 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Tokenizer Transplantation via Orthogonal Matching Pursuit
Jun 07, 2025We present a training-free method to transplant tokenizers in pretrained large language models (LLMs) by reconstructing unseen token embeddings via Orthogonal Matching Pursuit (OMP). Specifically, we approximate each out-of-vocabulary token as a sparse linear combination of shared tokens, in two phases: first, compute each new token's representation in the donor embedding space with a small dictionary of shared anchor tokens, then transfer these same sparse coefficients back into the base model's embedding space. On two challenging cross-tokenizer tasks--Llama$\to$Mistral NeMo (12B) and Qwen$\to$Llama (1B)--we show that OMP achieves best zero-shot preservation of the base model's performance across multiple benchmarks, while other zero-shot approaches degrade significantly. Compared to baselines (zero-init, mean-init, and existing approaches like WECHSEL, FOCUS, ZETT), OMP consistently achieves the best overall performance, effectively bridging large tokenizer discrepancies without gradient updates. Our analysis further identifies mismatched numerical tokenization schemes as a critical challenge for preserving mathematical reasoning capabilities. This technique enables direct reuse of pretrained model weights with new tokenizers, facilitating cross-tokenizer knowledge distillation, speculative decoding, ensembling, merging, and domain-specific vocabulary adaptations. We integrate our method into the open-source mergekit-tokensurgeon tool for post hoc vocabulary realignment.
Domain Adaptation of Llama3-70B-Instruct through Continual Pre-Training and Model Merging: A Comprehensive Evaluation
Jun 21, 2024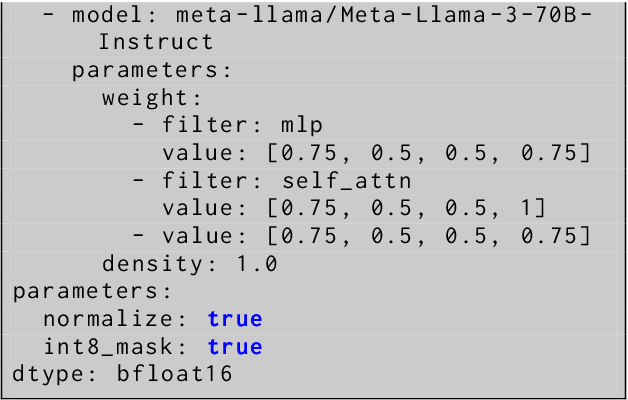
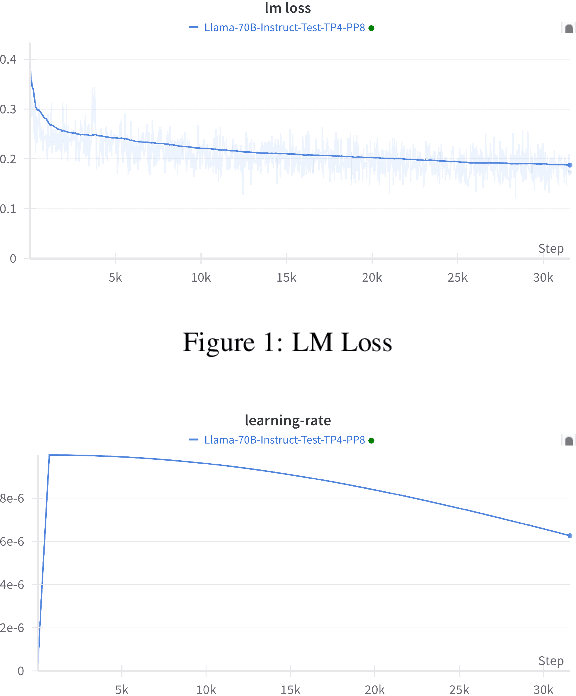
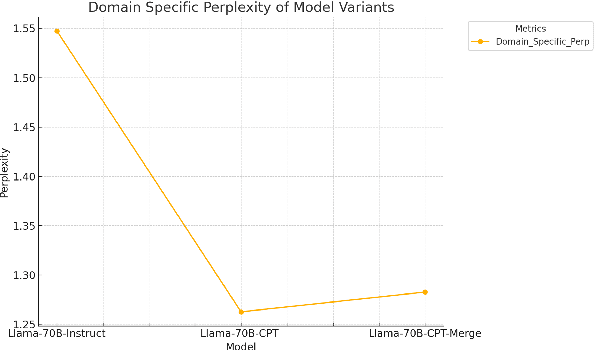
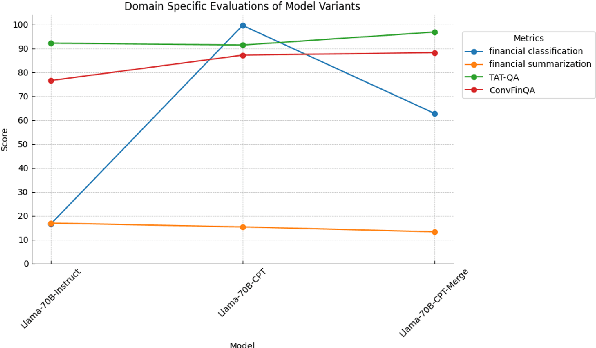
We conducted extensive experiments on domain adaptation of the Meta-Llama-3-70B-Instruct model on SEC data, exploring its performance on both general and domain-specific benchmarks. Our focus included continual pre-training (CPT) and model merging, aiming to enhance the model's domain-specific capabilities while mitigating catastrophic forgetting. Through this study, we evaluated the impact of integrating financial regulatory data into a robust language model and examined the effectiveness of our model merging techniques in preserving and improving the model's instructive abilities. The model is accessible at hugging face: https://huggingface.co/arcee-ai/Llama-3-SEC-Base, arcee-ai/Llama-3-SEC-Base. This is an intermediate checkpoint of our final model, which has seen 20B tokens so far. The full model is still in the process of training. This is a preprint technical report with thorough evaluations to understand the entire process.
Spectrum: Targeted Training on Signal to Noise Ratio
Jun 07, 2024Efficiently post-training large language models remains a challenging task due to the vast computational resources required. We present Spectrum, a method that accelerates LLM training by selectively targeting layer modules based on their signal-to-noise ratio (SNR), and freezing the remaining modules. Our approach, which utilizes an algorithm to compute module SNRs prior to training, has shown to effectively match the performance of full fine-tuning while reducing GPU memory usage. Experiments comparing Spectrum to existing methods such as QLoRA demonstrate its effectiveness in terms of model quality and VRAM efficiency in distributed environments.
Deep Haar Scattering Networks in Pattern Recognition: A promising approach
Nov 29, 2018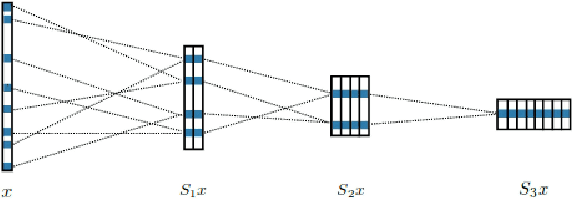



The aim of this paper is to discuss the use of Haar scattering networks, which is a very simple architecture that naturally supports a large number of stacked layers, yet with very few parameters, in a relatively broad set of pattern recognition problems, including regression and classification tasks. This architecture, basically, consists of stacking convolutional filters, that can be thought as a generalization of Haar wavelets, followed by non-linear operators which aim to extract symmetries and invariances that are later fed in a classification/regression algorithm. We show that good results can be obtained with the proposed method for both kind of tasks. We have outperformed the best available algorithms in 4 out of 18 important data classification problems, and have obtained a more robust performance than ARIMA and ETS time series methods in regression problems for data with strong periodicities.
Building Function Approximators on top of Haar Scattering Networks
Apr 09, 2018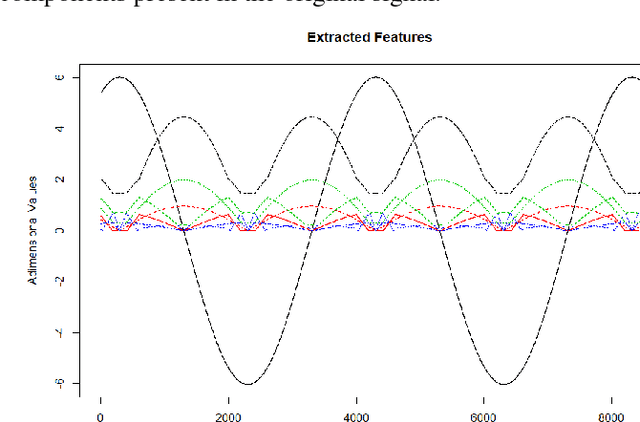



In this article we propose building general-purpose function approximators on top of Haar Scattering Networks. We advocate that this architecture enables a better comprehension of feature extraction, in addition to its implementation simplicity and low computational costs. We show its approximation and feature extraction capabilities in a wide range of different problems, which can be applied on several phenomena in signal processing, system identification, econometrics and other potential fields.
Generative Models for Stochastic Processes Using Convolutional Neural Networks
Jan 09, 2018
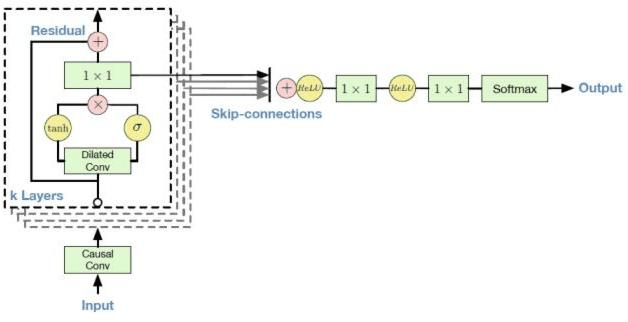

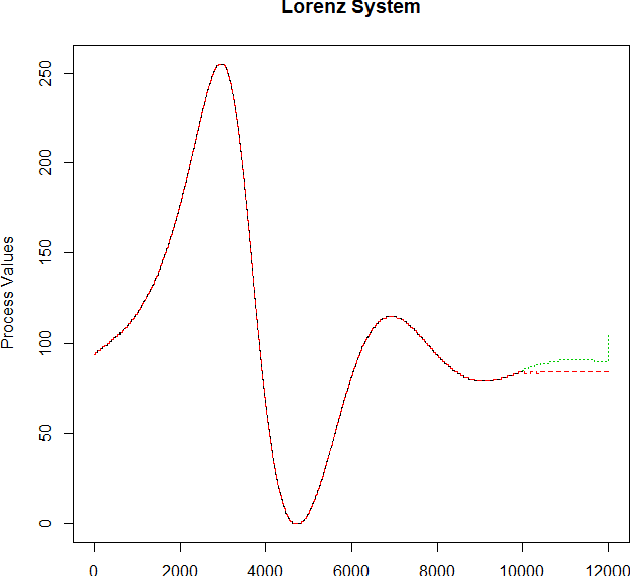
The present paper aims to demonstrate the usage of Convolutional Neural Networks as a generative model for stochastic processes, enabling researchers from a wide range of fields (such as quantitative finance and physics) to develop a general tool for forecasts and simulations without the need to identify/assume a specific system structure or estimate its parameters.