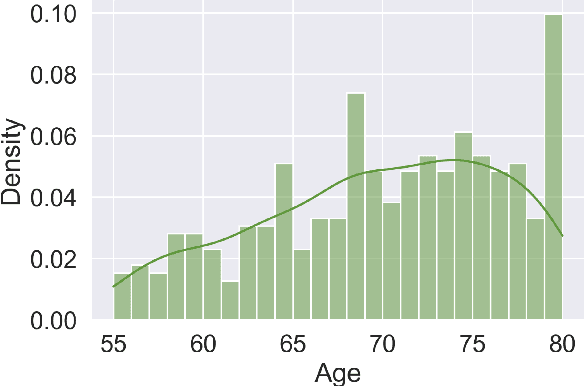

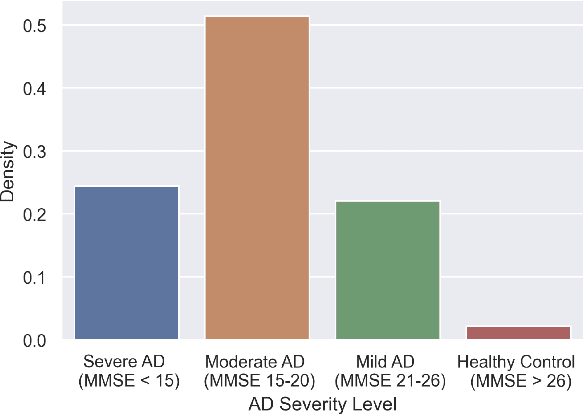

Detecting duplicate patient participation in clinical trials is a major challenge because repeated patients can undermine the credibility and accuracy of the trial's findings and result in significant health and financial risks. Developing accurate automated speaker verification (ASV) models is crucial to verify the identity of enrolled individuals and remove duplicates, but the size and quality of data influence ASV performance. However, there has been limited investigation into the factors that can affect ASV capabilities in clinical environments. In this paper, we bridge the gap by conducting analysis of how participant demographic characteristics, audio quality criteria, and severity level of Alzheimer's disease (AD) impact the performance of ASV utilizing a dataset of speech recordings from 659 participants with varying levels of AD, obtained through multiple speech tasks. Our results indicate that ASV performance: 1) is slightly better on male speakers than on female speakers; 2) degrades for individuals who are above 70 years old; 3) is comparatively better for non-native English speakers than for native English speakers; 4) is negatively affected by clinician interference, noisy background, and unclear participant speech; 5) tends to decrease with an increase in the severity level of AD. Our study finds that voice biometrics raise fairness concerns as certain subgroups exhibit different ASV performances owing to their inherent voice characteristics. Moreover, the performance of ASV is influenced by the quality of speech recordings, which underscores the importance of improving the data collection settings in clinical trials.
DEPAC: a Corpus for Depression and Anxiety Detection from Speech
Jun 20, 2023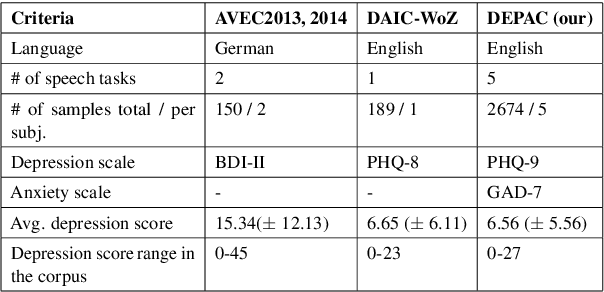

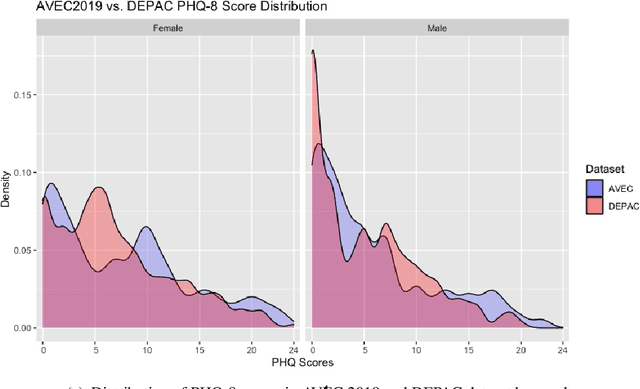
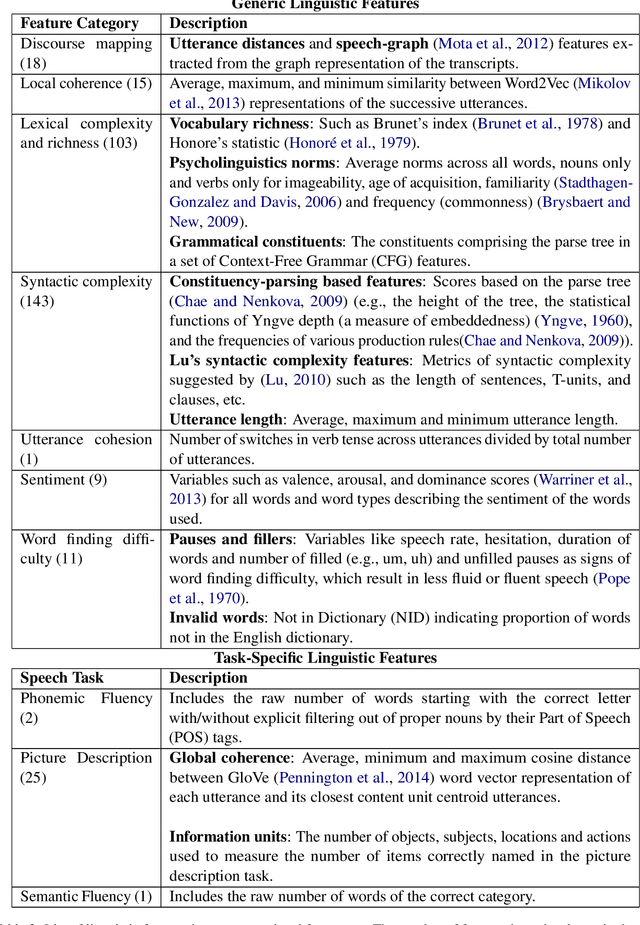
Mental distress like depression and anxiety contribute to the largest proportion of the global burden of diseases. Automated diagnosis systems of such disorders, empowered by recent innovations in Artificial Intelligence, can pave the way to reduce the sufferings of the affected individuals. Development of such systems requires information-rich and balanced corpora. In this work, we introduce a novel mental distress analysis audio dataset DEPAC, labeled based on established thresholds on depression and anxiety standard screening tools. This large dataset comprises multiple speech tasks per individual, as well as relevant demographic information. Alongside, we present a feature set consisting of hand-curated acoustic and linguistic features, which were found effective in identifying signs of mental illnesses in human speech. Finally, we justify the quality and effectiveness of our proposed audio corpus and feature set in predicting depression severity by comparing the performance of baseline machine learning models built on this dataset with baseline models trained on other well-known depression corpora.
Data-driven Approach to Differentiating between Depression and Dementia from Noisy Speech and Language Data
Oct 07, 2022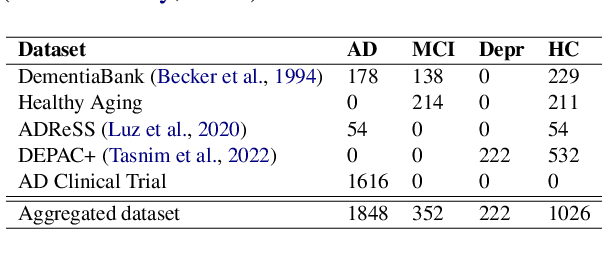
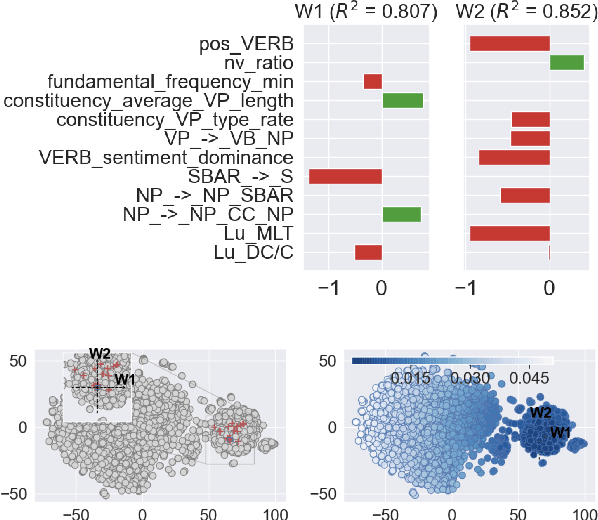

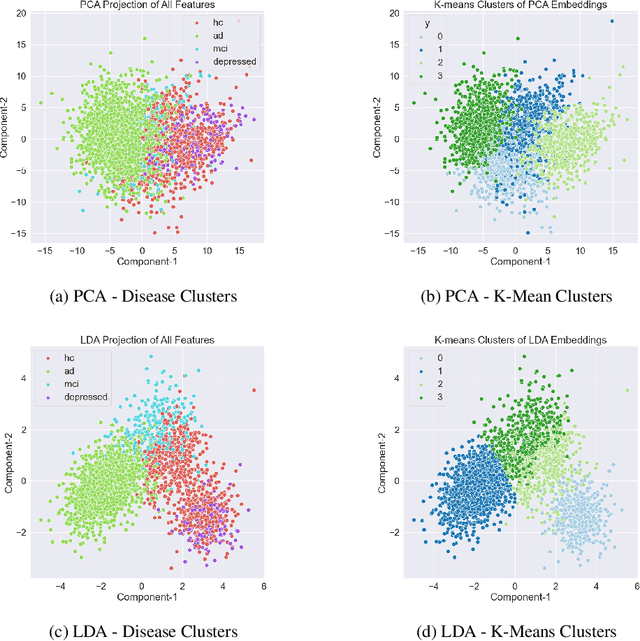
A significant number of studies apply acoustic and linguistic characteristics of human speech as prominent markers of dementia and depression. However, studies on discriminating depression from dementia are rare. Co-morbid depression is frequent in dementia and these clinical conditions share many overlapping symptoms, but the ability to distinguish between depression and dementia is essential as depression is often curable. In this work, we investigate the ability of clustering approaches in distinguishing between depression and dementia from human speech. We introduce a novel aggregated dataset, which combines narrative speech data from multiple conditions, i.e., Alzheimer's disease, mild cognitive impairment, healthy control, and depression. We compare linear and non-linear clustering approaches and show that non-linear clustering techniques distinguish better between distinct disease clusters. Our interpretability analysis shows that the main differentiating symptoms between dementia and depression are acoustic abnormality, repetitiveness (or circularity) of speech, word finding difficulty, coherence impairment, and differences in lexical complexity and richness.