 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEPAC: a Corpus for Depression and Anxiety Detection from Speech
Jun 20, 2023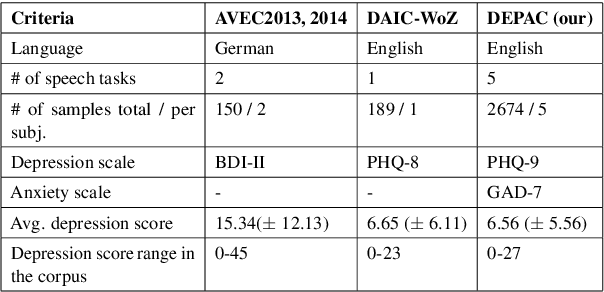

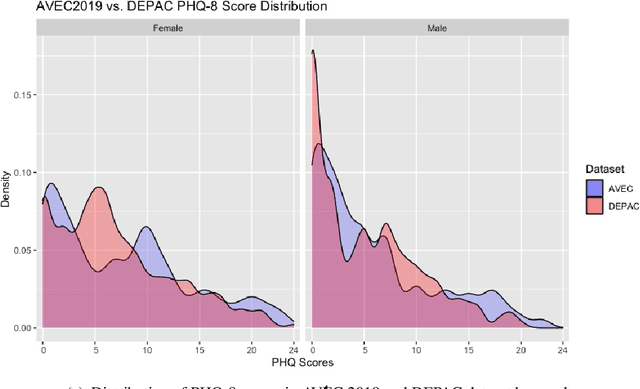
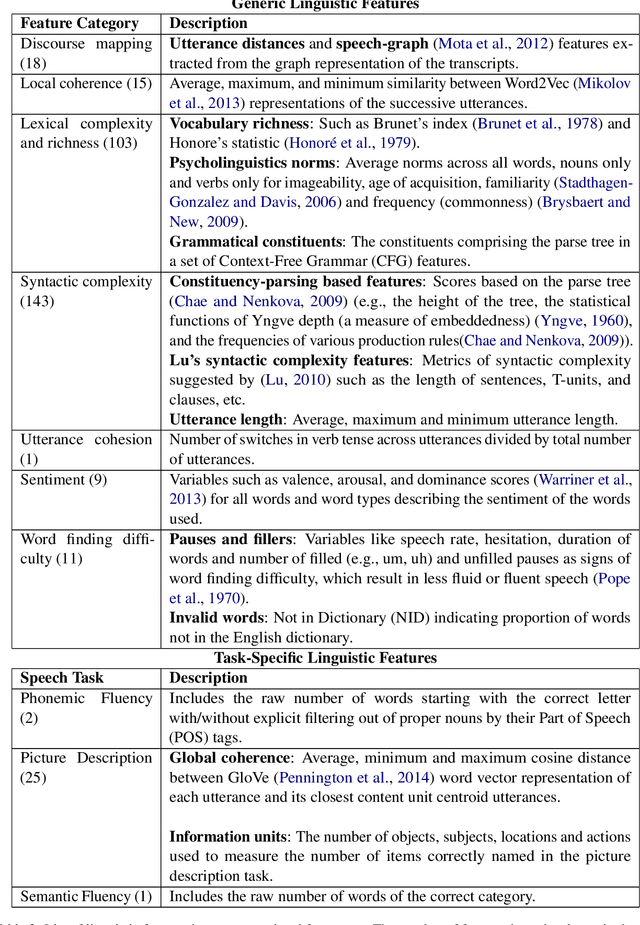
Mental distress like depression and anxiety contribute to the largest proportion of the global burden of diseases. Automated diagnosis systems of such disorders, empowered by recent innovations in Artificial Intelligence, can pave the way to reduce the sufferings of the affected individuals. Development of such systems requires information-rich and balanced corpora. In this work, we introduce a novel mental distress analysis audio dataset DEPAC, labeled based on established thresholds on depression and anxiety standard screening tools. This large dataset comprises multiple speech tasks per individual, as well as relevant demographic information. Alongside, we present a feature set consisting of hand-curated acoustic and linguistic features, which were found effective in identifying signs of mental illnesses in human speech. Finally, we justify the quality and effectiveness of our proposed audio corpus and feature set in predicting depression severity by comparing the performance of baseline machine learning models built on this dataset with baseline models trained on other well-known depression corpora.
Cost-effective Models for Detecting Depression from Speech
Feb 18, 2023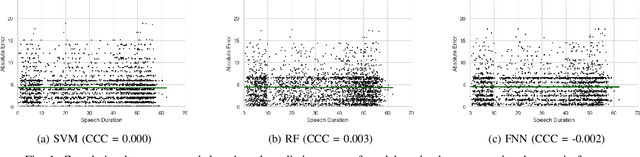
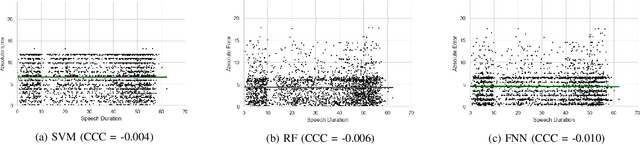
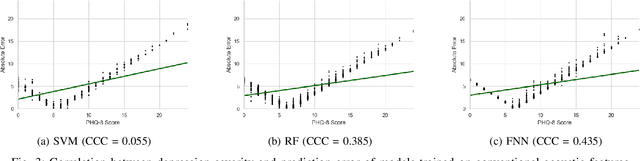
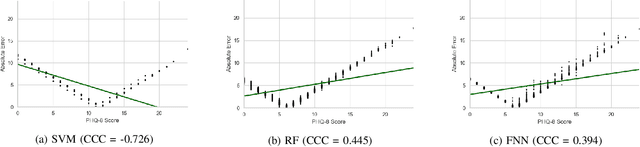
Depression is the most common psychological disorder and is considered as a leading cause of disability and suicide worldwide. An automated system capable of detecting signs of depression in human speech can contribute to ensuring timely and effective mental health care for individuals suffering from the disorder. Developing such automated system requires accurate machine learning models, capable of capturing signs of depression. However, state-of-the-art models based on deep acoustic representations require abundant data, meticulous selection of features, and rigorous training; the procedure involves enormous computational resources. In this work, we explore the effectiveness of two different acoustic feature groups - conventional hand-curated and deep representation features, for predicting the severity of depression from speech. We explore the relevance of possible contributing factors to the models' performance, including gender of the individual, severity of the disorder, content and length of speech. Our findings suggest that models trained on conventional acoustic features perform equally well or better than the ones trained on deep representation features at significantly lower computational cost, irrespective of other factors, e.g. content and length of speech, gender of the speaker and severity of the disorder. This makes such models a better fit for deployment where availability of computational resources is restricted, such as real time depression monitoring applications in smart devices.