 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCV4Code: Sourcecode Understanding via Visual Code Representations
May 11, 2022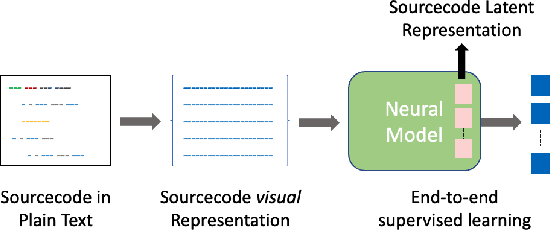
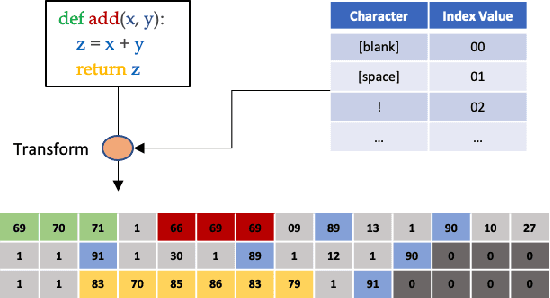

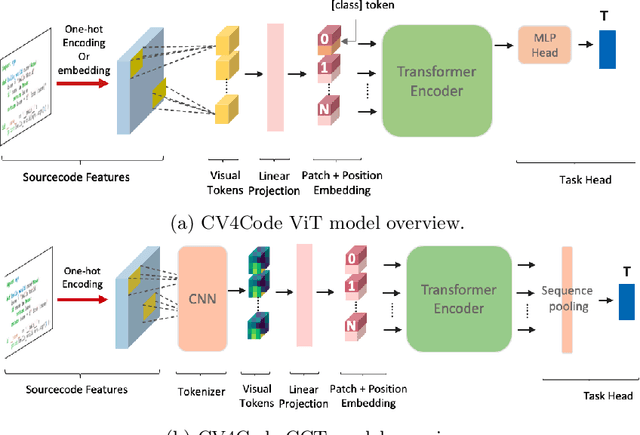
We present CV4Code, a compact and effective computer vision method for sourcecode understanding. Our method leverages the contextual and the structural information available from the code snippet by treating each snippet as a two-dimensional image, which naturally encodes the context and retains the underlying structural information through an explicit spatial representation. To codify snippets as images, we propose an ASCII codepoint-based image representation that facilitates fast generation of sourcecode images and eliminates redundancy in the encoding that would arise from an RGB pixel representation. Furthermore, as sourcecode is treated as images, neither lexical analysis (tokenisation) nor syntax tree parsing is required, which makes the proposed method agnostic to any particular programming language and lightweight from the application pipeline point of view. CV4Code can even featurise syntactically incorrect code which is not possible from methods that depend on the Abstract Syntax Tree (AST). We demonstrate the effectiveness of CV4Code by learning Convolutional and Transformer networks to predict the functional task, i.e. the problem it solves, of the source code directly from its two-dimensional representation, and using an embedding from its latent space to derive a similarity score of two code snippets in a retrieval setup. Experimental results show that our approach achieves state-of-the-art performance in comparison to other methods with the same task and data configurations. For the first time we show the benefits of treating sourcecode understanding as a form of image processing task.
Enhancing Privacy against Inversion Attacks in Federated Learning by using Mixing Gradients Strategies
Apr 26, 2022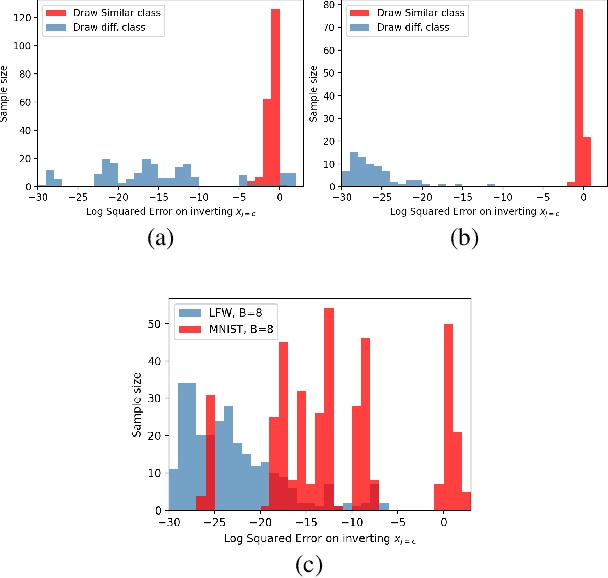

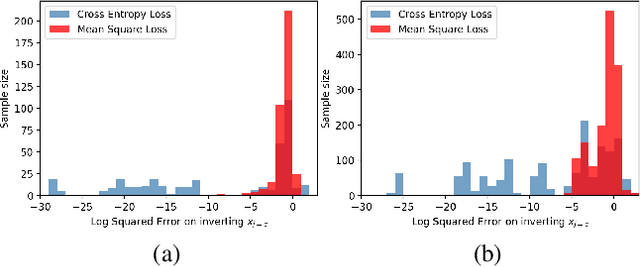
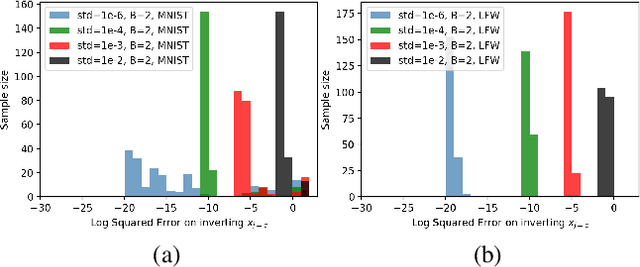
Federated learning reduces the risk of information leakage, but remains vulnerable to attacks. We investigate how several neural network design decisions can defend against gradients inversion attacks. We show that overlapping gradients provides numerical resistance to gradient inversion on the highly vulnerable dense layer. Specifically, we propose to leverage batching to maximise mixing of gradients by choosing an appropriate loss function and drawing identical labels. We show that otherwise it is possible to directly recover all vectors in a mini-batch without any numerical optimisation due to the de-mixing nature of the cross entropy loss. To accurately assess data recovery, we introduce an absolute variation distance (AVD) metric for information leakage in images, derived from total variation. In contrast to standard metrics, e.g. Mean Squared Error or Structural Similarity Index, AVD offers a continuous metric for extracting information in noisy images. Finally, our empirical results on information recovery from various inversion attacks and training performance supports our defense strategies. These strategies are also shown to be useful for deep convolutional neural networks such as LeNET for image recognition. We hope that this study will help guide the development of further strategies that achieve a trustful federation policy.