 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Language Models for Recipe Generation: A Comparative Analysis and Benchmark Study
Feb 04, 2025



This research presents an exploration and study of the recipe generation task by fine-tuning various very small language models, with a focus on developing robust evaluation metrics and comparing across different language models the open-ended task of recipe generation. This study presents extensive experiments with multiple model architectures, ranging from T5-small (Raffel et al., 2023) and SmolLM-135M (Allal et al., 2024) to Phi-2 (Research, 2023),implementing both traditional NLP metrics and custom domain-specific evaluation metrics. Our novel evaluation framework incorporates recipe-specific metrics for assessing content quality and introduces an approach to allergen substitution. The results indicate that, while larger models generally perform better on standard metrics, the relationship between model size and recipe quality is more nuanced when considering domain-specific metrics. We find that SmolLM-360M and SmolLM-1.7B demonstrate comparable performance despite their size difference, while Phi-2 shows limitations in recipe generation despite its larger parameter count. Our comprehensive evaluation framework and allergen substitution system provide valuable insights for future work in recipe generation and broader NLG tasks that require domain expertise and safety considerations.
Domain Adaptation of Llama3-70B-Instruct through Continual Pre-Training and Model Merging: A Comprehensive Evaluation
Jun 21, 2024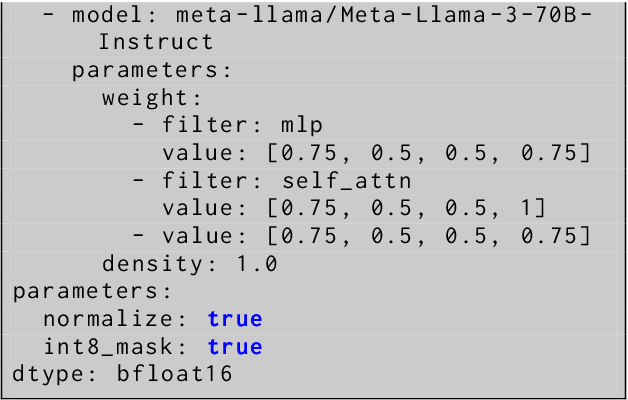
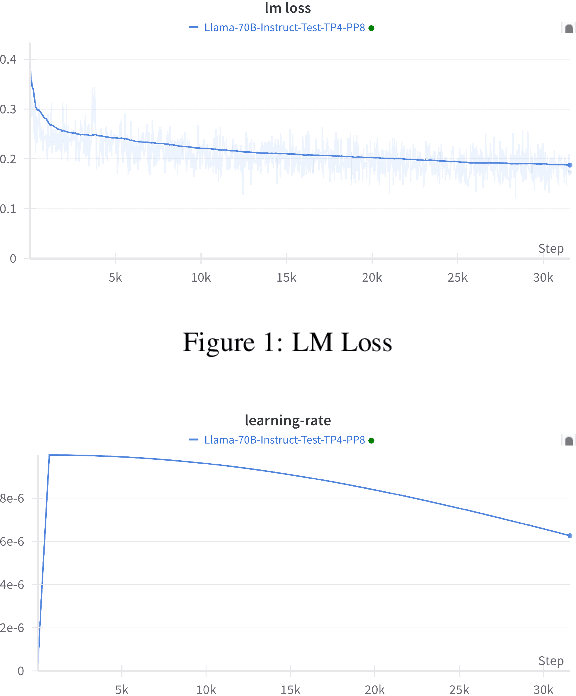
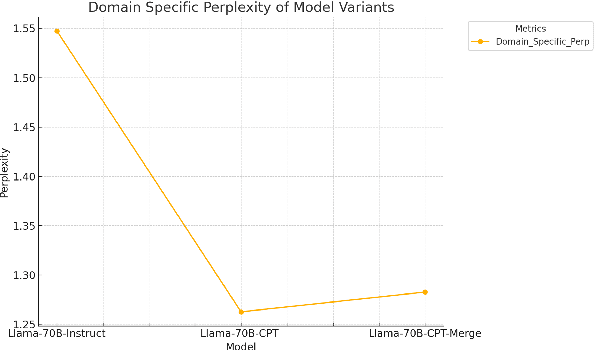
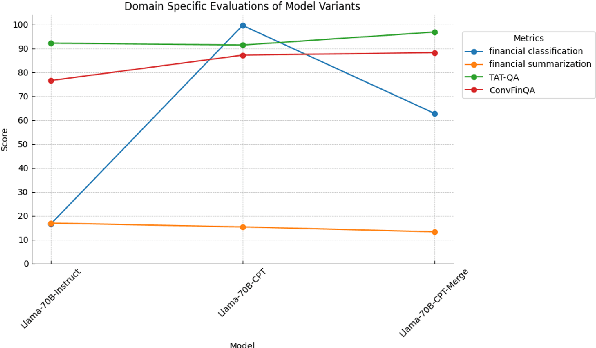
We conducted extensive experiments on domain adaptation of the Meta-Llama-3-70B-Instruct model on SEC data, exploring its performance on both general and domain-specific benchmarks. Our focus included continual pre-training (CPT) and model merging, aiming to enhance the model's domain-specific capabilities while mitigating catastrophic forgetting. Through this study, we evaluated the impact of integrating financial regulatory data into a robust language model and examined the effectiveness of our model merging techniques in preserving and improving the model's instructive abilities. The model is accessible at hugging face: https://huggingface.co/arcee-ai/Llama-3-SEC-Base, arcee-ai/Llama-3-SEC-Base. This is an intermediate checkpoint of our final model, which has seen 20B tokens so far. The full model is still in the process of training. This is a preprint technical report with thorough evaluations to understand the entire process.