 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArcee Trinity Large Technical Report
Feb 19, 2026We present the technical report for Arcee Trinity Large, a sparse Mixture-of-Experts model with 400B total parameters and 13B activated per token. Additionally, we report on Trinity Nano and Trinity Mini, with Trinity Nano having 6B total parameters with 1B activated per token, Trinity Mini having 26B total parameters with 3B activated per token. The models' modern architecture includes interleaved local and global attention, gated attention, depth-scaled sandwich norm, and sigmoid routing for Mixture-of-Experts. For Trinity Large, we also introduce a new MoE load balancing strategy titled Soft-clamped Momentum Expert Bias Updates (SMEBU). We train the models using the Muon optimizer. All three models completed training with zero loss spikes. Trinity Nano and Trinity Mini were pre-trained on 10 trillion tokens, and Trinity Large was pre-trained on 17 trillion tokens. The model checkpoints are available at https://huggingface.co/arcee-ai.
Domain Adaptation of Llama3-70B-Instruct through Continual Pre-Training and Model Merging: A Comprehensive Evaluation
Jun 21, 2024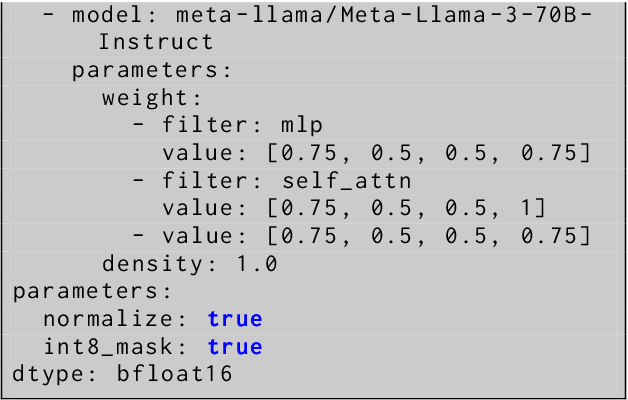
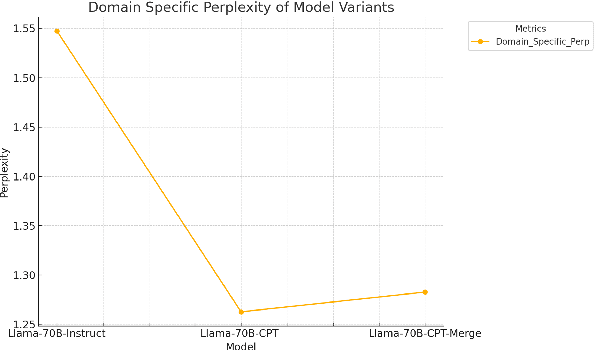
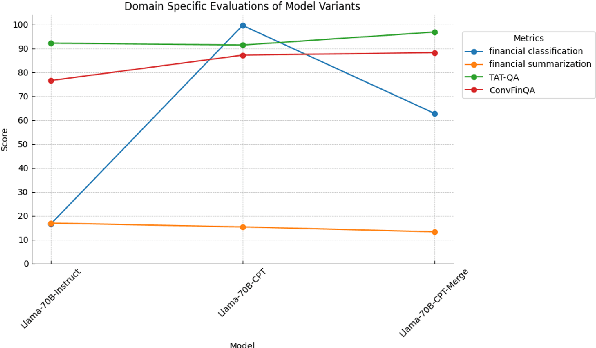
We conducted extensive experiments on domain adaptation of the Meta-Llama-3-70B-Instruct model on SEC data, exploring its performance on both general and domain-specific benchmarks. Our focus included continual pre-training (CPT) and model merging, aiming to enhance the model's domain-specific capabilities while mitigating catastrophic forgetting. Through this study, we evaluated the impact of integrating financial regulatory data into a robust language model and examined the effectiveness of our model merging techniques in preserving and improving the model's instructive abilities. The model is accessible at hugging face: https://huggingface.co/arcee-ai/Llama-3-SEC-Base, arcee-ai/Llama-3-SEC-Base. This is an intermediate checkpoint of our final model, which has seen 20B tokens so far. The full model is still in the process of training. This is a preprint technical report with thorough evaluations to understand the entire process.
Spectrum: Targeted Training on Signal to Noise Ratio
Jun 07, 2024Efficiently post-training large language models remains a challenging task due to the vast computational resources required. We present Spectrum, a method that accelerates LLM training by selectively targeting layer modules based on their signal-to-noise ratio (SNR), and freezing the remaining modules. Our approach, which utilizes an algorithm to compute module SNRs prior to training, has shown to effectively match the performance of full fine-tuning while reducing GPU memory usage. Experiments comparing Spectrum to existing methods such as QLoRA demonstrate its effectiveness in terms of model quality and VRAM efficiency in distributed environments.