 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Iterative Evaluation and Enhancement of Code Quality Using GPT-4o
Feb 11, 2025



This paper introduces CodeQUEST, a novel framework leveraging Large Language Models (LLMs) to iteratively evaluate and enhance code quality across multiple dimensions, including readability, maintainability, efficiency, and security. The framework is divided into two main components: an Evaluator that assesses code quality across ten dimensions, providing both quantitative scores and qualitative summaries, and an Optimizer that iteratively improves the code based on the Evaluator's feedback. Our study demonstrates that CodeQUEST can effectively and robustly evaluate code quality, with its assessments aligning closely with established code quality metrics. Through a series of experiments using a curated dataset of Python and JavaScript examples, CodeQUEST demonstrated significant improvements in code quality, achieving a mean relative percentage improvement of 52.6%. The framework's evaluations were validated against a set of proxy metrics comprising of Pylint Score, Radon Maintainability Index, and Bandit output logs, showing a meaningful correlation. This highlights the potential of LLMs in automating code quality evaluation and improvement processes, presenting a significant advancement toward enhancing software development practices. The code implementation of the framework is available at: https://github.com/jpmorganchase/CodeQuest.
Model-Agnostic Utility-Preserving Biometric Information Anonymization
May 23, 2024The recent rapid advancements in both sensing and machine learning technologies have given rise to the universal collection and utilization of people's biometrics, such as fingerprints, voices, retina/facial scans, or gait/motion/gestures data, enabling a wide range of applications including authentication, health monitoring, or much more sophisticated analytics. While providing better user experiences and deeper business insights, the use of biometrics has raised serious privacy concerns due to their intrinsic sensitive nature and the accompanying high risk of leaking sensitive information such as identity or medical conditions. In this paper, we propose a novel modality-agnostic data transformation framework that is capable of anonymizing biometric data by suppressing its sensitive attributes and retaining features relevant to downstream machine learning-based analyses that are of research and business values. We carried out a thorough experimental evaluation using publicly available facial, voice, and motion datasets. Results show that our proposed framework can achieve a \highlight{high suppression level for sensitive information}, while at the same time retain underlying data utility such that subsequent analyses on the anonymized biometric data could still be carried out to yield satisfactory accuracy.
Using AI/ML to Find and Remediate Enterprise Secrets in Code & Document Sharing Platforms
Jan 03, 2024

We introduce a new challenge to the software development community: 1) leveraging AI to accurately detect and flag up secrets in code and on popular document sharing platforms that frequently used by developers, such as Confluence and 2) automatically remediating the detections (e.g. by suggesting password vault functionality). This is a challenging, and mostly unaddressed task. Existing methods leverage heuristics and regular expressions, that can be very noisy, and therefore increase toil on developers. The next step - modifying code itself - to automatically remediate a detection, is a complex task. We introduce two baseline AI models that have good detection performance and propose an automatic mechanism for remediating secrets found in code, opening up the study of this task to the wider community.
A Generative AI Assistant to Accelerate Cloud Migration
Jan 03, 2024We present a tool that leverages generative AI to accelerate the migration of on-premises applications to the cloud. The Cloud Migration LLM accepts input from the user specifying the parameters of their migration, and outputs a migration strategy with an architecture diagram. A user study suggests that the migration LLM can assist inexperienced users in finding the right cloud migration profile, while avoiding complexities of a manual approach.
DeepClean: Machine Unlearning on the Cheap by Resetting Privacy Sensitive Weights using the Fisher Diagonal
Nov 17, 2023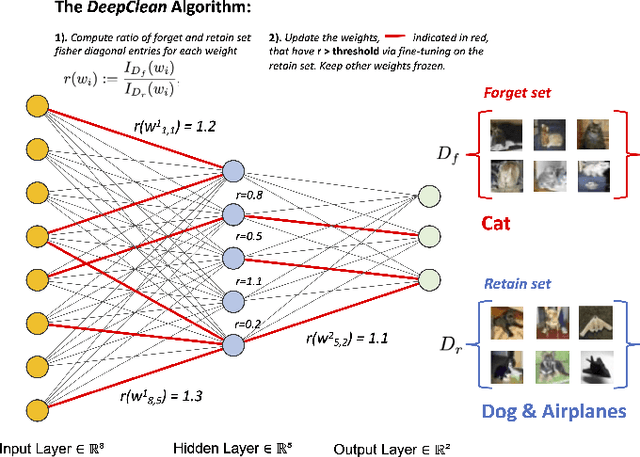
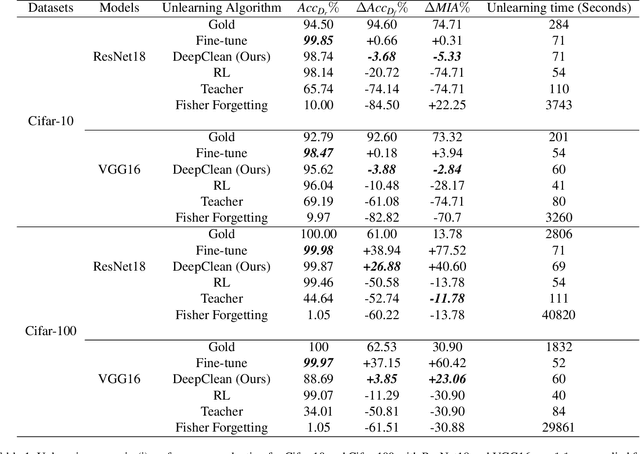
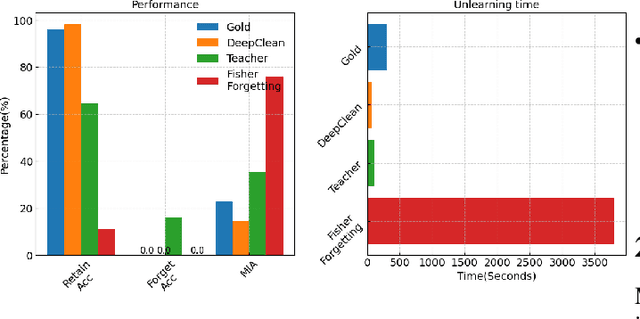
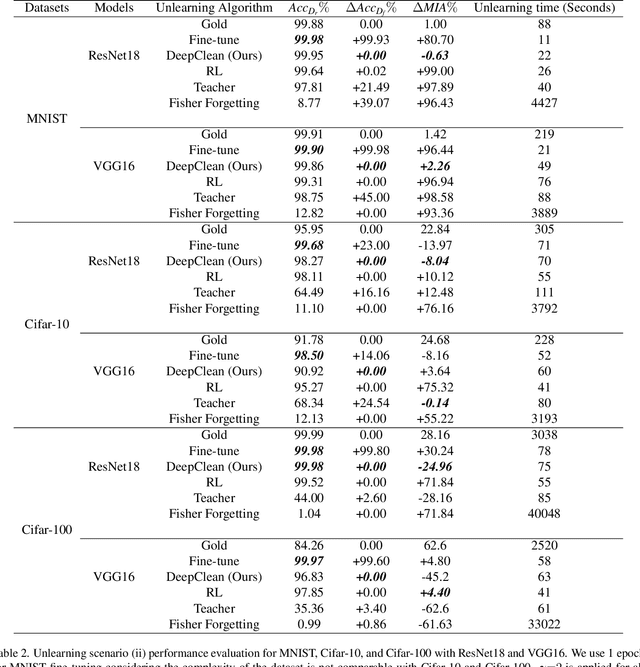
Machine learning models trained on sensitive or private data can inadvertently memorize and leak that information. Machine unlearning seeks to retroactively remove such details from model weights to protect privacy. We contribute a lightweight unlearning algorithm that leverages the Fisher Information Matrix (FIM) for selective forgetting. Prior work in this area requires full retraining or large matrix inversions, which are computationally expensive. Our key insight is that the diagonal elements of the FIM, which measure the sensitivity of log-likelihood to changes in weights, contain sufficient information for effective forgetting. Specifically, we compute the FIM diagonal over two subsets -- the data to retain and forget -- for all trainable weights. This diagonal representation approximates the complete FIM while dramatically reducing computation. We then use it to selectively update weights to maximize forgetting of the sensitive subset while minimizing impact on the retained subset. Experiments show that our algorithm can successfully forget any randomly selected subsets of training data across neural network architectures. By leveraging the FIM diagonal, our approach provides an interpretable, lightweight, and efficient solution for machine unlearning with practical privacy benefits.
An Unsupervised Method for Estimating Class Separability of Datasets with Application to LLMs Fine-Tuning
May 24, 2023
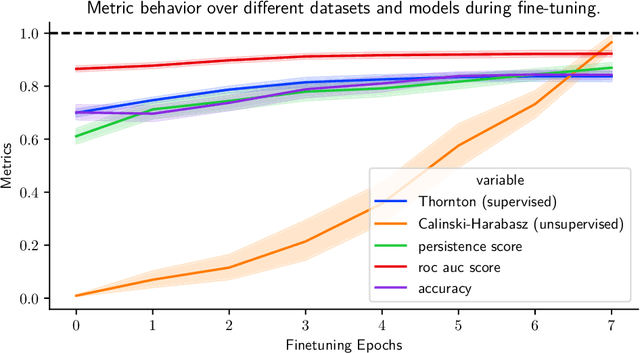


This paper proposes an unsupervised method that leverages topological characteristics of data manifolds to estimate class separability of the data without requiring labels. Experiments conducted in this paper on several datasets demonstrate a clear correlation and consistency between the class separability estimated by the proposed method with supervised metrics like Fisher Discriminant Ratio~(FDR) and cross-validation of a classifier, which both require labels. This can enable implementing learning paradigms aimed at learning from both labeled and unlabeled data, like semi-supervised and transductive learning. This would be particularly useful when we have limited labeled data and a relatively large unlabeled dataset that can be used to enhance the learning process. The proposed method is implemented for language model fine-tuning with automated stopping criterion by monitoring class separability of the embedding-space manifold in an unsupervised setting. The proposed methodology has been first validated on synthetic data, where the results show a clear consistency between class separability estimated by the proposed method and class separability computed by FDR. The method has been also implemented on both public and internal data. The results show that the proposed method can effectively aid -- without the need for labels -- a decision on when to stop or continue the fine-tuning of a language model and which fine-tuning iteration is expected to achieve a maximum classification performance through quantification of the class separability of the embedding manifold.
Spam-T5: Benchmarking Large Language Models for Few-Shot Email Spam Detection
Apr 05, 2023



This paper investigates the effectiveness of large language models (LLMs) in email spam detection by comparing prominent models from three distinct families: BERT-like, Sentence Transformers, and Seq2Seq. Additionally, we examine well-established machine learning techniques for spam detection, such as Na\"ive Bayes and LightGBM, as baseline methods. We assess the performance of these models across four public datasets, utilizing different numbers of training samples (full training set and few-shot settings). Our findings reveal that, in the majority of cases, LLMs surpass the performance of the popular baseline techniques, particularly in few-shot scenarios. This adaptability renders LLMs uniquely suited to spam detection tasks, where labeled samples are limited in number and models require frequent updates. Additionally, we introduce Spam-T5, a Flan-T5 model that has been specifically adapted and fine-tuned for the purpose of detecting email spam. Our results demonstrate that Spam-T5 surpasses baseline models and other LLMs in the majority of scenarios, particularly when there are a limited number of training samples available. Our code is publicly available at https://github.com/jpmorganchase/emailspamdetection.
A Benchmark Generative Probabilistic Model for Weak Supervised Learning
Mar 31, 2023Finding relevant and high-quality datasets to train machine learning models is a major bottleneck for practitioners. Furthermore, to address ambitious real-world use-cases there is usually the requirement that the data come labelled with high-quality annotations that can facilitate the training of a supervised model. Manually labelling data with high-quality labels is generally a time-consuming and challenging task and often this turns out to be the bottleneck in a machine learning project. Weak Supervised Learning (WSL) approaches have been developed to alleviate the annotation burden by offering an automatic way of assigning approximate labels (pseudo-labels) to unlabelled data based on heuristics, distant supervision and knowledge bases. We apply probabilistic generative latent variable models (PLVMs), trained on heuristic labelling representations of the original dataset, as an accurate, fast and cost-effective way to generate pseudo-labels. We show that the PLVMs achieve state-of-the-art performance across four datasets. For example, they achieve 22% points higher F1 score than Snorkel in the class-imbalanced Spouse dataset. PLVMs are plug-and-playable and are a drop-in replacement to existing WSL frameworks (e.g. Snorkel) or they can be used as benchmark models for more complicated algorithms, giving practitioners a compelling accuracy boost.
A New Baseline for GreenAI: Finding the Optimal Sub-Network via Layer and Channel Pruning
Feb 17, 2023The concept of Green AI has been gaining attention within the deep learning community given the recent trend of ever larger and more complex neural network models. Some large models have billions of parameters causing the training time to take up to hundreds of GPU/TPU-days. The estimated energy consumption can be comparable to the annual total energy consumption of a standard household. Existing solutions to reduce the computational burden usually involve pruning the network parameters, however, they often create extra overhead either by iterative training and fine-tuning for static pruning or repeated computation of a dynamic pruning graph. We propose a new parameter pruning strategy that finds the effective group of lightweight sub-networks that minimizes the energy cost while maintaining comparable performances to the full network on given downstream tasks. Our proposed pruning scheme is green-oriented, such that the scheme only requires one-off training to discover the optimal static sub-networks by dynamic pruning methods. The pruning scheme consists of a lightweight, differentiable, and binarized gating module and novel loss functions to uncover sub-networks with user-defined sparsity. Our method enables pruning and training simultaneously, which saves energy in both the training and inference phases and avoids extra computational overhead from gating modules at inference time. Our results on CIFAR-10 and CIFAR-100 suggest that our scheme can remove ~50% of connections in deep networks with <1% reduction in classification accuracy. Compared to other related pruning methods, our method has a lower accuracy drop for equivalent reductions in computational costs.
API-Spector: an API-to-API Specification Recommendation Engine
Dec 14, 2022When designing a new API for a large project, developers need to make smart design choices so that their code base can grow sustainably. To ensure that new API components are well designed, developers can learn from existing API components. However, the lack of standardized method for comparing API designs makes this learning process time-consuming and difficult. To address this gap we developed the API-Spector, to the best of our knowledge one of the first API-to-API specification recommendation engines. API-Spector retrieves relevant specification components written in OpenAPI (a widely adopted language used to describe web APIs). API-Spector presents several significant contributions, including: (1) novel methods of processing and extracting key information from OpenAPI specifications, (2) innovative feature extraction techniques that are optimized for the highly technical API specification domain, and (3) a novel log-linear probabilistic model that combines multiple signals to retrieve relevant and high quality OpenAPI specification components given a query specification. We evaluate API-Spector in both quantitative and qualitative tasks and achieve an overall of 91.7% recall@1 and 56.2% F1, which surpasses baseline performance by 15.4% in recall@1 and 3.2% in F1. Overall, API-Spector will allow developers to retrieve relevant OpenAPI specification components from a public or internal database in the early stages of the API development cycle, so that they can learn from existing established examples and potentially identify redundancies in their work. It provides the guidance developers need to accelerate development process and contribute thoughtfully designed APIs that promote code maintainability and quality.