 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustry-Aligned Granular Topic Modeling
Jan 16, 2026Topic modeling has extensive applications in text mining and data analysis across various industrial sectors. Although the concept of granularity holds significant value for business applications by providing deeper insights, the capability of topic modeling methods to produce granular topics has not been thoroughly explored. In this context, this paper introduces a framework called TIDE, which primarily provides a novel granular topic modeling method based on large language models (LLMs) as a core feature, along with other useful functionalities for business applications, such as summarizing long documents, topic parenting, and distillation. Through extensive experiments on a variety of public and real-world business datasets, we demonstrate that TIDE's topic modeling approach outperforms modern topic modeling methods, and our auxiliary components provide valuable support for dealing with industrial business scenarios. The TIDE framework is currently undergoing the process of being open sourced.
Enhancing Privacy against Inversion Attacks in Federated Learning by using Mixing Gradients Strategies
Apr 26, 2022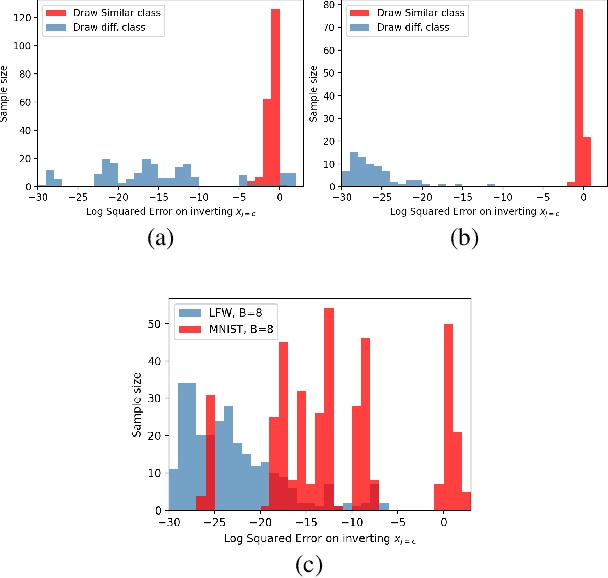

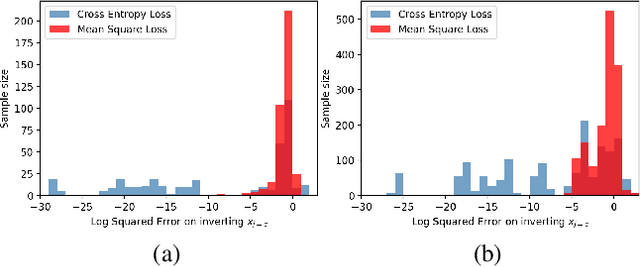
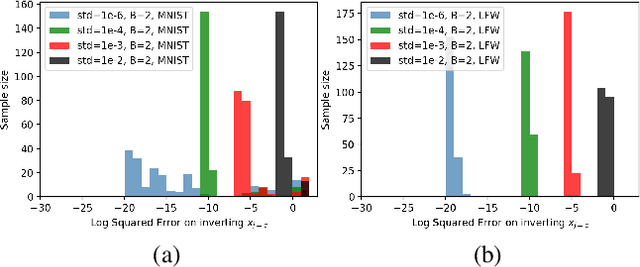
Federated learning reduces the risk of information leakage, but remains vulnerable to attacks. We investigate how several neural network design decisions can defend against gradients inversion attacks. We show that overlapping gradients provides numerical resistance to gradient inversion on the highly vulnerable dense layer. Specifically, we propose to leverage batching to maximise mixing of gradients by choosing an appropriate loss function and drawing identical labels. We show that otherwise it is possible to directly recover all vectors in a mini-batch without any numerical optimisation due to the de-mixing nature of the cross entropy loss. To accurately assess data recovery, we introduce an absolute variation distance (AVD) metric for information leakage in images, derived from total variation. In contrast to standard metrics, e.g. Mean Squared Error or Structural Similarity Index, AVD offers a continuous metric for extracting information in noisy images. Finally, our empirical results on information recovery from various inversion attacks and training performance supports our defense strategies. These strategies are also shown to be useful for deep convolutional neural networks such as LeNET for image recognition. We hope that this study will help guide the development of further strategies that achieve a trustful federation policy.
ST-FL: Style Transfer Preprocessing in Federated Learning for COVID-19 Segmentation
Mar 25, 2022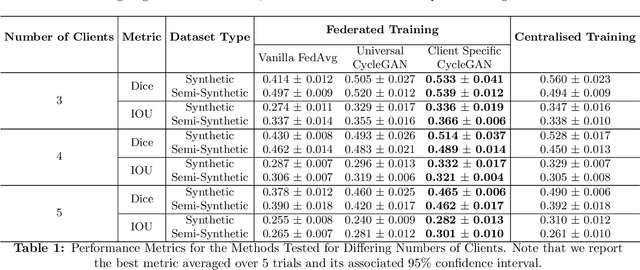
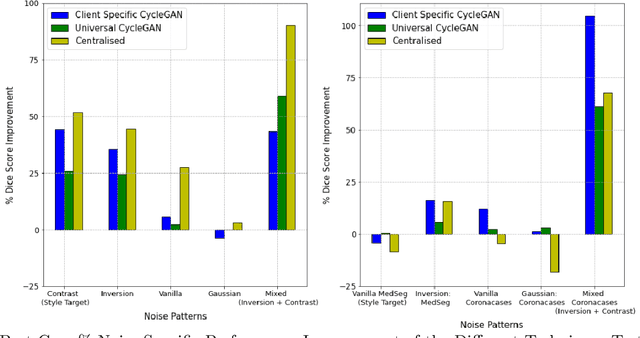
Chest Computational Tomography (CT) scans present low cost, speed and objectivity for COVID-19 diagnosis and deep learning methods have shown great promise in assisting the analysis and interpretation of these images. Most hospitals or countries can train their own models using in-house data, however empirical evidence shows that those models perform poorly when tested on new unseen cases, surfacing the need for coordinated global collaboration. Due to privacy regulations, medical data sharing between hospitals and nations is extremely difficult. We propose a GAN-augmented federated learning model, dubbed ST-FL (Style Transfer Federated Learning), for COVID-19 image segmentation. Federated learning (FL) permits a centralised model to be learned in a secure manner from heterogeneous datasets located in disparate private data silos. We demonstrate that the widely varying data quality on FL client nodes leads to a sub-optimal centralised FL model for COVID-19 chest CT image segmentation. ST-FL is a novel FL framework that is robust in the face of highly variable data quality at client nodes. The robustness is achieved by a denoising CycleGAN model at each client of the federation that maps arbitrary quality images into the same target quality, counteracting the severe data variability evident in real-world FL use-cases. Each client is provided with the target style, which is the same for all clients, and trains their own denoiser. Our qualitative and quantitative results suggest that this FL model performs comparably to, and in some cases better than, a model that has centralised access to all the training data.
DeSkew-LSH based Code-to-Code Recommendation Engine
Nov 05, 2021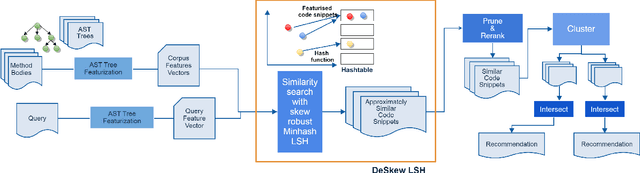
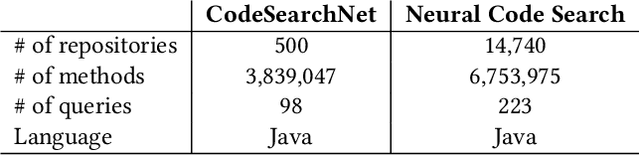

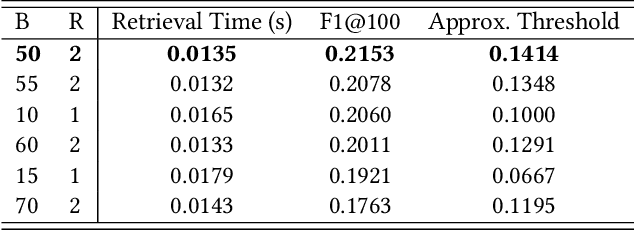
Machine learning on source code (MLOnCode) is a popular research field that has been driven by the availability of large-scale code repositories and the development of powerful probabilistic and deep learning models for mining source code. Code-to-code recommendation is a task in MLOnCode that aims to recommend relevant, diverse and concise code snippets that usefully extend the code currently being written by a developer in their development environment (IDE). Code-to-code recommendation engines hold the promise of increasing developer productivity by reducing context switching from the IDE and increasing code-reuse. Existing code-to-code recommendation engines do not scale gracefully to large codebases, exhibiting a linear growth in query time as the code repository increases in size. In addition, existing code-to-code recommendation engines fail to account for the global statistics of code repositories in the ranking function, such as the distribution of code snippet lengths, leading to sub-optimal retrieval results. We address both of these weaknesses with \emph{Senatus}, a new code-to-code recommendation engine. At the core of Senatus is \emph{De-Skew} LSH a new locality sensitive hashing (LSH) algorithm that indexes the data for fast (sub-linear time) retrieval while also counteracting the skewness in the snippet length distribution using novel abstract syntax tree-based feature scoring and selection algorithms. We evaluate Senatus via automatic evaluation and with an expert developer user study and find the recommendations to be of higher quality than competing baselines, while achieving faster search. For example, on the CodeSearchNet dataset we show that Senatus improves performance by 6.7\% F1 and query time 16x is faster compared to Facebook Aroma on the task of code-to-code recommendation.