 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation of Llama3-70B-Instruct through Continual Pre-Training and Model Merging: A Comprehensive Evaluation
Jun 21, 2024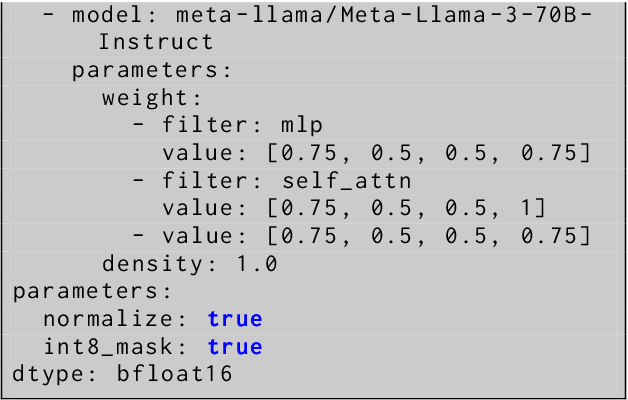
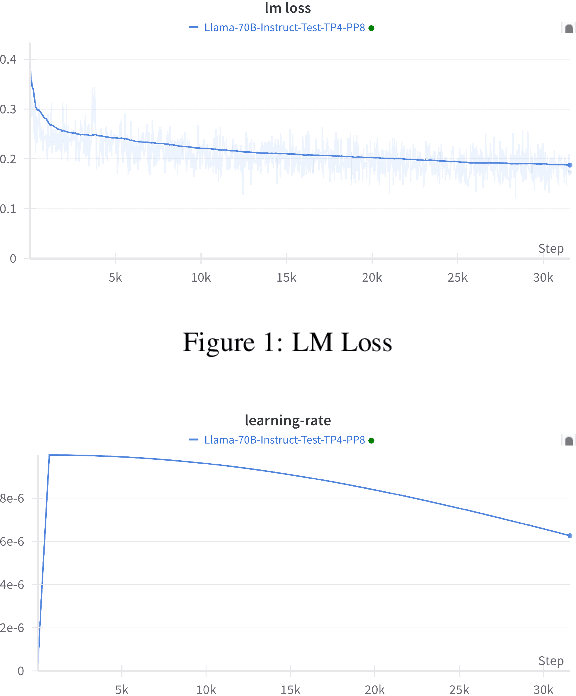
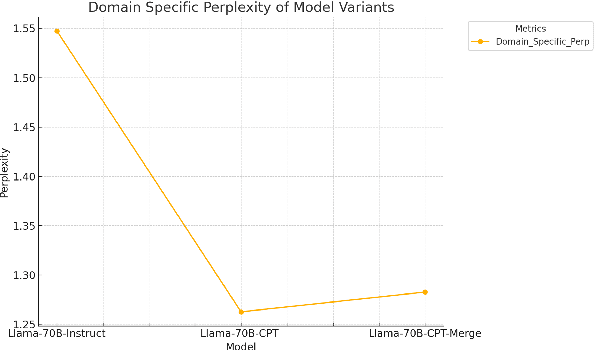
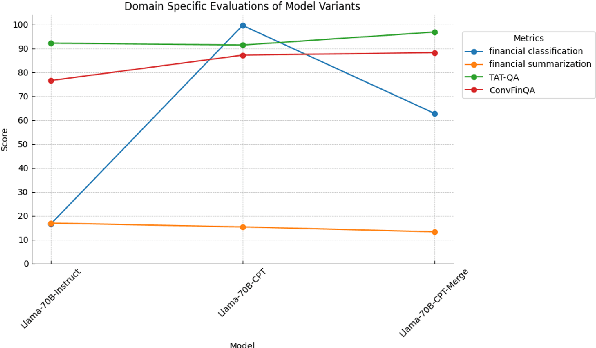
We conducted extensive experiments on domain adaptation of the Meta-Llama-3-70B-Instruct model on SEC data, exploring its performance on both general and domain-specific benchmarks. Our focus included continual pre-training (CPT) and model merging, aiming to enhance the model's domain-specific capabilities while mitigating catastrophic forgetting. Through this study, we evaluated the impact of integrating financial regulatory data into a robust language model and examined the effectiveness of our model merging techniques in preserving and improving the model's instructive abilities. The model is accessible at hugging face: https://huggingface.co/arcee-ai/Llama-3-SEC-Base, arcee-ai/Llama-3-SEC-Base. This is an intermediate checkpoint of our final model, which has seen 20B tokens so far. The full model is still in the process of training. This is a preprint technical report with thorough evaluations to understand the entire process.