 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Iterative Evaluation and Enhancement of Code Quality Using GPT-4o
Feb 11, 2025



This paper introduces CodeQUEST, a novel framework leveraging Large Language Models (LLMs) to iteratively evaluate and enhance code quality across multiple dimensions, including readability, maintainability, efficiency, and security. The framework is divided into two main components: an Evaluator that assesses code quality across ten dimensions, providing both quantitative scores and qualitative summaries, and an Optimizer that iteratively improves the code based on the Evaluator's feedback. Our study demonstrates that CodeQUEST can effectively and robustly evaluate code quality, with its assessments aligning closely with established code quality metrics. Through a series of experiments using a curated dataset of Python and JavaScript examples, CodeQUEST demonstrated significant improvements in code quality, achieving a mean relative percentage improvement of 52.6%. The framework's evaluations were validated against a set of proxy metrics comprising of Pylint Score, Radon Maintainability Index, and Bandit output logs, showing a meaningful correlation. This highlights the potential of LLMs in automating code quality evaluation and improvement processes, presenting a significant advancement toward enhancing software development practices. The code implementation of the framework is available at: https://github.com/jpmorganchase/CodeQuest.
Merging in a Bottle: Differentiable Adaptive Merging (DAM) and the Path from Averaging to Automation
Oct 10, 2024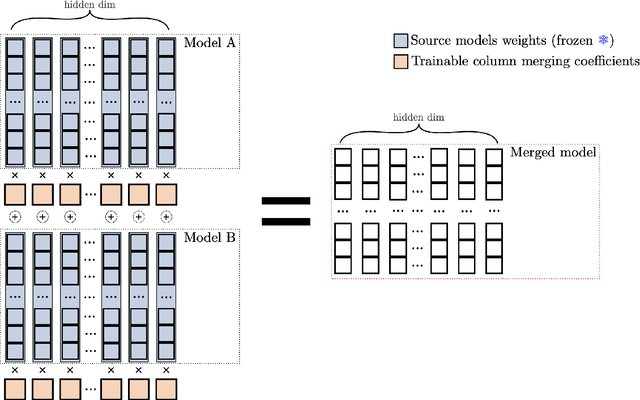

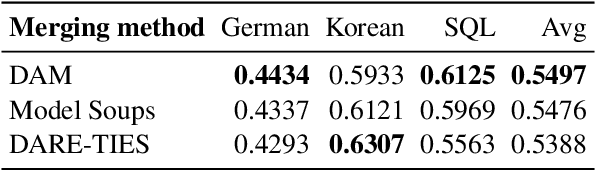
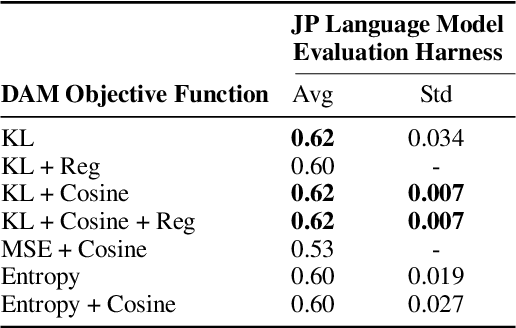
By merging models, AI systems can combine the distinct strengths of separate language models, achieving a balance between multiple capabilities without requiring substantial retraining. However, the integration process can be intricate due to differences in training methods and fine-tuning, typically necessitating specialized knowledge and repeated refinement. This paper explores model merging techniques across a spectrum of complexity, examining where automated methods like evolutionary strategies stand compared to hyperparameter-driven approaches such as DARE, TIES-Merging and simpler methods like Model Soups. In addition, we introduce Differentiable Adaptive Merging (DAM), an efficient, adaptive merging approach as an alternative to evolutionary merging that optimizes model integration through scaling coefficients, minimizing computational demands. Our findings reveal that even simple averaging methods, like Model Soups, perform competitively when model similarity is high, underscoring each technique's unique strengths and limitations. We open-sourced DAM, including the implementation code and experiment pipeline, on GitHub: https://github.com/arcee-ai/DAM.
An Unsupervised Method for Estimating Class Separability of Datasets with Application to LLMs Fine-Tuning
May 24, 2023
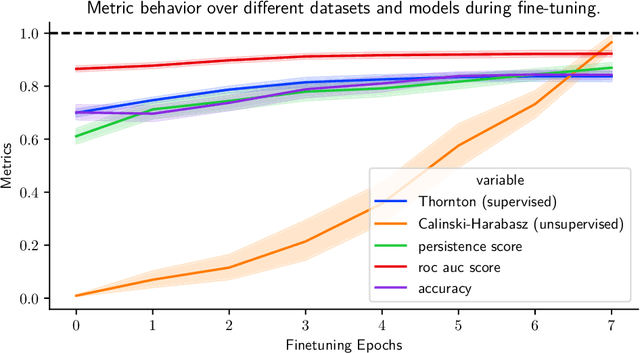


This paper proposes an unsupervised method that leverages topological characteristics of data manifolds to estimate class separability of the data without requiring labels. Experiments conducted in this paper on several datasets demonstrate a clear correlation and consistency between the class separability estimated by the proposed method with supervised metrics like Fisher Discriminant Ratio~(FDR) and cross-validation of a classifier, which both require labels. This can enable implementing learning paradigms aimed at learning from both labeled and unlabeled data, like semi-supervised and transductive learning. This would be particularly useful when we have limited labeled data and a relatively large unlabeled dataset that can be used to enhance the learning process. The proposed method is implemented for language model fine-tuning with automated stopping criterion by monitoring class separability of the embedding-space manifold in an unsupervised setting. The proposed methodology has been first validated on synthetic data, where the results show a clear consistency between class separability estimated by the proposed method and class separability computed by FDR. The method has been also implemented on both public and internal data. The results show that the proposed method can effectively aid -- without the need for labels -- a decision on when to stop or continue the fine-tuning of a language model and which fine-tuning iteration is expected to achieve a maximum classification performance through quantification of the class separability of the embedding manifold.
Spam-T5: Benchmarking Large Language Models for Few-Shot Email Spam Detection
Apr 05, 2023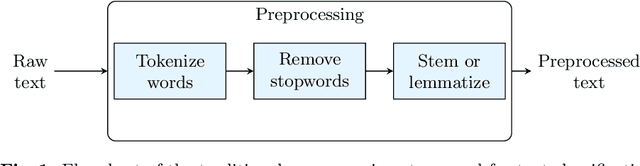



This paper investigates the effectiveness of large language models (LLMs) in email spam detection by comparing prominent models from three distinct families: BERT-like, Sentence Transformers, and Seq2Seq. Additionally, we examine well-established machine learning techniques for spam detection, such as Na\"ive Bayes and LightGBM, as baseline methods. We assess the performance of these models across four public datasets, utilizing different numbers of training samples (full training set and few-shot settings). Our findings reveal that, in the majority of cases, LLMs surpass the performance of the popular baseline techniques, particularly in few-shot scenarios. This adaptability renders LLMs uniquely suited to spam detection tasks, where labeled samples are limited in number and models require frequent updates. Additionally, we introduce Spam-T5, a Flan-T5 model that has been specifically adapted and fine-tuned for the purpose of detecting email spam. Our results demonstrate that Spam-T5 surpasses baseline models and other LLMs in the majority of scenarios, particularly when there are a limited number of training samples available. Our code is publicly available at https://github.com/jpmorganchase/emailspamdetection.
Predicting Bandwidth Utilization on Network Links Using Machine Learning
Dec 04, 2021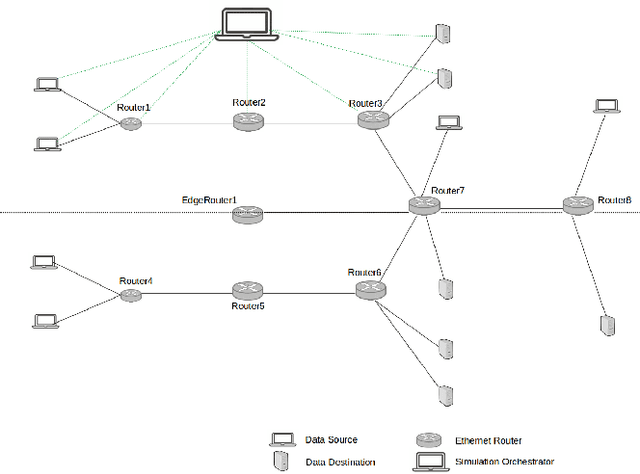
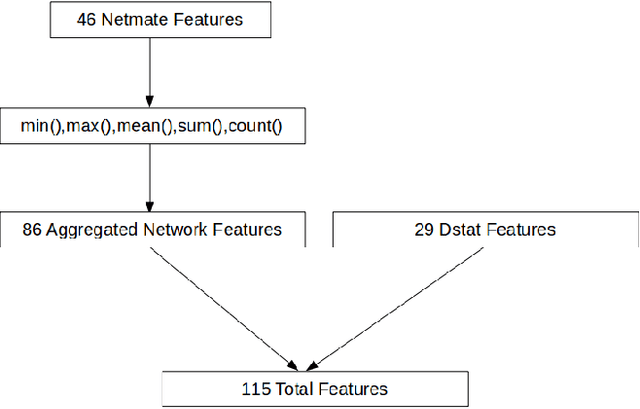
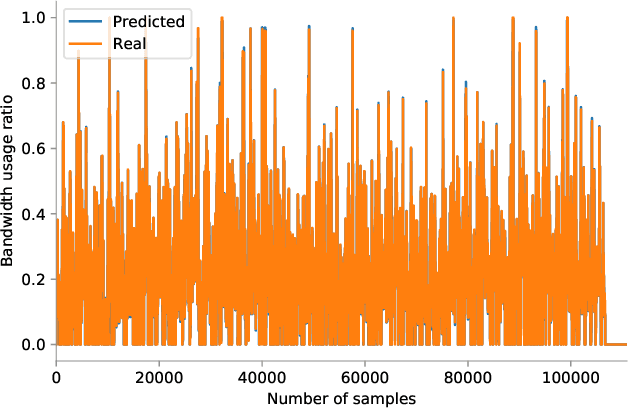
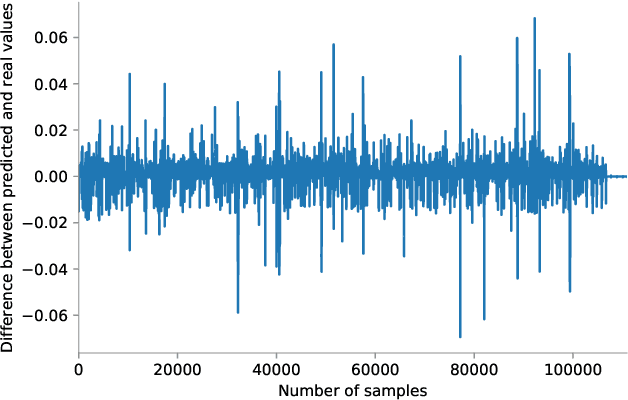
Predicting the bandwidth utilization on network links can be extremely useful for detecting congestion in order to correct them before they occur. In this paper, we present a solution to predict the bandwidth utilization between different network links with a very high accuracy. A simulated network is created to collect data related to the performance of the network links on every interface. These data are processed and expanded with feature engineering in order to create a training set. We evaluate and compare three types of machine learning algorithms, namely ARIMA (AutoRegressive Integrated Moving Average), MLP (Multi Layer Perceptron) and LSTM (Long Short-Term Memory), in order to predict the future bandwidth consumption. The LSTM outperforms ARIMA and MLP with very accurate predictions, rarely exceeding a 3\% error (40\% for ARIMA and 20\% for the MLP). We then show that the proposed solution can be used in real time with a reaction managed by a Software-Defined Networking (SDN) platform.
Toward Formal Data Set Verification for Building Effective Machine Learning Models
Aug 25, 2021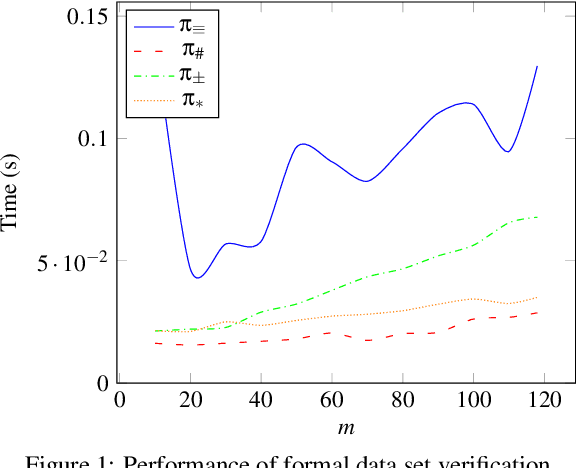
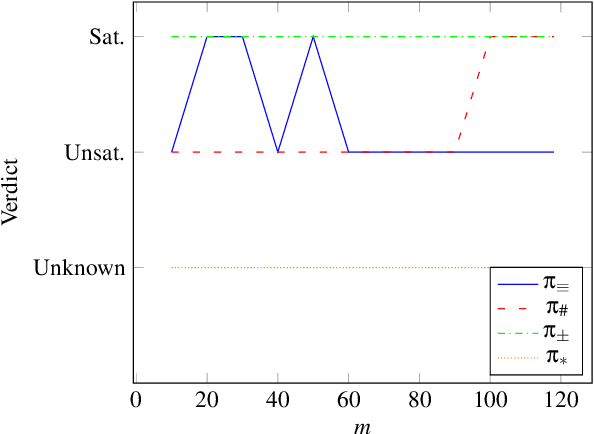
In order to properly train a machine learning model, data must be properly collected. To guarantee a proper data collection, verifying that the collected data set holds certain properties is a possible solution. For example, guaranteeing that the data set contains samples across the whole input space, or that the data set is balanced w.r.t. different classes. We present a formal approach for verifying a set of arbitrarily stated properties over a data set. The proposed approach relies on the transformation of the data set into a first order logic formula, which can be later verified w.r.t. the different properties also stated in the same logic. A prototype tool, which uses the z3 solver, has been developed; the prototype can take as an input a set of properties stated in a formal language and formally verify a given data set w.r.t. to the given set of properties. Preliminary experimental results show the feasibility and performance of the proposed approach, and furthermore the flexibility for expressing properties of interest.
Short-Term Flow-Based Bandwidth Forecasting using Machine Learning
Dec 03, 2020
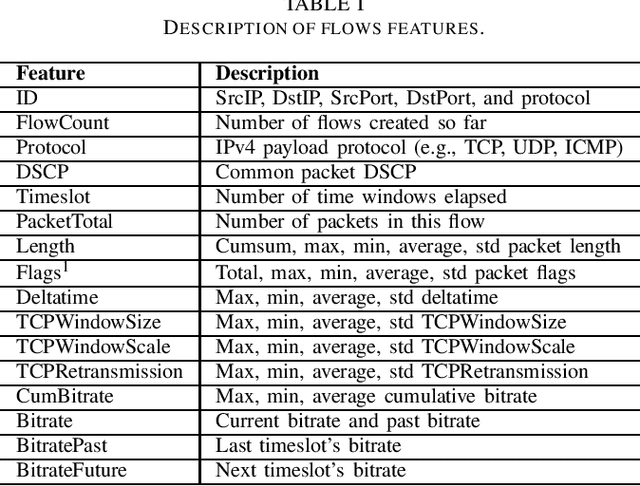
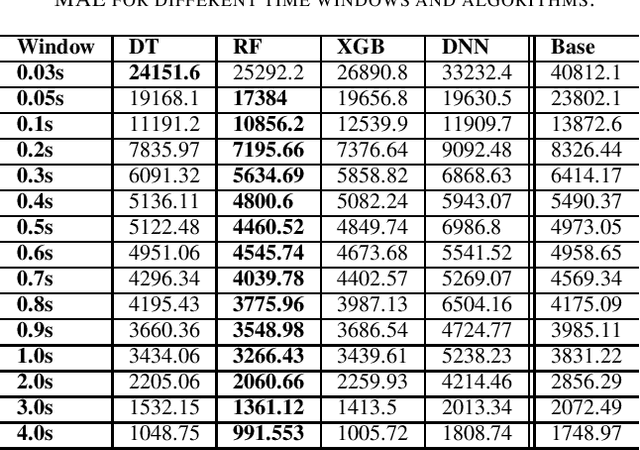
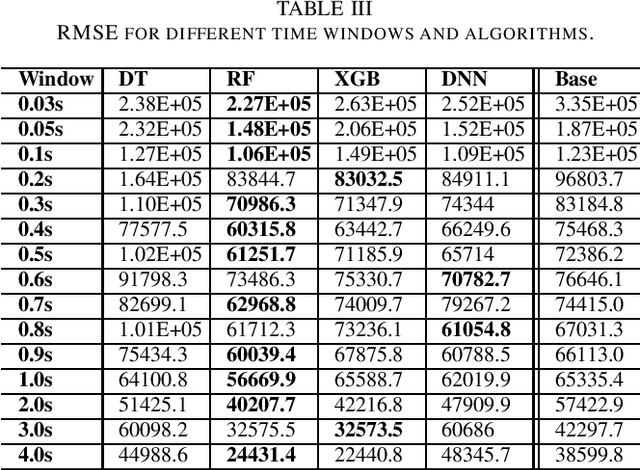
This paper proposes a novel framework to predict traffic flows' bandwidth ahead of time. Modern network management systems share a common issue: the network situation evolves between the moment the decision is made and the moment when actions (countermeasures) are applied. This framework converts packets from real-life traffic into flows containing relevant features. Machine learning models, including Decision Tree, Random Forest, XGBoost, and Deep Neural Network, are trained on these data to predict the bandwidth at the next time instance for every flow. Predictions can be fed to the management system instead of current flows bandwidth in order to take decisions on a more accurate network state. Experiments were performed on 981,774 flows and 15 different time windows (from 0.03s to 4s). They show that the Random Forest is the best performing and most reliable model, with a predictive performance consistently better than relying on the current bandwidth (+19.73% in mean absolute error and +18.00% in root mean square error). Experimental results indicate that this framework can help network management systems to take more informed decisions using a predicted network state.