 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Numerical Gradient Inversion Attack in Variational Quantum Neural-Networks
Apr 17, 2025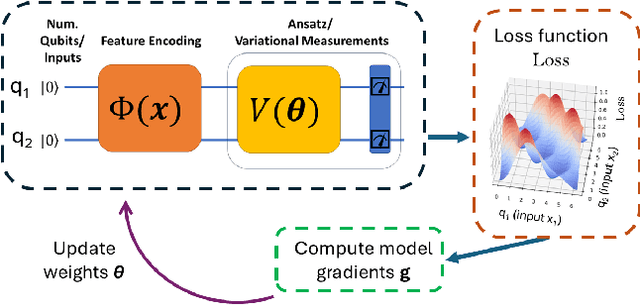
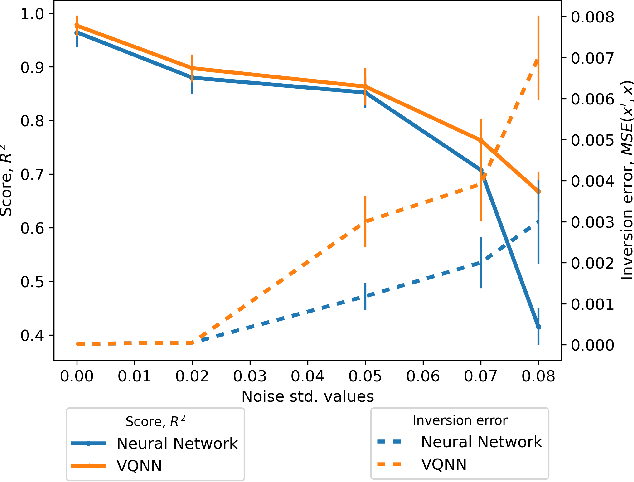
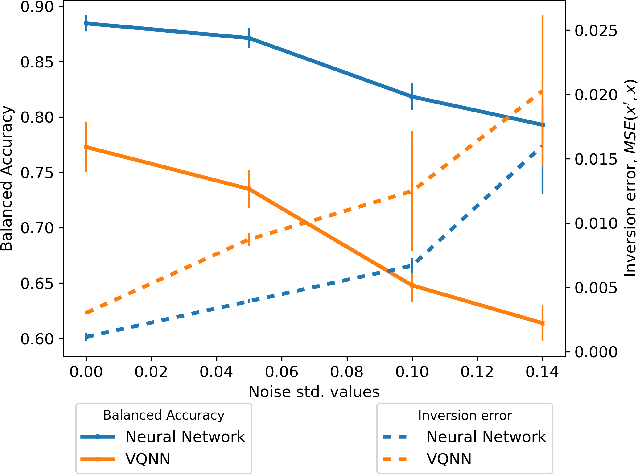
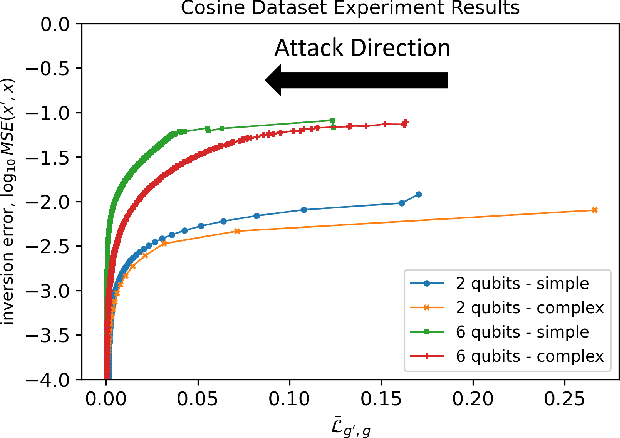
The loss landscape of Variational Quantum Neural Networks (VQNNs) is characterized by local minima that grow exponentially with increasing qubits. Because of this, it is more challenging to recover information from model gradients during training compared to classical Neural Networks (NNs). In this paper we present a numerical scheme that successfully reconstructs input training, real-world, practical data from trainable VQNNs' gradients. Our scheme is based on gradient inversion that works by combining gradients estimation with the finite difference method and adaptive low-pass filtering. The scheme is further optimized with Kalman filter to obtain efficient convergence. Our experiments show that our algorithm can invert even batch-trained data, given the VQNN model is sufficiently over-parameterized.
Expressive variational quantum circuits provide inherent privacy in federated learning
Sep 25, 2023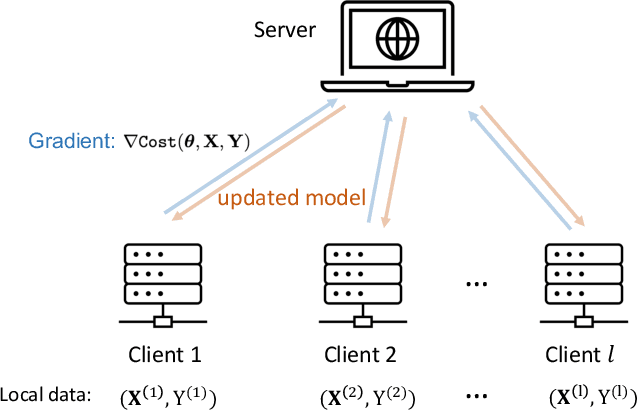
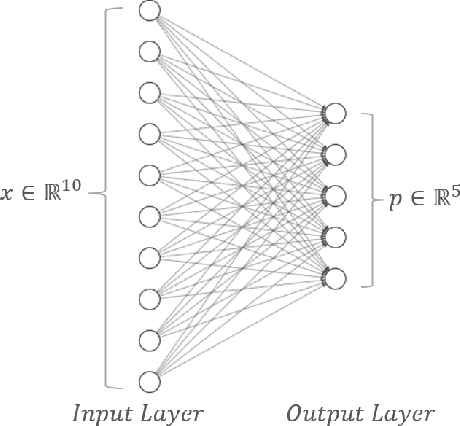
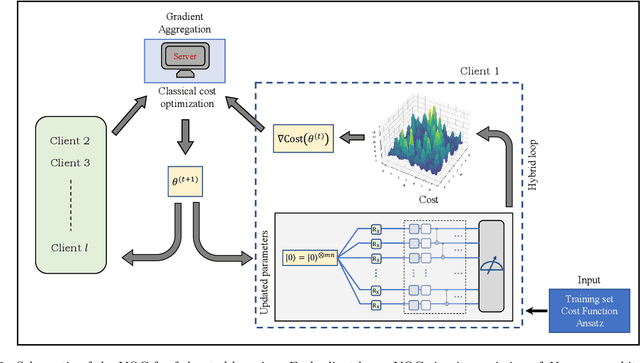
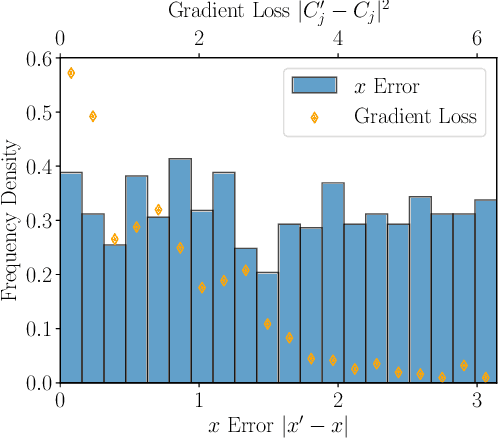
Federated learning has emerged as a viable distributed solution to train machine learning models without the actual need to share data with the central aggregator. However, standard neural network-based federated learning models have been shown to be susceptible to data leakage from the gradients shared with the server. In this work, we introduce federated learning with variational quantum circuit model built using expressive encoding maps coupled with overparameterized ans\"atze. We show that expressive maps lead to inherent privacy against gradient inversion attacks, while overparameterization ensures model trainability. Our privacy framework centers on the complexity of solving the system of high-degree multivariate Chebyshev polynomials generated by the gradients of quantum circuit. We present compelling arguments highlighting the inherent difficulty in solving these equations, both in exact and approximate scenarios. Additionally, we delve into machine learning-based attack strategies and establish a direct connection between overparameterization in the original federated learning model and underparameterization in the attack model. Furthermore, we provide numerical scaling arguments showcasing that underparameterization of the expressive map in the attack model leads to the loss landscape being swamped with exponentially many spurious local minima points, thus making it extremely hard to realize a successful attack. This provides a strong claim, for the first time, that the nature of quantum machine learning models inherently helps prevent data leakage in federated learning.
Topical: Learning Repository Embeddings from Source Code using Attention
Aug 19, 2022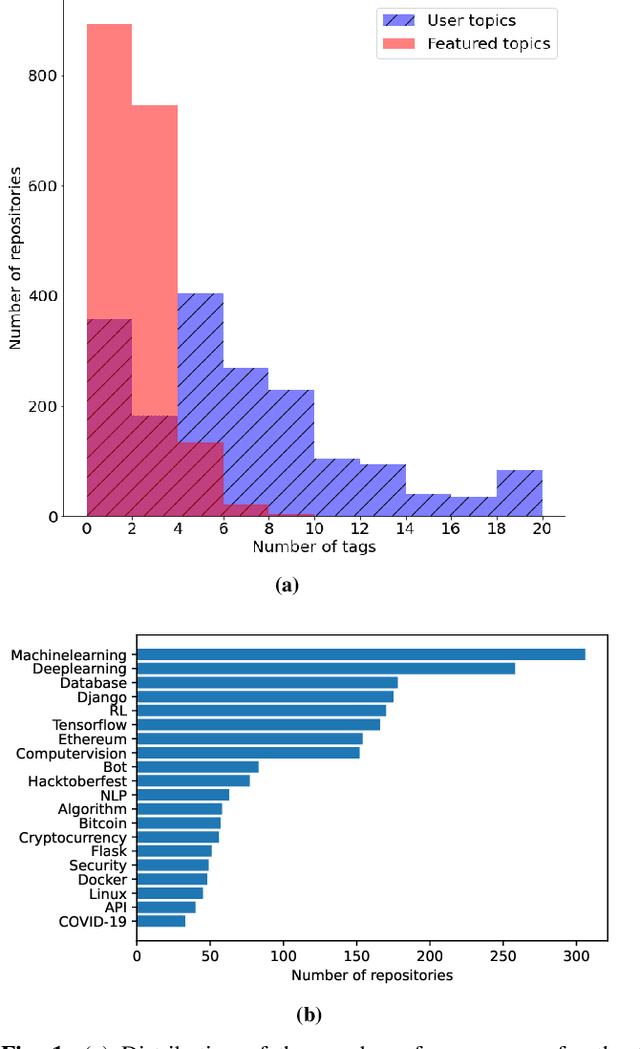
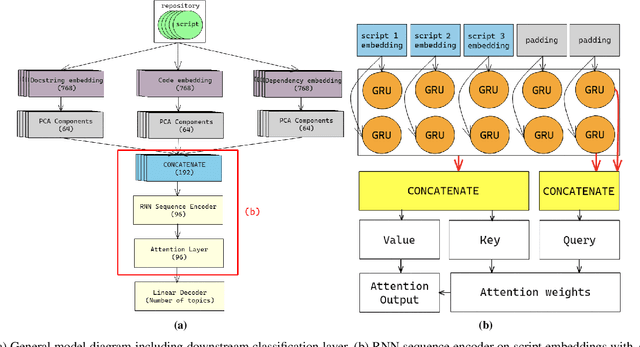

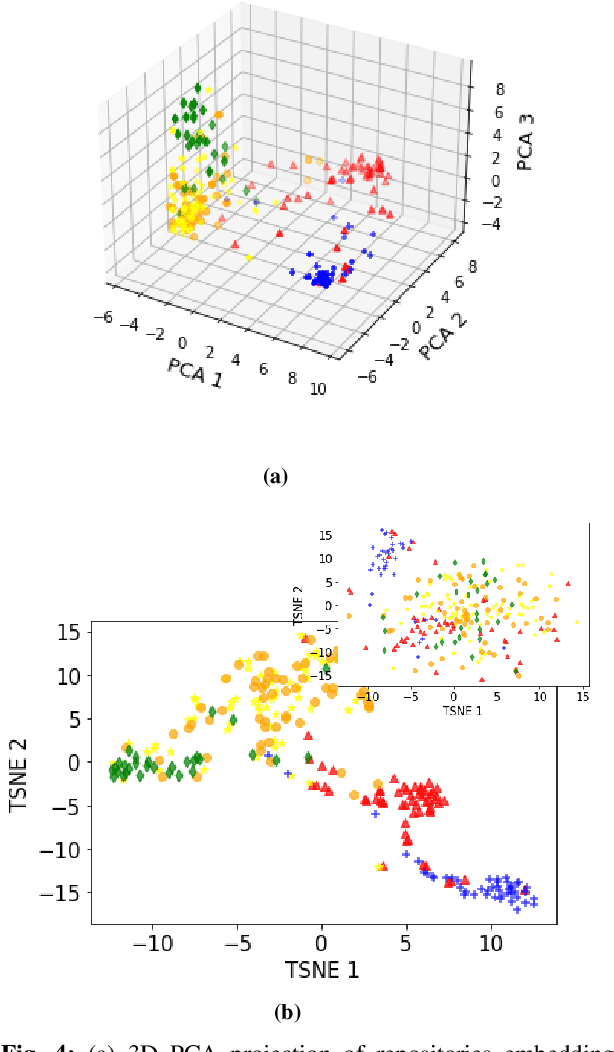
Machine learning on source code (MLOnCode) promises to transform how software is delivered. By mining the context and relationship between software artefacts, MLOnCode augments the software developers capabilities with code auto-generation, code recommendation, code auto-tagging and other data-driven enhancements. For many of these tasks a script level representation of code is sufficient, however, in many cases a repository level representation that takes into account various dependencies and repository structure is imperative, for example, auto-tagging repositories with topics or auto-documentation of repository code etc. Existing methods for computing repository level representations suffer from (a) reliance on natural language documentation of code (for example, README files) (b) naive aggregation of method/script-level representation, for example, by concatenation or averaging. This paper introduces Topical a deep neural network to generate repository level embeddings of publicly available GitHub code repositories directly from source code. Topical incorporates an attention mechanism that projects the source code, the full dependency graph and the script level textual information into a dense repository-level representation. To compute the repository-level representations, Topical is trained to predict the topics associated with a repository, on a dataset of publicly available GitHub repositories that were crawled along with their ground truth topic tags. Our experiments show that the embeddings computed by Topical are able to outperform multiple baselines, including baselines that naively combine the method-level representations through averaging or concatenation at the task of repository auto-tagging.
Enhancing Privacy against Inversion Attacks in Federated Learning by using Mixing Gradients Strategies
Apr 26, 2022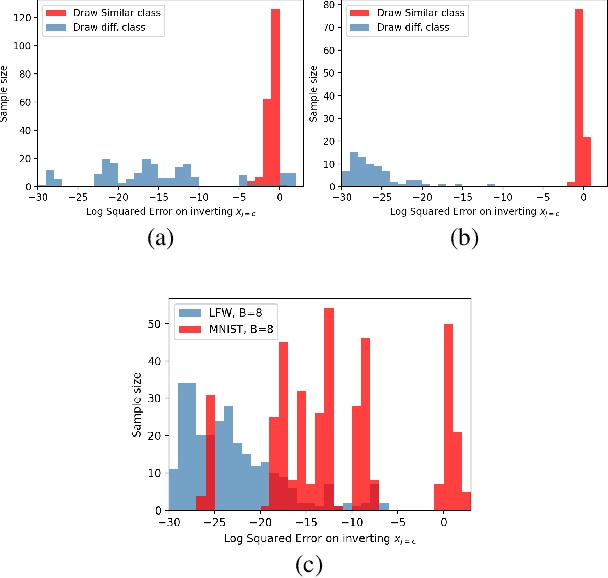

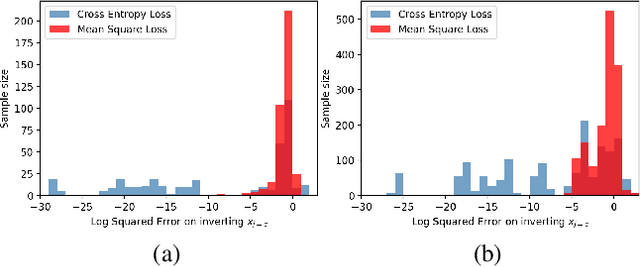
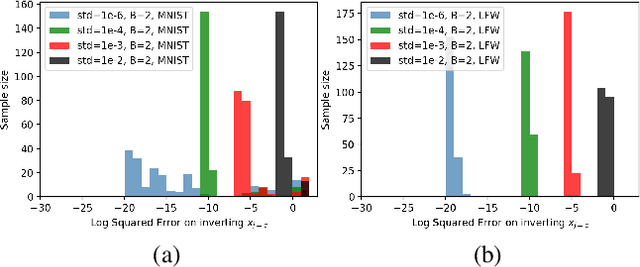
Federated learning reduces the risk of information leakage, but remains vulnerable to attacks. We investigate how several neural network design decisions can defend against gradients inversion attacks. We show that overlapping gradients provides numerical resistance to gradient inversion on the highly vulnerable dense layer. Specifically, we propose to leverage batching to maximise mixing of gradients by choosing an appropriate loss function and drawing identical labels. We show that otherwise it is possible to directly recover all vectors in a mini-batch without any numerical optimisation due to the de-mixing nature of the cross entropy loss. To accurately assess data recovery, we introduce an absolute variation distance (AVD) metric for information leakage in images, derived from total variation. In contrast to standard metrics, e.g. Mean Squared Error or Structural Similarity Index, AVD offers a continuous metric for extracting information in noisy images. Finally, our empirical results on information recovery from various inversion attacks and training performance supports our defense strategies. These strategies are also shown to be useful for deep convolutional neural networks such as LeNET for image recognition. We hope that this study will help guide the development of further strategies that achieve a trustful federation policy.