 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuMuon: Nuclear-Norm-Constrained Muon for Compressible LLM Training
Mar 04, 2026The rapid progress of large language models (LLMs) is increasingly constrained by memory and deployment costs, motivating compression methods for practical deployment. Many state-of-the-art compression pipelines leverage the low-rank structure of trained weight matrices, a phenomenon often associated with the properties of popular optimizers such as Adam. In this context, Muon is a recently proposed optimizer that improves LLM pretraining via full-rank update steps, but its induced weight-space structure has not been characterized yet. In this work, we report a surprising empirical finding: despite imposing full-rank updates, Muon-trained models exhibit pronounced low-rank structure in their weight matrices and are readily compressible under standard pipelines. Motivated by this insight, we propose NuMuon, which augments Muon with a nuclear-norm constraint on the update direction, further constraining the learned weights toward low-rank structure. Across billion-parameter-scale models, we show that NuMuon increases weight compressibility and improves post-compression model quality under state-of-the-art LLM compression pipelines while retaining Muon's favorable convergence behavior.
Merging in a Bottle: Differentiable Adaptive Merging (DAM) and the Path from Averaging to Automation
Oct 10, 2024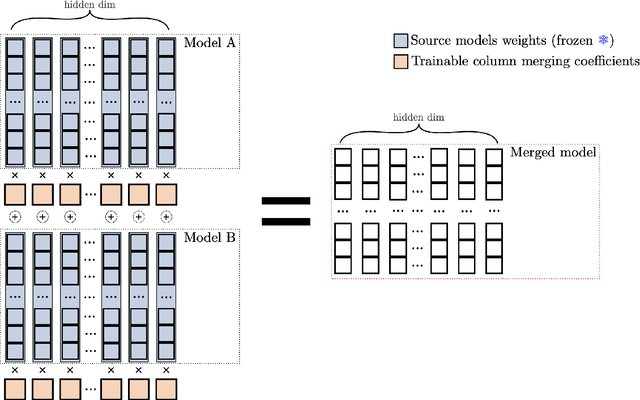

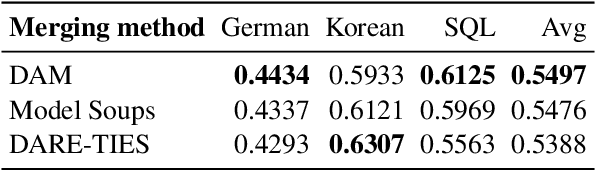
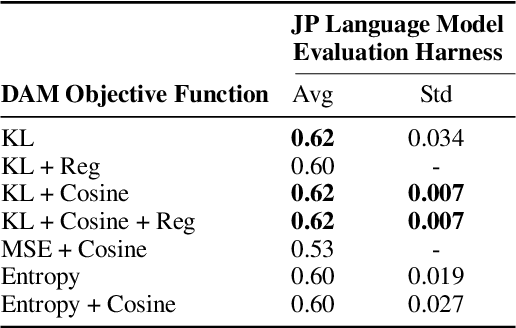
By merging models, AI systems can combine the distinct strengths of separate language models, achieving a balance between multiple capabilities without requiring substantial retraining. However, the integration process can be intricate due to differences in training methods and fine-tuning, typically necessitating specialized knowledge and repeated refinement. This paper explores model merging techniques across a spectrum of complexity, examining where automated methods like evolutionary strategies stand compared to hyperparameter-driven approaches such as DARE, TIES-Merging and simpler methods like Model Soups. In addition, we introduce Differentiable Adaptive Merging (DAM), an efficient, adaptive merging approach as an alternative to evolutionary merging that optimizes model integration through scaling coefficients, minimizing computational demands. Our findings reveal that even simple averaging methods, like Model Soups, perform competitively when model similarity is high, underscoring each technique's unique strengths and limitations. We open-sourced DAM, including the implementation code and experiment pipeline, on GitHub: https://github.com/arcee-ai/DAM.
Domain Adaptation of Llama3-70B-Instruct through Continual Pre-Training and Model Merging: A Comprehensive Evaluation
Jun 21, 2024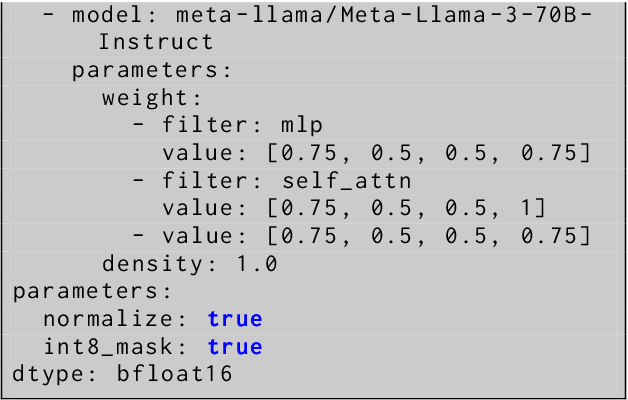
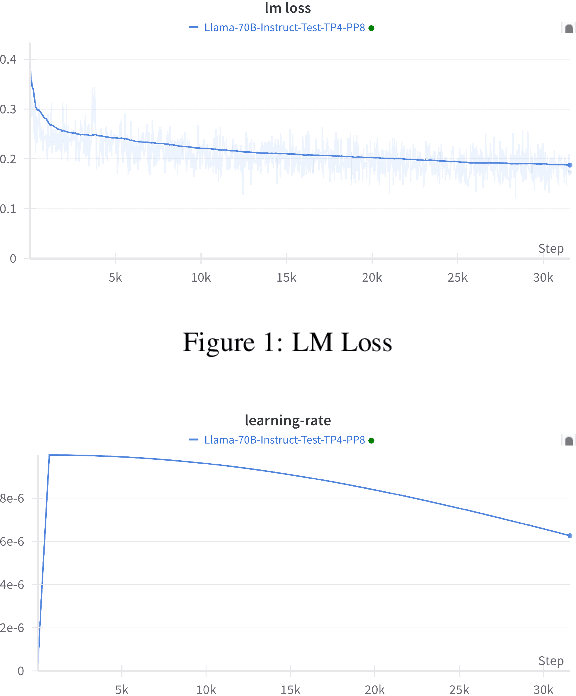
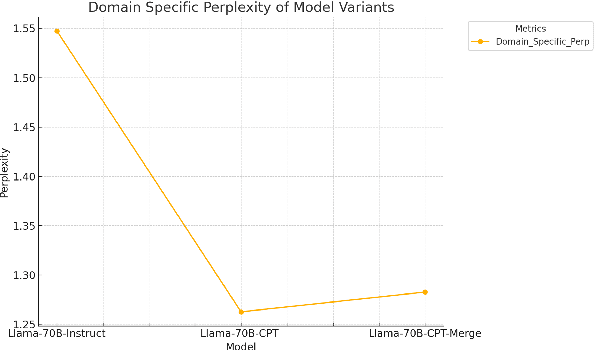
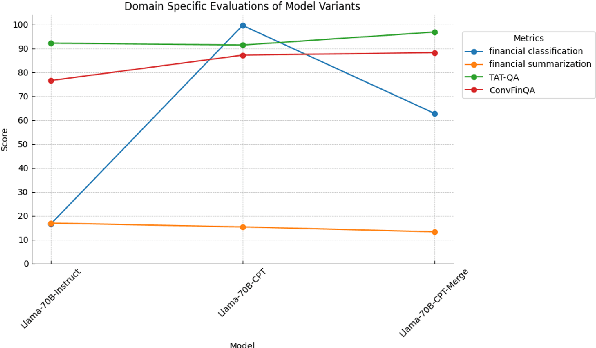
We conducted extensive experiments on domain adaptation of the Meta-Llama-3-70B-Instruct model on SEC data, exploring its performance on both general and domain-specific benchmarks. Our focus included continual pre-training (CPT) and model merging, aiming to enhance the model's domain-specific capabilities while mitigating catastrophic forgetting. Through this study, we evaluated the impact of integrating financial regulatory data into a robust language model and examined the effectiveness of our model merging techniques in preserving and improving the model's instructive abilities. The model is accessible at hugging face: https://huggingface.co/arcee-ai/Llama-3-SEC-Base, arcee-ai/Llama-3-SEC-Base. This is an intermediate checkpoint of our final model, which has seen 20B tokens so far. The full model is still in the process of training. This is a preprint technical report with thorough evaluations to understand the entire process.
Arcee's MergeKit: A Toolkit for Merging Large Language Models
Mar 21, 2024The rapid expansion of the open-source language model landscape presents an opportunity to merge the competencies of these model checkpoints by combining their parameters. Advances in transfer learning, the process of fine-tuning pretrained models for specific tasks, has resulted in the development of vast amounts of task-specific models, typically specialized in individual tasks and unable to utilize each other's strengths. Model merging facilitates the creation of multitask models without the need for additional training, offering a promising avenue for enhancing model performance and versatility. By preserving the intrinsic capabilities of the original models, model merging addresses complex challenges in AI - including the difficulties of catastrophic forgetting and multitask learning. To support this expanding area of research, we introduce MergeKit, a comprehensive, open-source library designed to facilitate the application of model merging strategies. MergeKit offers an extensible framework to efficiently merge models on any hardware, providing utility to researchers and practitioners. To date, thousands of models have been merged by the open-source community, leading to the creation of some of the worlds most powerful open-source model checkpoints, as assessed by the Open LLM Leaderboard. The library is accessible at https://github.com/arcee-ai/MergeKit.
Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering
Oct 06, 2022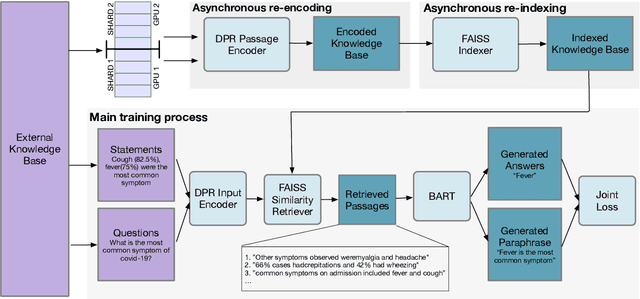
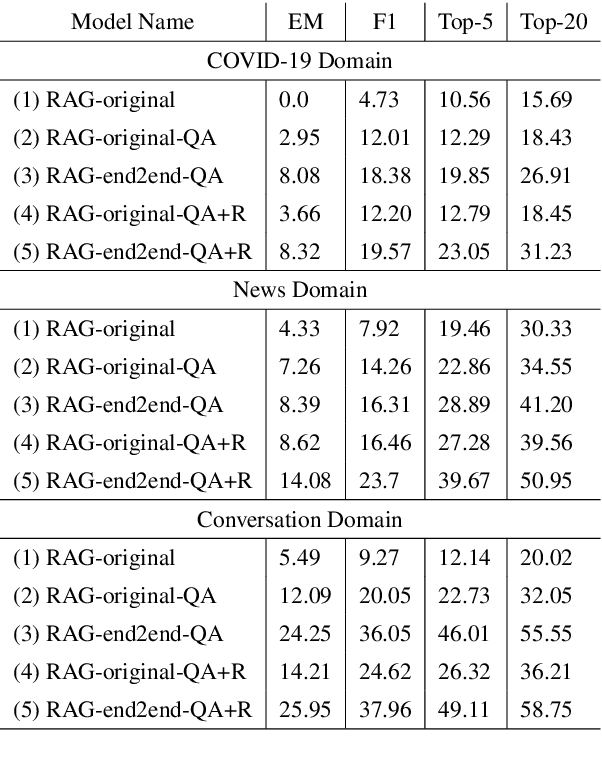
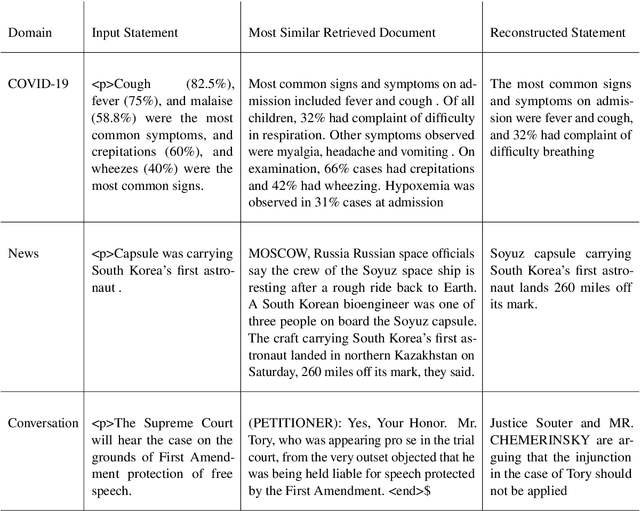
Retrieval Augment Generation (RAG) is a recent advancement in Open-Domain Question Answering (ODQA). RAG has only been trained and explored with a Wikipedia-based external knowledge base and is not optimized for use in other specialized domains such as healthcare and news. In this paper, we evaluate the impact of joint training of the retriever and generator components of RAG for the task of domain adaptation in ODQA. We propose \textit{RAG-end2end}, an extension to RAG, that can adapt to a domain-specific knowledge base by updating all components of the external knowledge base during training. In addition, we introduce an auxiliary training signal to inject more domain-specific knowledge. This auxiliary signal forces \textit{RAG-end2end} to reconstruct a given sentence by accessing the relevant information from the external knowledge base. Our novel contribution is unlike RAG, RAG-end2end does joint training of the retriever and generator for the end QA task and domain adaptation. We evaluate our approach with datasets from three domains: COVID-19, News, and Conversations, and achieve significant performance improvements compared to the original RAG model. Our work has been open-sourced through the Huggingface Transformers library, attesting to our work's credibility and technical consistency.
Fine-tune the Entire RAG Architecture for Question-Answering
Jun 22, 2021In this paper, we illustrate how to fine-tune the entire Retrieval Augment Generation (RAG) architecture in an end-to-end manner. We highlighted the main engineering challenges that needed to be addressed to achieve this objective. We also compare how end-to-end RAG architecture outperforms the original RAG architecture for the task of question answering. We have open-sourced our implementation in the HuggingFace Transformers library.
Jointly Fine-Tuning "BERT-like" Self Supervised Models to Improve Multimodal Speech Emotion Recognition
Aug 15, 2020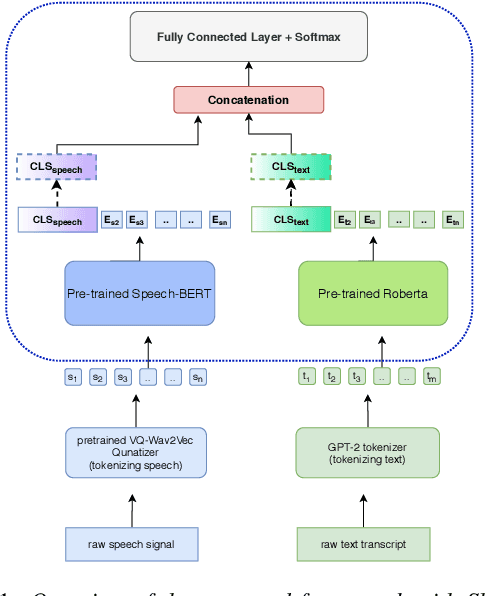
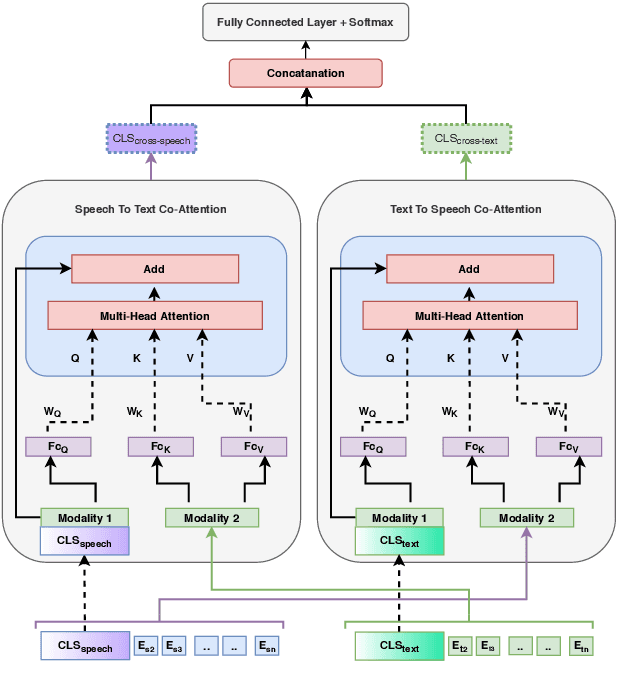
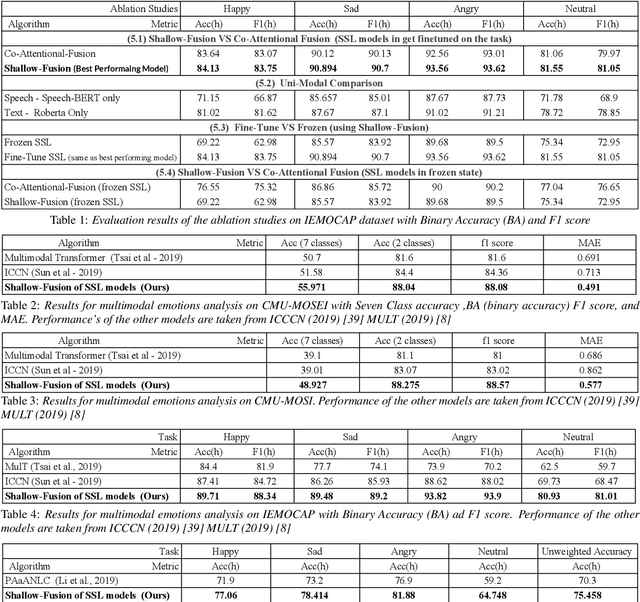
Multimodal emotion recognition from speech is an important area in affective computing. Fusing multiple data modalities and learning representations with limited amounts of labeled data is a challenging task. In this paper, we explore the use of modality-specific "BERT-like" pretrained Self Supervised Learning (SSL) architectures to represent both speech and text modalities for the task of multimodal speech emotion recognition. By conducting experiments on three publicly available datasets (IEMOCAP, CMU-MOSEI, and CMU-MOSI), we show that jointly fine-tuning "BERT-like" SSL architectures achieve state-of-the-art (SOTA) results. We also evaluate two methods of fusing speech and text modalities and show that a simple fusion mechanism can outperform more complex ones when using SSL models that have similar architectural properties to BERT.
VUSFA:Variational Universal Successor Features Approximator to Improve Transfer DRL for Target Driven Visual Navigation
Aug 18, 2019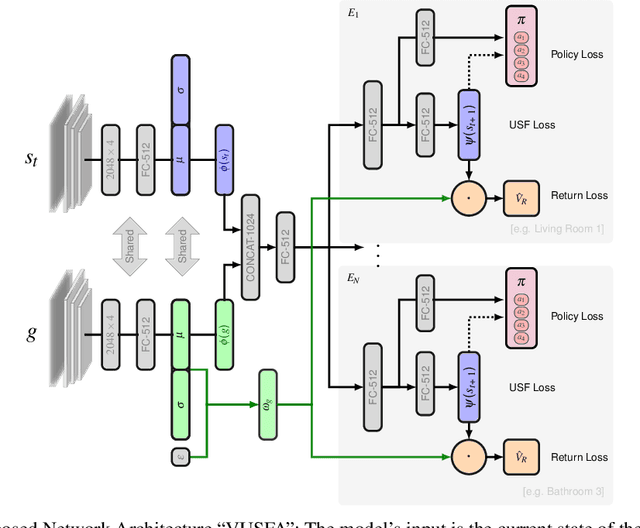
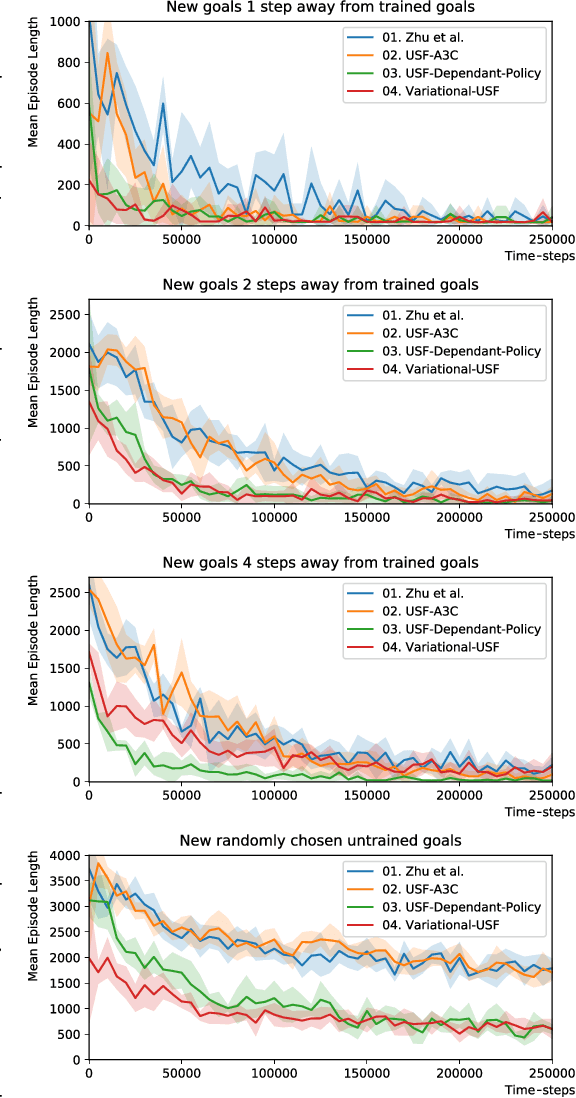

In this paper, we show how novel transfer reinforcement learning techniques can be applied to the complex task of target driven navigation using the photorealistic AI2THOR simulator. Specifically, we build on the concept of Universal Successor Features with an A3C agent. We introduce the novel architectural contribution of a Successor Feature Dependant Policy (SFDP) and adopt the concept of Variational Information Bottlenecks to achieve state of the art performance. VUSFA, our final architecture, is a straightforward approach that can be implemented using our open source repository. Our approach is generalizable, showed greater stability in training, and outperformed recent approaches in terms of transfer learning ability.
Target Driven Visual Navigation with Hybrid Asynchronous Universal Successor Representations
Nov 27, 2018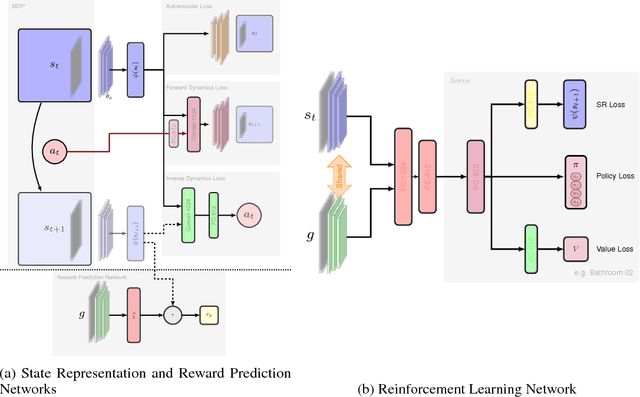


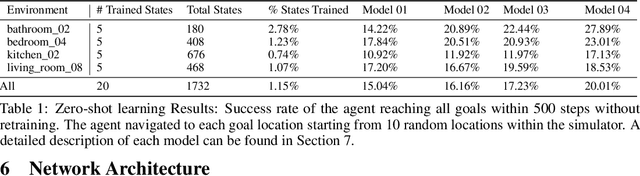
Being able to navigate to a target with minimal supervision and prior knowledge is critical to creating human-like assistive agents. Prior work on map-based and map-less approaches have limited generalizability. In this paper, we present a novel approach, Hybrid Asynchronous Universal Successor Representations (HAUSR), which overcomes the problem of generalizability to new goals by adapting recent work on Universal Successor Representations with Asynchronous Actor-Critic Agents. We show that the agent was able to successfully reach novel goals and we were able to quickly fine-tune the network for adapting to new scenes. This opens up novel application scenarios where intelligent agents could learn from and adapt to a wide range of environments with minimal human input.