 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCV4Code: Sourcecode Understanding via Visual Code Representations
May 11, 2022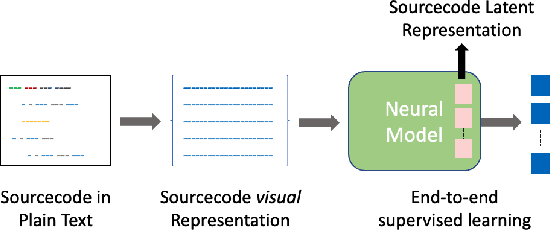
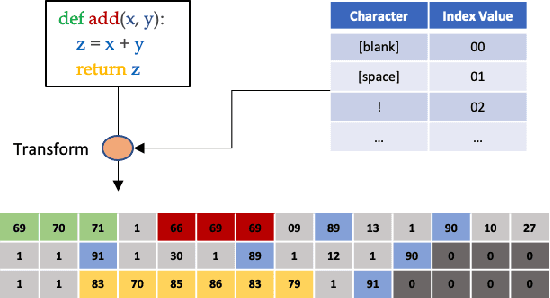

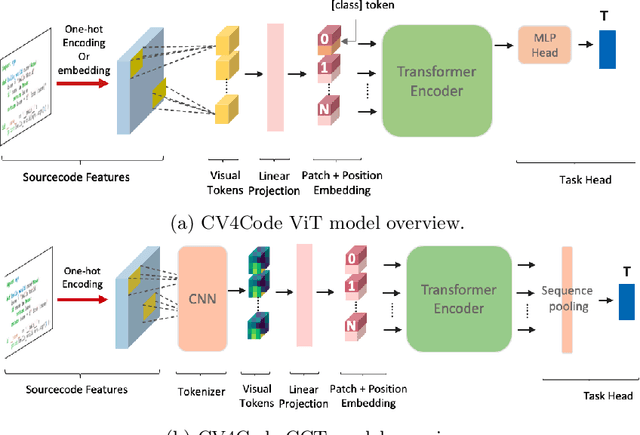
We present CV4Code, a compact and effective computer vision method for sourcecode understanding. Our method leverages the contextual and the structural information available from the code snippet by treating each snippet as a two-dimensional image, which naturally encodes the context and retains the underlying structural information through an explicit spatial representation. To codify snippets as images, we propose an ASCII codepoint-based image representation that facilitates fast generation of sourcecode images and eliminates redundancy in the encoding that would arise from an RGB pixel representation. Furthermore, as sourcecode is treated as images, neither lexical analysis (tokenisation) nor syntax tree parsing is required, which makes the proposed method agnostic to any particular programming language and lightweight from the application pipeline point of view. CV4Code can even featurise syntactically incorrect code which is not possible from methods that depend on the Abstract Syntax Tree (AST). We demonstrate the effectiveness of CV4Code by learning Convolutional and Transformer networks to predict the functional task, i.e. the problem it solves, of the source code directly from its two-dimensional representation, and using an embedding from its latent space to derive a similarity score of two code snippets in a retrieval setup. Experimental results show that our approach achieves state-of-the-art performance in comparison to other methods with the same task and data configurations. For the first time we show the benefits of treating sourcecode understanding as a form of image processing task.
DeSkew-LSH based Code-to-Code Recommendation Engine
Nov 05, 2021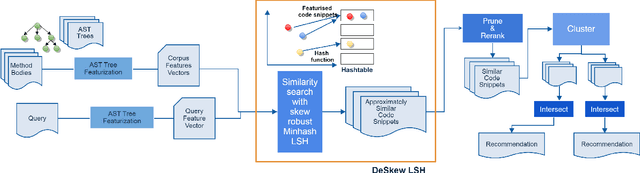
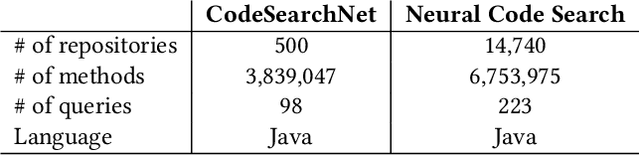

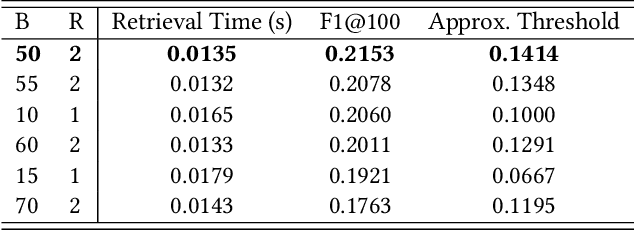
Machine learning on source code (MLOnCode) is a popular research field that has been driven by the availability of large-scale code repositories and the development of powerful probabilistic and deep learning models for mining source code. Code-to-code recommendation is a task in MLOnCode that aims to recommend relevant, diverse and concise code snippets that usefully extend the code currently being written by a developer in their development environment (IDE). Code-to-code recommendation engines hold the promise of increasing developer productivity by reducing context switching from the IDE and increasing code-reuse. Existing code-to-code recommendation engines do not scale gracefully to large codebases, exhibiting a linear growth in query time as the code repository increases in size. In addition, existing code-to-code recommendation engines fail to account for the global statistics of code repositories in the ranking function, such as the distribution of code snippet lengths, leading to sub-optimal retrieval results. We address both of these weaknesses with \emph{Senatus}, a new code-to-code recommendation engine. At the core of Senatus is \emph{De-Skew} LSH a new locality sensitive hashing (LSH) algorithm that indexes the data for fast (sub-linear time) retrieval while also counteracting the skewness in the snippet length distribution using novel abstract syntax tree-based feature scoring and selection algorithms. We evaluate Senatus via automatic evaluation and with an expert developer user study and find the recommendations to be of higher quality than competing baselines, while achieving faster search. For example, on the CodeSearchNet dataset we show that Senatus improves performance by 6.7\% F1 and query time 16x is faster compared to Facebook Aroma on the task of code-to-code recommendation.
SEERL: Sample Efficient Ensemble Reinforcement Learning
Jan 15, 2020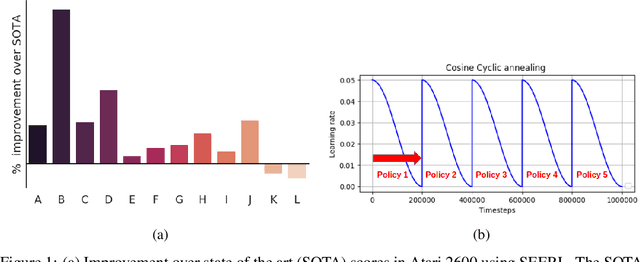
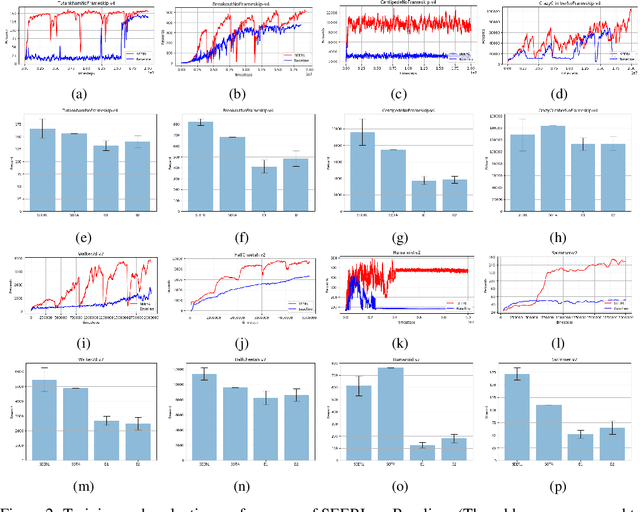
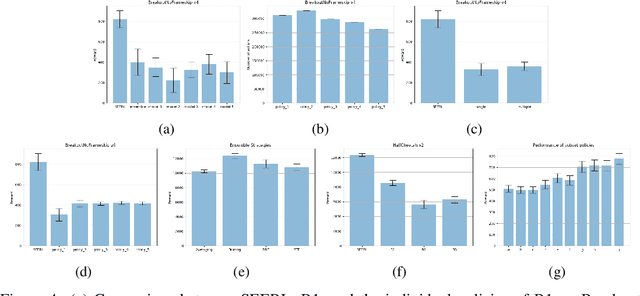
Ensemble learning is a very prevalent method employed in machine learning. The relative success of ensemble methods is attributed to its ability to tackle a wide range of instances and complex problems that require different low-level approaches. However, ensemble methods are relatively less popular in reinforcement learning owing to the high sample complexity and computational expense involved. We present a new training and evaluation framework for model-free algorithms that use ensembles of policies obtained from a single training instance. These policies are diverse in nature and are learned through directed perturbation of the model parameters at regular intervals. We show that learning an adequately diverse set of policies is required for a good ensemble while extreme diversity can prove detrimental to overall performance. We evaluate our approach to challenging discrete and continuous control tasks and also discuss various ensembling strategies. Our framework is substantially sample efficient, computationally inexpensive and is seen to outperform state of the art(SOTA) scores in Atari 2600 and Mujoco. Video results can be found at https://www.youtube.com/channel/UC95Kctu9Mp8BlFmtGD2TGTA