 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Baseline for GreenAI: Finding the Optimal Sub-Network via Layer and Channel Pruning
Feb 17, 2023The concept of Green AI has been gaining attention within the deep learning community given the recent trend of ever larger and more complex neural network models. Some large models have billions of parameters causing the training time to take up to hundreds of GPU/TPU-days. The estimated energy consumption can be comparable to the annual total energy consumption of a standard household. Existing solutions to reduce the computational burden usually involve pruning the network parameters, however, they often create extra overhead either by iterative training and fine-tuning for static pruning or repeated computation of a dynamic pruning graph. We propose a new parameter pruning strategy that finds the effective group of lightweight sub-networks that minimizes the energy cost while maintaining comparable performances to the full network on given downstream tasks. Our proposed pruning scheme is green-oriented, such that the scheme only requires one-off training to discover the optimal static sub-networks by dynamic pruning methods. The pruning scheme consists of a lightweight, differentiable, and binarized gating module and novel loss functions to uncover sub-networks with user-defined sparsity. Our method enables pruning and training simultaneously, which saves energy in both the training and inference phases and avoids extra computational overhead from gating modules at inference time. Our results on CIFAR-10 and CIFAR-100 suggest that our scheme can remove ~50% of connections in deep networks with <1% reduction in classification accuracy. Compared to other related pruning methods, our method has a lower accuracy drop for equivalent reductions in computational costs.
CV4Code: Sourcecode Understanding via Visual Code Representations
May 11, 2022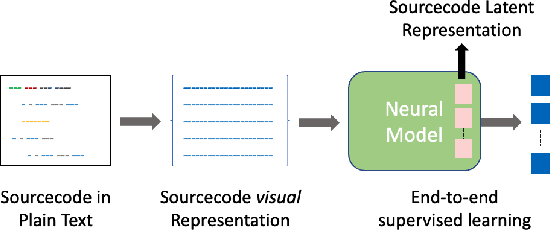
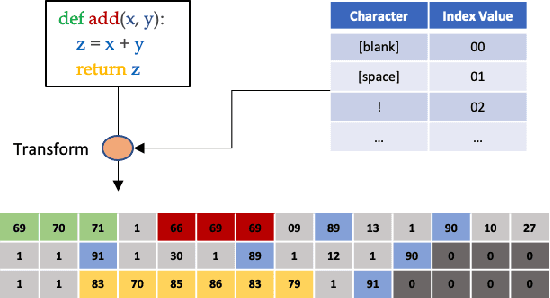

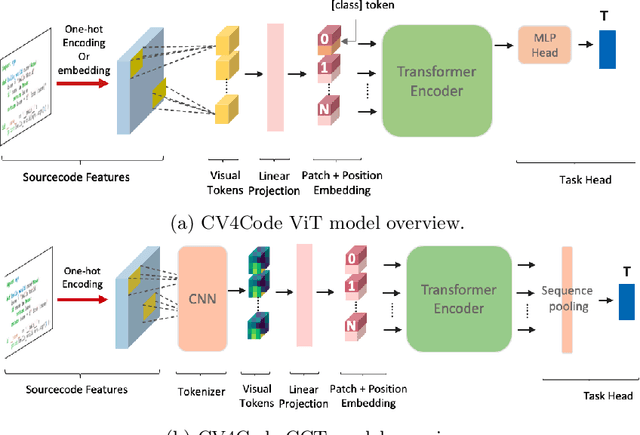
We present CV4Code, a compact and effective computer vision method for sourcecode understanding. Our method leverages the contextual and the structural information available from the code snippet by treating each snippet as a two-dimensional image, which naturally encodes the context and retains the underlying structural information through an explicit spatial representation. To codify snippets as images, we propose an ASCII codepoint-based image representation that facilitates fast generation of sourcecode images and eliminates redundancy in the encoding that would arise from an RGB pixel representation. Furthermore, as sourcecode is treated as images, neither lexical analysis (tokenisation) nor syntax tree parsing is required, which makes the proposed method agnostic to any particular programming language and lightweight from the application pipeline point of view. CV4Code can even featurise syntactically incorrect code which is not possible from methods that depend on the Abstract Syntax Tree (AST). We demonstrate the effectiveness of CV4Code by learning Convolutional and Transformer networks to predict the functional task, i.e. the problem it solves, of the source code directly from its two-dimensional representation, and using an embedding from its latent space to derive a similarity score of two code snippets in a retrieval setup. Experimental results show that our approach achieves state-of-the-art performance in comparison to other methods with the same task and data configurations. For the first time we show the benefits of treating sourcecode understanding as a form of image processing task.