 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepClean: Machine Unlearning on the Cheap by Resetting Privacy Sensitive Weights using the Fisher Diagonal
Nov 17, 2023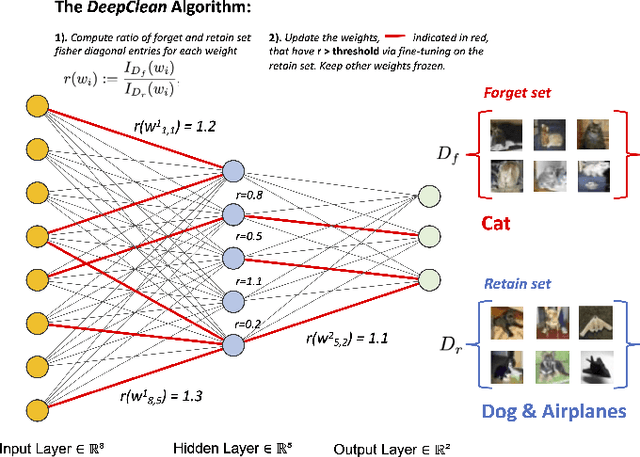
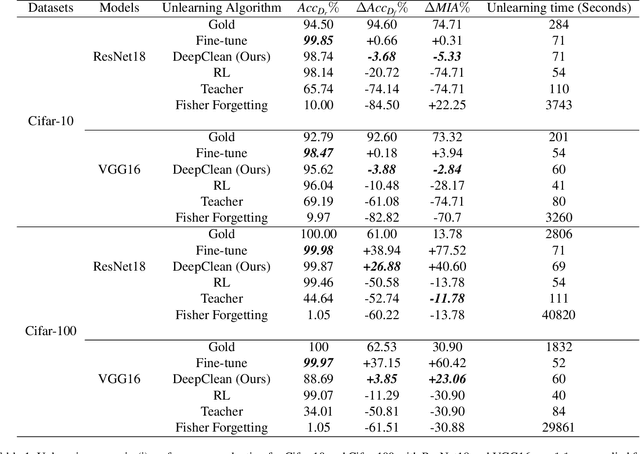
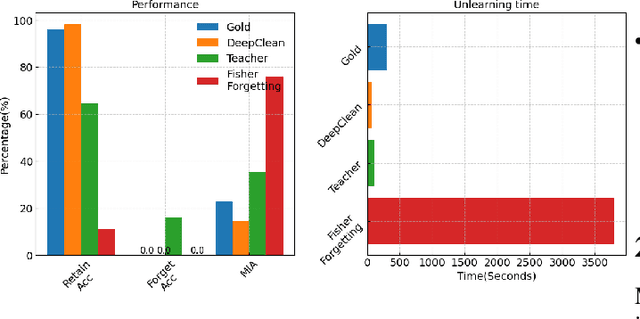
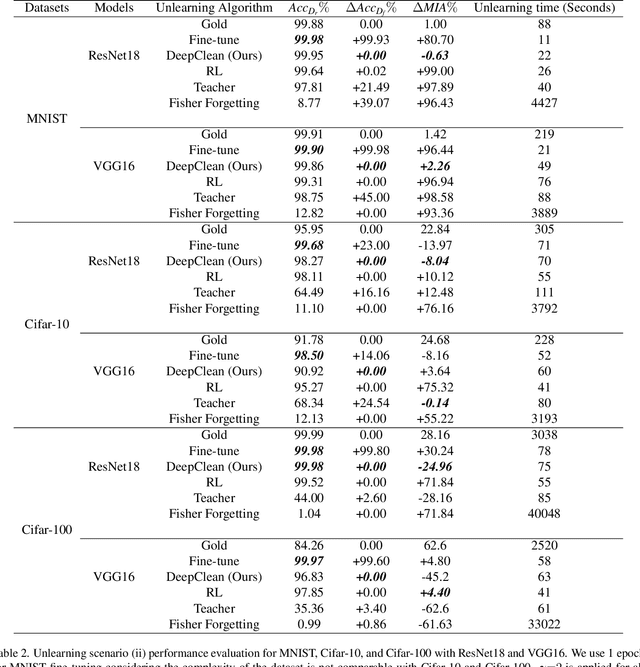
Machine learning models trained on sensitive or private data can inadvertently memorize and leak that information. Machine unlearning seeks to retroactively remove such details from model weights to protect privacy. We contribute a lightweight unlearning algorithm that leverages the Fisher Information Matrix (FIM) for selective forgetting. Prior work in this area requires full retraining or large matrix inversions, which are computationally expensive. Our key insight is that the diagonal elements of the FIM, which measure the sensitivity of log-likelihood to changes in weights, contain sufficient information for effective forgetting. Specifically, we compute the FIM diagonal over two subsets -- the data to retain and forget -- for all trainable weights. This diagonal representation approximates the complete FIM while dramatically reducing computation. We then use it to selectively update weights to maximize forgetting of the sensitive subset while minimizing impact on the retained subset. Experiments show that our algorithm can successfully forget any randomly selected subsets of training data across neural network architectures. By leveraging the FIM diagonal, our approach provides an interpretable, lightweight, and efficient solution for machine unlearning with practical privacy benefits.
An Unsupervised Method for Estimating Class Separability of Datasets with Application to LLMs Fine-Tuning
May 24, 2023
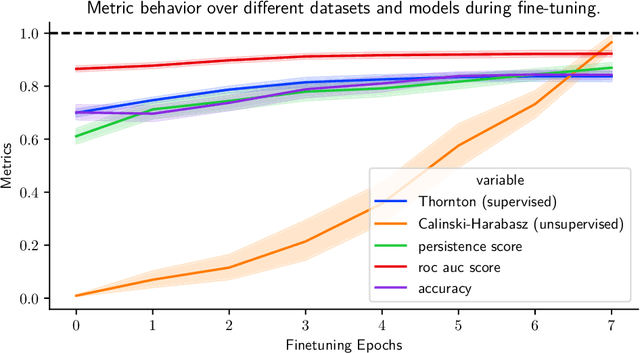


This paper proposes an unsupervised method that leverages topological characteristics of data manifolds to estimate class separability of the data without requiring labels. Experiments conducted in this paper on several datasets demonstrate a clear correlation and consistency between the class separability estimated by the proposed method with supervised metrics like Fisher Discriminant Ratio~(FDR) and cross-validation of a classifier, which both require labels. This can enable implementing learning paradigms aimed at learning from both labeled and unlabeled data, like semi-supervised and transductive learning. This would be particularly useful when we have limited labeled data and a relatively large unlabeled dataset that can be used to enhance the learning process. The proposed method is implemented for language model fine-tuning with automated stopping criterion by monitoring class separability of the embedding-space manifold in an unsupervised setting. The proposed methodology has been first validated on synthetic data, where the results show a clear consistency between class separability estimated by the proposed method and class separability computed by FDR. The method has been also implemented on both public and internal data. The results show that the proposed method can effectively aid -- without the need for labels -- a decision on when to stop or continue the fine-tuning of a language model and which fine-tuning iteration is expected to achieve a maximum classification performance through quantification of the class separability of the embedding manifold.